키워드
1. 보수적인 Q-학습 방법을 제안하여, 오프라인 강화학습에서 더 안정적이고 신뢰성 있는 성능을 보장함.
2. "Conservative Q-Learning for Offline Reinforcement Learning"
3. CQL, Conservative Q-learing, Offline RL
Conservative Q-learning
Reinforcement Learning에서 이전에 수집된 대규모 데이터셋을 효과적으로 활용하는 것은 매우 중요한 과제다. 왜냐하면 현실 문제로의 응용에 있어서 상호 작용은 비용이 많이 들고 위험할 수 있으며, 온라인으로 수집할 수 있는 데이터의 양이 매우 적을 수 있기 때문문이다.
Offline RL 알고리즘은 추가 상호 작용 없이 이전에 수집된 데이터셋을 통해 효과적으로 policy를 학습하는 방식이다. 하지만 데이터를 수집한 policy와 학습된 policy 간 distribution shift로 인해 구현의 어려움이 있다. 기존 value-based off-policy RL 알고리즘을 offline RL에서 활용하면, Out-Of-Distribution action으로 인한 bootstrapping 문제로 인해 성능이 저하된다.
Conservative Q-Learning (CQL)은 Q-function에 따른 policy의 기대 value가 실제 value의 lower-bound가 되도록 보수적으로(conservative) Q-function을 학습하여 이 문제를 해결하였다. 일반적으로 OOD action의 optimistic value function 때문에 발생하는 overestimation 문제를 conservative estimate를 학습하여 해결하는 아이디어이다. 기존 Deep Q-learning이나 actor-critic 알고리즘에 대해 간단한 Q value regularizer를 추가하여 구현 가능하며, discrete와 continuous 도메인 모두에서 기존 offline RL 방법보다 뛰어난 성능을 보인다.
Reinforcement Learning
Reinforcement Learning의 목표는 tuple (𝒮,𝒜,𝑇,𝑟,𝛾)로 정의되는 Markov Decision Process (MDP)에서 예상되는 누적 보상을 최대화하는 policy를 학습하는 것이다. 𝜋𝛽(a|s)는 behavior policy 𝒟가 데이터셋을 나타낼 때, 𝑑𝜋𝛽(s)는 𝜋𝛽(a|s)의 discounted marginal state-distribution이다. 데이터셋 𝒟는 𝑑𝜋𝛽(s)𝜋𝛽(a|s)에서 샘플링된다.
Q-learning은 Bellman optimality operator ℬ*를 iterative하게 적용하여 Q-function을 학습한다. Actor-Critic 알고리즘은 Q-function을 최대화하기 위해 별도의 policy를 학습한다. Bellman operator ℬ𝜋를 반복하여 policy evaluation을 통한 𝑄𝜋와 policy improvement를 통한 Q-value를 최대화하도록 𝜋(a|s)를 번갈아 업데이트한다. 여기서 데이터셋 𝒟가 모든 transition을 포함할 수 없기 때문에, policy evaluation 단계에서는 실제로 단일 샘플만 backup하는 empirical Bellman operator ℬ𝜋_hat을 사용한다.
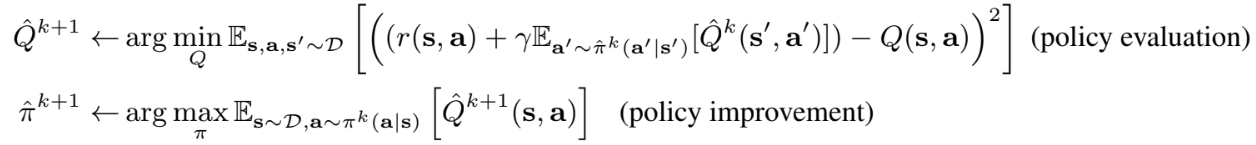
위 기본적인 수식을 기반으로 하는 offline RL 알고리즘은 action distribution shift로 인해 구현이 어렵다. 𝜋는 Q-value를 최대화하도록 훈련되었으므로, 큰 Q-value를 가지도록 잘못 학습된 OOD action으로 편향될 수 있다. 일반적으로 학습된 policy를 제한하여 이 문제를 완화하지만, 테스트 시 state distribution shift로 인해 근본적으로 해결할 수는 없다.
CQL Framework
학습된 Q-function에 기반한 policy의 기대 value가 실제 value의 lower-bound가 되게 하는 CQL 알고리즘에 대해 알아보자. Q-value의 lower-bound는 offline RL에서 OOD action 및 function approximation error로 인해 흔히 발생하는 overestimation을 방지한다. 이는 Q-learning 방법과 actor-critic 방법을 모두에서 활용될 수 있으며, off-policy policy evaluation으로 사용되거나, 완전한 offline RL 알고리즘에 통합될 수 있다.
Conservative Off-Policy Evaluation
기본적인 목표는 behavior policy 𝜋𝛽(a|s)로 생성된 데이터셋 𝒟에 대한 target policy 𝜋의 value 𝑉𝜋(s)을 추정하는 것이다. 이 과정에서 policy value의 overestimate를 방지하기 위해, 기본 Bellman error objective에 Q value를 추가로 최소화하여 conservative, lower-bound Q function을 학습한다.
이를 위해 state-action 쌍의 특정 distribution 𝜇(s,a)에서 예상되는 Q value를 최소화하도록 페널티를 추가하여 구현하였다. 기본 Q function에서 관찰되지 않는 state는 query하지 않지만 관찰되지 않은 action은 query하므로, 𝜇(s|a) = 𝑑𝜋𝛽(s)𝜇(s|a)가 되도록 제한한다.
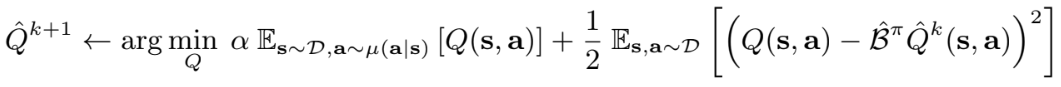
Tradeoff factor 𝛼를 통한 Q-function iteration 이 위 식이다. 최종 Q function 𝑄𝜋_hat은 모든 (s,a)에 대해 𝑄𝜋의 lower bound가 된다. 또한 𝛼가 충분히 크다면 𝑄𝜋_hat(s,a) ≤ 𝑄𝜋(s,a)이고, ℬ𝜋_hat = ℬ𝜋 일 때 양수인 모든 𝛼에 대해 𝑄𝜋_hat(s,a) ≤ 𝑄𝜋(s,a)를 보장한다. 적합한 𝛼의 경우 sampling error와 function approximate 모두 bound에 유지된다. 만약 더 많은 데이터를 사용할 수 있게 되면 이론적인 𝛼의 값은 감소하고, 이는 무한한 데이터의 한계에서 극히 작은 𝛼 값을 이용하여 하한을 구할 수 있음을 의미한다.
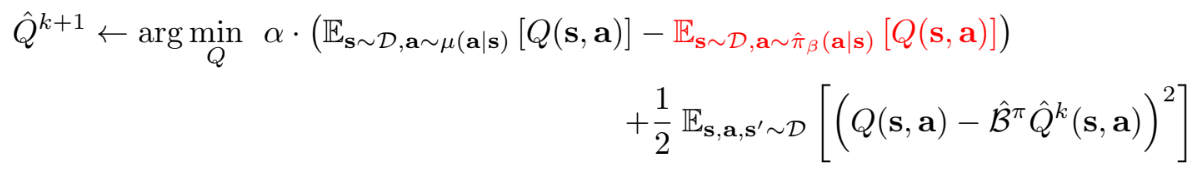
오직 𝑉𝜋(s)에만 추정하도록 하면 bound를 더욱 tight하게 할 수 있다. 이는 위와 같이 𝜋𝛽(a|s)를 따르는 추가적인 Q value maximization 항을 추가한뒤 iteration하여 구할 수 있다. 이를 통해 최종 Q-value 𝑄𝜋_hat은 point-wise lower bound가 아닐 수 있지만, 𝜇(a|s) = 𝜋(a|s)일 때 𝔼𝜋(a|s)[𝑄𝜋_hat(s,a)] ≤ 𝑉𝜋(s)가 된다.
Conservative Q-learning for Offline RL
기본 CQL 방식을 기반 offline RL 알고리즘에 대한 설명이다. 앞선 공식으로 𝜇=𝜋에서 policy 𝜋의 value에 대한 lower bound를 형성하는 Q value를 얻을 수 있다. 이를 통한 policy optimization은 각 policy iteration에 대한 full off-policy evaluation과 one step의 policy improvement를 번갈아가며 수행할 수 있다. 그러나 이는 계산 비용이 많이 들 수 있다.
이에 대한 대안으로 policy 𝜋𝑘_hat은 일반적으로 Q-function에서 파생되므로, policy를 근사하는데 𝜇(a|s)를 대신 사용하여 현재 Q-function을 최대화하는 online 알고리즘을 생성할 수 있다. 이에 아래와 같이 𝜇(a|s)에 대한 최적화 문제로 정의하여 online 알고리즘을 구현할 수 있다. 이는 CQL(ℛ)으로 표시되며 regularizer ℛ(𝜇)가 포함된다.

이를 바탕으로 두 가지 변형을 고려할 수 있다. 우선 ℛ(𝜇)를 prior distribution 𝜌(a|s)에 대한 KL-divergence로 고려하면, 𝜇(a|s) ∝ 𝜌(a|s)⋅exp(𝑄(s,a)) 라는 사실을 알 수 있다. 첫 번째 변형은, 𝜌=Unif(a)이면 위 식의 첫 번째 항은 모든 state s에서 Q value의 soft-maximum에 해당하며 다음과 같이 변형이 발생한다. 이를 CQL(ℋ)라고 한다.

다음 변형은 이전 policy로 𝜌(a|s)를 사용하는 경우, 위 수식의 첫 번째 항이 이전 policy을 통한 action의 Q-value에 대한 exponential weighted average로 대체된다. 이를 CQL(𝜌)라고 하며, 경험적으로 고차원 action space에서 더 안정적임을 발견했다.

그렇다면 이러한 방식으로 파생된 policy 업데이트가 실제로 "conservative" 할까? 위 식의 좌변은 학습된 policy가 𝑄^𝑘에 대한 soft-optimal policy와 동일한 경우, CQL 업데이트의 iter 𝑘+1에서 value 𝑉^𝑘+1에서 유도된 conservatism을 의미한다. 그러나 실제 policy는 다를 수 있으며, 우변은 이러한 차이로 인한 잠재적인 overestimate의 최대값이다. Lower bound를 얻으려면 underestimate의 양이 더 커야 하며, 이는 policy가 천천히 변경되는 𝜀이 작은 경우에 얻을 수 있다.
이를 통해 CQL Q-function 업데이트가 "gap-expanding" 임을 알 수 있다. 이는 in-distribution과 out-of-distribution의 Q value 차이가 실제 Q-function간 차이보다 더 크다는 것을 의미한다. 이는 policy 𝜋𝑘(a|s)가 데이터셋 distribution 𝜋^𝛽(a|s)에 더 가까워지도록 제한하므로, CQL 업데이트에 OOD action과 distribution shift을 암시적으로 방지할 수 있다.
최종적으로 CQL은 RL objective를 최적화하고, behavior policy에 대해 신뢰도가 높은 safe policy improvement를 수행한다. 개선 정도는 더 높은 샘플링 오류에 의해 부정적인 영향을 받으며, 더 많은 샘플이 관찰될수록 오류는 감소한다.
Algorithm

CQL을 기반으로 하여 Actor-Critic 알고리즘과 Q-learning 알고리즘 버전을 구현할 수 있다. Actor-Critic은 SAC를 기반으로 하였으며, Q-learning은 DQN을 기반으로 한다. Q function 𝑄𝜃를 학습하기 위해 CQL framework의 CQL(ℛ)(CQL(ℋ) 또는 CQL(𝜌))을 objective로 사용한다. 여기에 actor-critic 알고리즘의 경우 policy 𝜋𝜙를 추가로 학습한다.
Q function에 대한 명시적인 페널티가 존재하기 때문에, 다른 offline RL과 달리 policy constraint 조건을 사용하지 않는다. 따라서 추가적인 behavior policy estimator가 필요 없어 알고리즘이 단순화된다. 마지막으로 tradeoff factor 𝛼는 continuous control 환경에서는 Lagrangian dual gradient descent를 통해 자동으로 조정되며, discrete control에서는 특정 상수로 고정된다.
결과

OpenAI Gym 환경에서 CQL과 이전 SOTA 알고리즘과 비교하면 성능이 거의 일치하거나 약간 향상만 존재한다. 하지만 일반적으로 사용되는 여러 정책이 결합된 데이터셋에서는 CQL이 이전 방법보다 2~3배의 큰 성능 차이를 보인다.
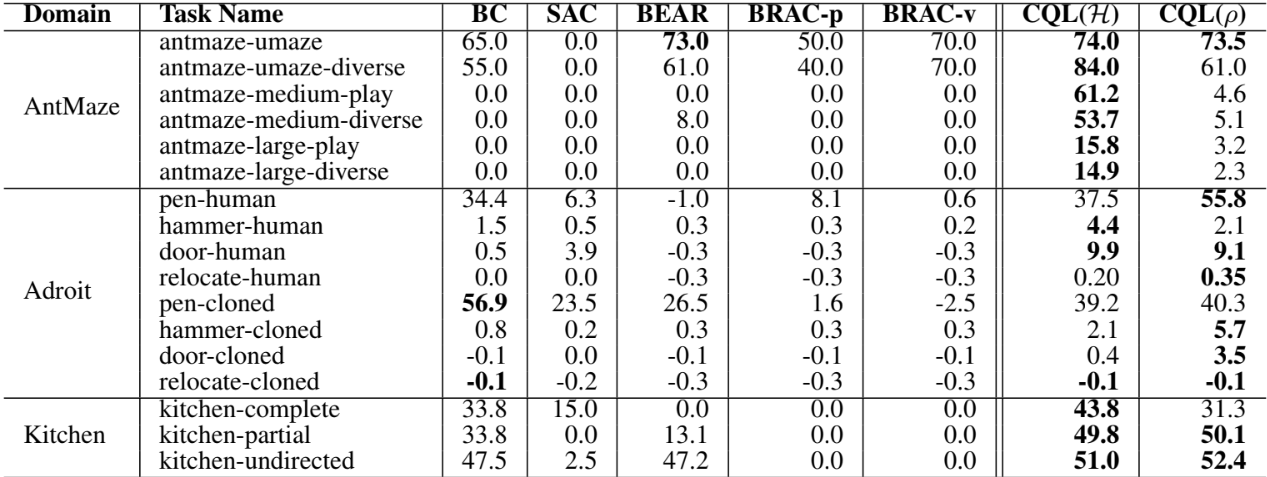
Gym 보다 더 복잡한 Adroit task는 제한된 데이터를 사용하여 24-DoF 로봇 손을 제어하여 인간의 움직임을 시연하는 문제다. 다른 offline RL은 일반적으로 의미 있는 동작을 학습하는 데 어려움을 겪으며, 가장 유의미한 결과를 보인 알고리즘은 BC이다. CQL은 BC보다 개선되었으며, 유의미한 동작을 보인 유일한 방법이다. 여기서 CQL의 두 가지 버전 모두 좋은 성능을 보이지만, 이전 policy 𝜌 를 사용하는 CQL(𝜌)이 일부 작업에서 CQL(ℋ)보다 성능이 뛰어나다. 이는 CQL(ℋ)의 더 큰 action의 차원으로 인해 더 큰 분산을 유발하기 때문이다.
추가적으로 AntMaze 환경에서 다른 알고리즘은 단순한 U-미로에서만 어느 정도 진전을 이루었지만, CQL만이 훨씬 더 어려운 중형 및 대형 미로에서 의미 있는 진전을 보였다. 그리고 Kitchen 환경은 9-DoF 로봇을 제어하여 여러 물체를 순차적으로 조작하는 task이며, 목표를 달성하는 경우 sparse한 완료 보상을 제공한다. CQL은 이 환경에서 이전 방법보다 성능이 뛰어나며, BC보다 성능이 뛰어난 유일한 방법입니다.
Atari offline RL

Atari 환경에서 아래 두 가지 유형의 데이터셋을 통한 offline RL을 평가하였다.
- Online DQN 에이전트가 관찰한 샘플 중 첫 20%로 구성된 데이터셋
- Online DQN 에이전트가 관찰한 모든 샘플의 1% 혹은 10%로 구성된 데이터셋
첫 번째 데이터셋에서 CQL은 일반적으로 QR-DQN, REM과 유사하거나 더 나은 성능을 달성한다. 하지만 두 번째 데이터셋에 대해 CQL은 특히 더 어려운 1% 데이터셋에서 QR-DQN, REM보다 훨씬 뛰어난 성능을 보인다.

Analysis of CQL

CQL이 실제로 value function의 lower bound를 지정하는지 확인하기 위한 평가 결과다. 이를 위해 CQL이 예측한 학습된 policy의 평균 value 𝔼[𝑉𝑘_hat(s)]를 추정하고, policy 𝜋𝑘의 실제 보상과 차이를 비교했다. 결과를 통해 CQL이 모든 세 가지 task에 대해 lower bound를 학습하는 반면, 다른 모델은 overestimate되는 경향이 있다는 것을 알 수 있다. 또한 기본 Eqn.1 식이 CQL(ℋ)에 비해 더 낮다는 것을 관찰할 수 있다. 이는 CQL(ℋ)가 방정식의 point-wise bound보다 더 tight한 lower bound를 가진다는 것을 의미한다.
Reference
논문 링크 : https://arxiv.org/abs/2006.04779
'딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| [RL] Reward is Enough (0) | 2025.02.19 |
|---|---|
| [RL] TD3 + Behavior Cloning (0) | 2025.02.12 |
| [RL] R2D2 (0) | 2025.01.29 |
| [RL] IMPALA (0) | 2025.01.22 |
| [RL] Large-scale Curiosity-driven Learning (0) | 2025.01.15 |