키워드
1. 분산 학습 환경에서 효율적으로 작동하는 Actor-Learner 구조를 제안하여, 대규모 강화학습 문제에서의 성능을 크게 향상시킴.
2. "IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures"
3. IMPALA, Importance weighted, Actor-Learner, distributed Agent, V-trace
Multi tasks
지금까지 강화 학습의 발전은 에이전트가 각 작업에 대해 개별적으로 교육을 받는 single task 영역에서 진전이 있었다. 반면 똑같은 단일 파라미터 세트의 단일 강화 학습 에이전트를 사용하여 multi task를 해결하는 에이전트에 대한 구현을 고려하였다. 이를 위한 효과적인 알고리즘은 multi task로 인해 증가된 데이터와 늘어난 훈련 시간을 효율적으로 처리해야한다. 즉 단일 학습보다 리소스를 보다 효율적으로 사용할 뿐만 아니라, 데이터 효율성이나 리소스 활용도를 희생하지 않고 수천 대의 machine으로 확장할 수도 있다.
IMPALA (Importance Weighted Actor-Learner Architecture)는 이를 구현한 새로운 distributed 에이전트이다. V-trace라는 새로운 off-policy correction 방법으로 분리된 acting과 learning을 결합하여 높은 처리량과 안정적인 학습을 달성했다. 이를 바탕으로 훈련 안정성이나 데이터 효율성을 희생하지 않고도 수천 대의 machine으로 확장 가능하며, 더 적은 데이터로 이전 에이전트보다 더 나은 성능을 달성한다.

Actor가 중앙 파라미터 서버에 policy 파라미터에 대한 기울기를 전달하는 A3C 기반 에이전트와 달리, IMPALA의 actor는 experience trajectory를 centralised learner에게 전달한다. 이를 통해 learner는 전체 experience trajectory에 접근할 수 있으므로, GPU를 사용하여 trajectory의 미니 배치에 대한 업데이트를 병렬적이면서, 동시에 독립적으로 수행할 수 있다.
다만 trajectory을 생성하는 데 사용된 policy는 업데이트가 진행되면서 learner의 policy보다 뒤처지게 된다. 즉 off-policy 방식으로 학습되게 되는데, V-trace는 off-policy actor-critic의 이러한 해로운 불일치를 보완해준다. 이러한 점을 바탕으로 single-machine A3C보다 30배 이상 빠르며, 추가로 하이퍼파라미터 값과 네트워크 아키텍처에 더 robust 하여 더 깊은 neural network를 더 잘 활용할 수 있다.
GPU를 활용한 강화학습의 확장은 여러 방식이 있었다. 가장 간단한 방법 중 하나는 batched A2C이다. 이는 모든 step에서 batch of action을 생성하고 이를 batch of environment에 적용한다. 따라서 batch 중 가장 느린 환경에 따라 전체 batch step을 수행하는 데 걸리는 시간이 결정된다. 즉, 환경의 속도 변화가 크면 성능이 심각하게 제한된다.
IMPALA와 가장 유사한 아키텍처는 GA3C를 들 수 있다. GPU를 보다 효과적으로 활용하기 위해 비동기 (asynchronous) 데이터 수집을 사용한 구조다. Dynamic batching을 사용하여 gradient calculation/backward pass에서 acting/forward pass를 분리하였으나, 이러한 asynchrony는 학습 중에 불안정성을 초래한다. 이를 policy gradient를 추정하는 동안 action probabilities에 작은 상수를 추가하여 부분적으로 완화하였으나, 이와 대조적으로 IMPALA는 보다 원칙적인 V-trace 알고리즘을 사용했다.
Retrace 알고리즘은 V-trace와 유사하다. 이는 multi-step RL에 대한 off-policy correction을 도입하였다. Retrace는 이를 수행하기 위해 state-action-value function 𝑄를 학습하였다. 반면 A3C와 같은 많은 actor-critic 방법은 𝑄 대신 state-value function 𝑉를 학습하며, V-trace 또한 이 방식을 따른다.
IMPALA
IMPALA는 actor-critic 설정을 사용하여 policy 𝜋과 baseline function 𝑉𝜋을 학습한다. Experience의 생성은 𝜋와 𝑉𝜋의 학습과 분리된다. 이를 통해 전체 아키텍처는 experience의 trajectory을 반복적으로 생성하는 복수의 actor와 actor로부터 전송된 experience을 사용하여 off-policy 𝜋을 학습하는 복수의 learner로 구성된다.
각 trajectory가 시작될 때, actor는 자신의 local policy 𝜇을 learner 최신 policy 𝜋로 업데이트하고 해당 환경에서 𝑛단계 동안 이를 실행한다. 𝑛 단계 후에 actor는 해당 policy distribution 𝜇(𝑎𝑡|𝑥𝑡)와 함께 (𝑥, 𝑎, 𝑟)로 구성된 trajectory를 전달한다. Learner는 여러 actor로부터 수집된 여러 trajectory에 대해 policy 𝜋를 지속적으로 업데이트한다. 이 간단한 아키텍처를 통해 learner는 GPU를 사용하여 가속화되고, actor는 여러 시스템에 쉽게 분산될 수 있다.
그러나 leaner policy 𝜋는 업데이트 시점에 actor policy 𝜇보다 잠재적으로 업데이트가 앞서고 있을 수 있다. 즉 actor와 learner 사이에 policy-lag가 발생하게 되는데, V-trace는 이러한 lag을 수정하여 데이터 효율성을 유지하면서 매우 높은 데이터 처리량을 달성하게 해준다.
IMPALA의 learner는 전체 trajectory batch에 대해 업데이트를 수행하므로, A3C와 같은 온라인 에이전트보다 더 많은 계산을 병렬화할 수 있다. 예를 들어, 일반적인 CNN의 경우 시간 차원을 배치 차원으로 접어 모든 입력을 병렬로 계산할 수 있으며, LSTM의 경우 state가 계산되면 출력 레이어를 모든 time step에 병렬로 적용할 수 있다. 이를 통해 유효 배치 크기가 수천 개로 늘어나는 효과가 있다.
V-trace
Decoupled distributed actor-critic 아키텍처에서 actor가 action을 생성하는 시점과 learner가 gradient를 추정하는 시점 사이의 lag으로 인해 off-policy 학습이 핵심 요소이다. 이를 위해 V-trace라고 불리는 새로운 off-policy actor-critic 알고리즘을 고안하였다.
MDP(Markov Decision Process)에서 discounted infinite-horizon RL 문제를 고려할 때, 목표는 누적 discounted reward의 기대값를 최대화하는 policy 𝜋을 찾는 것이다. 또한 off-policy RL 알고리즘은 behavior policy 𝜇에 의해 생성된 trajectory을 사용하며, 이와 다른 target policy 𝜋의 value function 𝑉𝜋를 학습한다.
V-trace target
Behavior policy 𝜇에 따라 actor가 생성한 trajectory (𝑥𝑡,𝑎𝑡,𝑟𝑡)을 고려해보자. t는 s부터 s+n까지 이다. State 𝑥𝑠의 value approximation인 𝑉(𝑥𝑠)로 𝑛-step V-trace의 target을 다음과 같이 정의할 수 있다.
𝛿𝑡𝑉는 𝑉의 시간에 따른 차이를 의미하며, 𝜌𝑡와 𝑐𝑖는 truncated importance sampling(IS) weights를 의미한다. 여기서 truncation level이 𝜌̅≥𝑐̅ 라고 가정한다.
On-policy(𝜋=𝜇일 때)에서 𝑐̅≥1이라고 가정하면, 항상 𝑐𝑖=1, 𝜌𝑡=1가 되기 때문에 위와 같이 다시 정리 할 수 있다. 이를 on-policy 𝑛-steps Bellman target이라 하며, V-trace가 on-policy를 따르게 되면 이 target으로 축소되게 된다. Retrace 알고리즘과 달리 이러한 속성은 on-, off- 구분 없이 동일하게 사용할 수 있다.
IS 가중치 𝑐𝑖, 𝜌𝑡가 다른 역할을 한다는 점에 유의해야한다. 𝜌̅는 수렴하는 value function의 특성에 영향을 미치는 반면, 𝑐̅는 이 함수가 수렴하는 속도에 영향을 미친다.
𝜌𝑡는 𝛿𝑡𝑉의 정의에 나타나며, 업데이트 규칙의 fixed point를 정의한다. 이를 통해 𝜌𝑡가 truncate 되지 않는, 𝜌̅가 무한할 때는 단순하게 target policy의 value function 𝑉𝜋가 된다. 그러나 𝜌̅ 가 무한하지 않으면, fixed point는 𝜇과 𝜋 사이에 있는 policy 𝜋𝜌̄를 따르는 value function 𝑉𝜋𝜌̄가 되며, 𝜌̅가 0이라면 behavior policy의 value function 𝑉𝜇를 얻는다.
다른 가중치 𝑐𝑖는 Retrace의 "trace cutting" coefficient와 유사하다. 이는 time 𝑡에 관찰된 𝛿𝑡𝑉가 이전 시간 𝑠의 value function 업데이트에 얼마나 영향을 미치는지 측정하며, 𝜋과 𝜇의 차이가 클수록 이 값은 더 커진다. 이에 대한 분산 감소 기법으로 truncated level 𝑐̅을 사용한다. 다만 이는 수렴하고자 하는 솔루션에는 영향을 미치지 않는다.
최종적으로 V-trace target은 재귀적(recursively)으로 계산될 수 있다.
Policy Gradient
On-policy를 따르는 경우, behavior policy 𝜇의 파라미터에 대한 value function 𝑉𝜇(𝑥0)의 기울기는 위와 같다. 𝑄𝜇(𝑥𝑠,𝑎𝑠)는 (𝑥𝑠,𝑎𝑠)에서 policy 𝜇의 state-action value이다. 이는 일반적으로 stochastic gradient ascent를 통해 policy 파라미터를 update하게 되는데, 𝑞𝑠은 𝑄𝜇(𝑥𝑠,𝑎𝑠)의 추정치로 behavior policy 𝜇에 따라 방문하는 state 𝑥𝑠의 집합에 대한 평균이 사용된다.
Off-policy를 바탕으로 할때는, 위처럼 evaluated policy 𝜋𝜌̄과 behavior policy 𝜇 사이에 IS 가중치를 사용하여 policy 파라미터를 업데이트한다. 𝑞𝑠는 다음 state 𝑥𝑠+1의 V-trace 추정치 𝑣𝑠+1를 사용한 𝑄𝜋𝜌̄(𝑥𝑠,𝑎𝑠)의 추정치이다. Q-value 𝑄𝜋𝜌̄(𝑥𝑠,𝑎𝑠)의 target으 𝑣𝑠 대신 𝑞𝑠를 사용하는 이유는, 𝑉=𝑉𝜋𝜌̄ 로 value estimation이 모든 state에서 정확하다고 가정하면, 𝔼[ 𝑞𝑠|𝑥𝑠,𝑎𝑠]=𝑄𝜋𝜌̄(𝑥𝑠,𝑎𝑠) 가 되기 때문이다. 추가적으로 policy gradient estimate의 분산을 줄이기 위해, 일반적으로 현재 value estimation 𝑉(𝑥𝑠)와 같은 state-dependent baseline을 𝑞𝑠에서 뺄 수 있다.
최종적으로 truncated level 𝜌̅을 사용하면, V-trace 알고리즘에 의해 evaluate되는 policy 𝜋𝜌̅에 대한 policy gradient를 추정하게 된다. 또한 𝜌̅이 충분히 큰 경우처럼 𝑉𝜋𝜌̅−𝑉𝜋이 작다고 가정하면, 𝑞𝑠가 𝑄𝜋(𝑥𝑠,𝑎𝑠)의 좋은 추정치를 제공할 것으로 기대할 수 있다.
V-trace Actor-Critic Algorithm
Value function의 파라미터를 𝑉𝜃, 현재 policy 𝜋𝜔 로 표현한다. Trajectory는 behavior policy 𝜇에 따라 actor에 의해 생성되며, V-trace target으로 𝑣𝑠를 활용한다. 이를 바탕으로 time 𝑠에서 (1) value 파라미터 𝜃는 target 𝑣𝑠에 대한 𝑙2 loss를 통한 SGD로 업데이트된다. 또한 (2) policy 파라미터 𝜔도 policy gradient 방향으로 업데이트하며, (3) 조기 수렴을 방지하기 위해 A3C와 같이 방향에 따라 entropy 보너스를 추가할 수 있다. 전체 업데이트는 적절한 계수 통하여 세 가지 기울기를 적절히 합산한다.

Architecture
이를 바탕으로 실험에서 두 가지 아키텍처가 사용되었다. Policy와 value앞에 공통적으로 LSTM을 사용하지만, 한 모델에서만 residual 구조를 사용하였다. 추가적으로 언어에 대한 task가 있는 경우 텍스트 임베딩을 입력으로 사용하는 LSTM이 추가적으로 사용되었다.
결과
계산 성능
IMPALA의 설계 목표에는 높은 처리량, 계산 효율성, 확장성이 있으며 이를 검증한 결과다. DeepMind Lab의 2가지 task에 대해, single machine 설정에서 IMPALA는 모든 batched A2C 변형과 A3C보다 뛰어난 성능을 보였다. 또한 distributed multi machine 설정은 IMPALA의 확장성이 더욱 부각되는데, IMPALA 에이전트는 250,000 frame/sec 혹은 210억 frame/day 의 처리 속도를 달성하였다.
Single-task Training
DeepMind Lab의 5가지 task에 대해 에이전트를 개별적으로 교육하는 single-task 시나리오의 결과다. 수렴과 안정성 관점에서 IMPALA, A3C, batched A2C를 비교하였을 때, 5개 task 모두에서 batched A2C 또는 IMPALA가 최고의 final average reward에 도달했다. 또한 IMPALA는 A3C보다 하이퍼파라미터 선택에 더 robust했는데, 더 다양한 하이퍼파라미터 조합의 평가에서 IMPALA는 A3C보다 높은 점수를 얻었다.
추가적으로 V-trace의 효과를 확인하기 위해, 동일한 환경에서 4가지의 서로 다른 알고리즘을 비교하였다.
- No-correction : Off-policy correction이 없다.
- 𝜀-correction : 기울기 계산 중 아주 작은 값(ε = 1e-6)을 추가한다. 이는 logπ(a)가 너무 작아지는 것을 방지한다.
- 1-step importance sampling : 𝑉(𝑥) 최적화 시 off-policy correction이 없으며, Policy gradient에서 각 time step의 advantage에 IS를 곱한다. 이는 "trace"가 없는 V-trace와 유사하다 볼 수 있다.
- V-trace : 제안된 알고리즘이다.
V-trace 및 1-step importance sampling의 경우 각 IS 𝜌𝑡 및 𝑐𝑡를 1에서 truncate 한다. 이를 통해 gradient estimate의 분산이 줄어들지만 편향이 발생하게 된다. 또한 𝜋과 𝜇 사이의 off-policy gap을 늘리기 위해 learner에 experience replay buffer를 추가한다. Replay buffer에서 각 배치의 50%를 무작위로 샘플링한다.
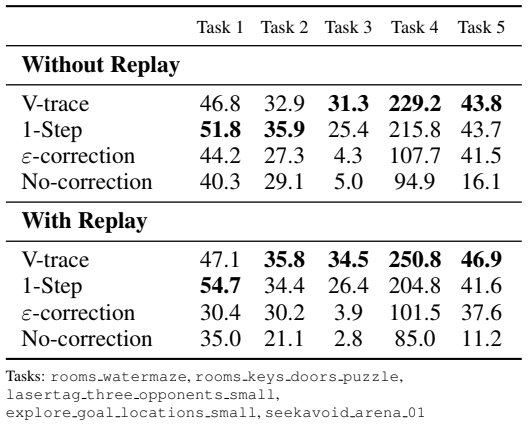
Replay가 없을때 V-trace는 5가지 task 중 3가지 task에서 가장 좋은 성능을 발휘했다. 1-step importance sampling은 replay가 없을때 V-trace와 유사하게 수행되지만, experience replay를 사용하면 4/5 작업에서 격차가 벌어지게 된다. 이는 target policy와 behavior policy의 gap이 커질수록 1-step importance sampling의 approximator가 학습에 어려움을 겪는다는 것을 의미한다. 이와 달리 V-trace는 experience replay를 통해 지속적으로 이점을 얻는다. 또한 다양한 하이퍼파라미터 조합에 대해서도 robust하다는 것을 아래를 통해 알 수 있다.

Multi-Task Training
IMPALA의 높은 데이터 처리량과 데이터 효율성을 통해, 훈련 설정을 최소한으로 변경하면서 하나의 작업뿐만 아니라 여러 작업을 동시에 훈련시킬 수 있다. 이는 모든 actor에 동일한 작업을 실행하는 대신, multi-task 문제에서 각 task에 고정된 수의 actor를 할당하는 것이다. 여기서 Actor는 자신이 어떤 task를 수행하는지 사전에 전달 받지 않는다. 이를 바탕으로 2 가지 환경에서 평가를 진행하였다.
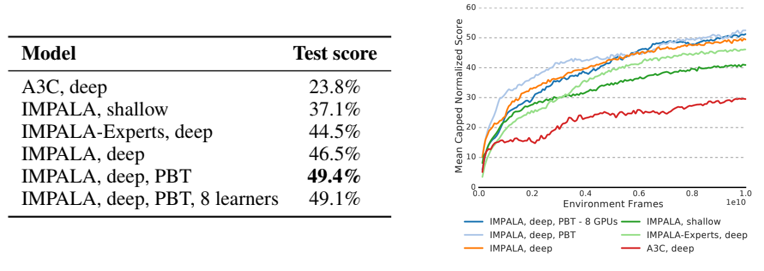
DMLab-30. 30가지 다양한 task 세트인 DMLab-30 환경에서 평가한 결과다. 각 task의 점수가 100%로 제한되는 mean capped human normalised 점수를 활용하였다. 이를 사용하면 single-task에서 특화되도록 집중하는 대신, multi-task을 해결하도록 집중시킬 수 있다. 위 표를 통해 Distributed A3C보다 IMPALA의 모든 버전이 더 좋은 성능을 발휘한다는 것을 알 수 있다.

또한 IMPALA는 성능 측면뿐만 아니라 학습 전반에 걸쳐 더 나은 성능을 발휘하는데, 위 그림을 통해 그 차이를 확인할 수 있다. 이는 wall-clock time에 따른 성능을 비교한 결과다. 이는 두 방식의 확장성 차이를 더욱 강조한다. Learner가 1명인 IMPALA는 A3C가 7.5일 학습 시 도달한 성능과 동일한 수준에 도달하는 데 약 10시간밖에 걸리지 않는다.
Atari. 57개 task로 이루어진 atari 게임 세트는, 서로 매우 다른 시각적 요소와 메커니즘을 갖추고 있어 multi-task 학습을 특히 어렵게 만든다. 이러한 환경을 바탕으로 IMPALA Atari-57 에이전트를 모든 57개 Atari 게임에 대해 동시에 2억 프레임에 대해 학습하였다.
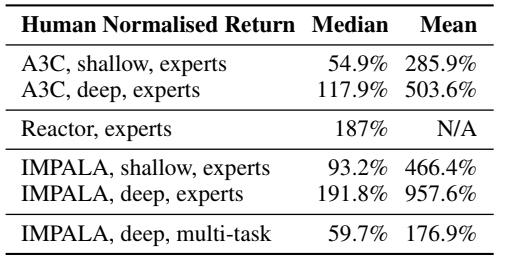
57개 Atari 게임에 걸쳐 mean human normalized score로 알고리즘을 비교하였다. IMPALA는 각각 deep model과 shallow model에서 A3C 전문가보다 더 나은 성능과 데이터 효율성을 보인다. 또한 57개 ALE 게임 모두에 대해 동시에 훈련된 IMPALA deep multi-tasking 버전은 59.7%의 점수를 보였다. 이를 통해 시각적 외관과 게임 메커니즘의 다양성에도 불구하고, IMPALA가 multi-taks에 강력하다는 것을 알 수 있다.
Reference
논문 링크 : https://arxiv.org/abs/1802.01561
'딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| [RL] CQL (0) | 2025.02.05 |
|---|---|
| [RL] R2D2 (0) | 2025.01.29 |
| [RL] Large-scale Curiosity-driven Learning (0) | 2025.01.15 |
| [RL] SAC (Soft Actor-Critic) (0) | 2025.01.08 |
| [RL] HER (0) | 2025.01.01 |