
키워드
1. 최대 엔트로피 강화학습을 활용한 SAC 알고리즘을 소개. 안정적이고 효율적인 정책 학습을 가능하게 하며, 다양한 환경에서 뛰어난 성능을 보임.
2. "Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor"
3. SAC, Soft Actor-Critic, maximum entropy, Soft policy iteration
Maximum Entropy Reinforcement Learning
Model-free Deep Reinforcement learning(RL) 알고리즘은 일반적으로 매우 높은 sample complexity와 취약한 수렴성이라는 두 가지 중요한 문제로 인해 세심한 하이퍼파라미터 조정이 필요하다. 이러한 문제로 인해 현실 세계에 적용되는 것이 제한된다. 높은 sample complexity의 원인 중 하나는 on-policy로, 각 gradient step마다 새로운 샘플을 필요로한다. 그리고 policy를 효과적으로 학습하기 위해 gradient step과 샘플의 수가 sample complexity에 따라 증가하므로 엄청난 비용이 소모된다.
이러한 문제는 off-policy 방식을 사용하면, 과거 경험을 활용함으로써 해결할 수 있다. 하지만 neural network를 통한 고차원, non-linear function approximator와 결합하면, 안정성과 수렴성이 불안해진다. 대표적인 알고리즘 중 하나인 DDPG는 효율적인 샘플 학습을 제공하지만, 극도의 취약성과 하이퍼파라미터 감도로 인해 사용하기가 매우 어렵다.
SAC(Soft Actor-Critic)는 maximum entropy 항을 추가한 강화학습 프레임워크를 기반으로 하는 off-policy actor-critic Deep RL 알고리즘이다. 여기서 Actor는 엔트로피를 최대화하는 동시에 예상 보상을 최대화하는 것을 목표로 한다. 즉, exploration 권장하는 동시에 robust에 상당한 개선을 제공한다. 이를 통해 continuous state-action space에서 샘플 효율적이고 안정적인 model-free deep RL 알고리즘을 설계할 수 있다. 추가적으로 RL의 target을 변경하지만 원래 target은 temperature 파라미터를 통해 복구할 수 있습니다
SAC (Soft Actor-Critic)
SAC는 세 가지 핵심 요소로 구성되어 있다. 먼저 별도의 policy 및 value network를 갖춘 actor-critic 아키텍처다. 이는 policy gradient 알고리즘에서 파생되었다. 이는 policy에 대한 value function을 계산하는 policy evaluation, 더 나은 policy를 위해 value function을 사용하는 policy improvement로 이루어진다. 이 경우 policy는 actor로 value는 critic으로 기능한다. 즉, 많은 actor-critic 알고리즘은 actor를 업데이트하기 위해 policy-based policy gradient 공식을 기반으로 구축되었다.
다음은 샘플 효율성을 위해 이전에 수집된 데이터를 재사용하는 off-policy 방식이다. 과거 policy를 통해 얻은 샘플을 통합하여, 분산 감소와 robust을 유지하면서 샘플 효율성을 높일 수 있다. 대표적인 off-policy actor-critic으로 DDPG가 있으며, Q function approximatior를 사용하여 off-policy 학습을 활성화하고, 이 Q function을 최대화하는 deterministic actor를 사용한다.
마지막으로 안정성과 exploration을 가능하게 하는 entropy maximization을 활용하였다. 이는 actor의 entropy를 maximize하는 것을 목표로 하며, DDPG의 효율성과 성능을 능가하는 훨씬 더 안정적이고 확장 가능한 알고리즘을 생성한다. Maximum entropy RL은 기대 수익과 기대 엔트로피를 모두 최대화하도록 policy를 최적화하며 optimal policy로 수렴한다.
Algorithm
강화학습에서 기본적으로 사용되는 notation으로 state space 𝒮와 action space 𝒜, 연속적이고 알 수 없는 state transition probability 𝑝가 있다. 𝑝는 현재 상태 st ∈ 𝒮 및 action a𝑡∈𝒜을 고려하여 다음 state s+1 ∈ 𝒮의 확률 밀도를 나타낸다. 또한 환경은 각 transition마다 보상 𝑟 을 반환하며, 𝜌𝜋(s𝑡) 및 𝜌𝜋(st, a𝑡)는 policy 𝜋(a𝑡|s𝑡)에 의해 유도된 state 및 state-action trajectory의 distribution이다.
Maximum Entropy Reinforcement Learning

표준 RL은 누적 reward의 기대값을 최대화한다. 여기에 SAC 알고리즘은 maximum entropy objective를 추가한다. 즉, 𝜌𝜋(s𝑡)에 대한 policy의 예상 엔트로피로 objective를 강화하여 stochastic policy를 유도한다.

여기서 temperature 파라미터 𝛼는 보상에 대한 엔트로피 항의 상대적 중요성을 결정하여 optimal policy의 확률성을 제어하는 인자다. 이 objective에는 개념적, 경험적 이점이 존재한다. 첫째, policy는 확실히 전망이 없는 길을 포기하면서 더 광범위하게 exploration하도록 장려된다. 둘째, policy는 optimal behavior에 가까운 여러 모드를 포착하며, 여러 모드가 똑같이 매력적으로 보이는 문제에서 policy는 동일한 확률 질량을 적용한다. 셋째, 실험적으로 기존의 RL objective 함수를 최적화하는 SOTA 방법에 비해, 학습 속도가 상당히 향상된다.
Soft Policy iteration
SAC는 policy iteration 방법의 maximum entropy 변형에서 시작되었다. 이에 soft policy iteration 부터 확인하고자 한다. Tabular setting을 기반으로 하나, 이 방법을 continuous setting으로 확장할 수 있다. Soft policy iteration의 policy evaluation 단계에서 maximum entropy objective에 따른 policy 𝜋의 value를 계산하고자 한다. Fixed policy의 경우, soft Q-value는 임의의 Q function에서 시작하여 Bellman backup operator 𝒯𝜋를 통한 반복으로 구할 수 있다. 여기서 V(st)는 soft state value function이다.
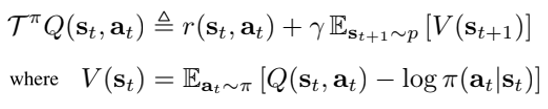
이를 바탕으로 𝒯𝜋을 무한하게 반복적으로 적용하면, 모든 policy 𝜋에 대한 soft value function을 얻을 수 있다. 즉, Qk+1 = 𝒯𝜋*Qk 일때 k를 무한히 반복하면 soft Q-value가 수렴하게 된다.
이후 policy improvement에서는 새로운 Q function의 exponential을 취한 값으로 policy를 업데이트한다. 이러한 업데이트 방식은 soft value 측면에서 policy의 향상을 보장한다. 가우시안과 같이 상대적으로 다루기 쉬운 parameterized distribution의 policy set Π으로 policy를 제한한다. 𝜋∈Π 제약 조건에 따라, 개선된 policy를 이 policy set에 project한다. 이를 KL divergence를 통해 각 state 별로 policy를 업데이트한다.
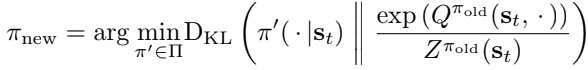
Partition function 𝑍𝜋old(st)는 분포를 normalize하는 역할을 한다. 이를 바탕으로 objective 관점에서 새로운 policy가 항상 이전 policy보다 더 높은 value를 가지게 된다.
최종적으로 soft policy iteration 알고리즘은 soft policy evaluation과 soft policy improvement 단계를 번갈아 수행하며, Π의 정책 중에서 optimal maximum entropy policy로 수렴하게 된다. 다만 tabular setting의 경우에만 정확하게 이를 수행한다. continuous space에서는 Q-value을 표현하기 위해 function approximator에 의존하고, 수렴까지 너무 많은 연산량이 필요하기 때문에 soft actor-critic을 통해 이를 근사화한다.
Soft Actor-Critic
Large-scale continuous space에서는 soft policy iteration에 대한 근사치를 도출해야 한다. Q function과 policy 모두 function approximator를 사용하고, 수렴을 위한 evaluation 및 improvement를 실행하는 대신 SGD를 통해 두 네트워크를 번갈아 optimize한다.
Parameterized된 state value function 𝑉𝜓(s𝑡), soft Q function 𝑄𝜃(s𝑡,at), policy 𝜋𝜙(at|s𝑡)를 고려해보자. 예를 들어, value function은 neural network로 모델링할 수 있고, policy는 neural network에서 제공하는 mean과 variance를 갖는 가우스로 모델링할 수 있다. 이런 파라미터 벡터들의 업데이트 규칙을 알아보자.
State value function 𝑉𝜓(s𝑡)는 soft value에 근사된다. State value에 대해 별도의 function approximator는 필요 없을 수 있지만, 경험적으로 이를 통해 훈련을 안정화할 수 있다. 또한 편리하게 다른 네트워크와 동시에 훈련할 수 있다.

Soft value function은 위와 같이 squared residual error를 최소화하도록 학습된다. 여기서 𝒟는 이전에 샘플링된 state 및 action의 분포, 혹은 replay buffer이다. Action이 replay buffer 대신 현재 policy에 따라 샘플링된다면, unbiased estimator로 기울기를 추정할 수 있다.

Soft Q-function의 파라미터는 soft Bellman residual을 최소화하도록 학습된다. 이는 stochastic gradient로 최적화 된다. 이 과정에서 target value network 𝑉𝜓̅를 사용한다. 𝜓̅는 value 네트워크 가중치의 지수 이동 평균을 의미하며, 이를 통해 훈련을 안정화할 수 있다. 또는 현재 value function 가중치와 동일하게 주기적으로 target 네트워크의 가중치를 업데이트하는 방법도 있다.

마지막으로, KL-divergence를 최소화하도록 policy 파라미터를 학습한다. 𝐽𝜋를 최소화하는 policy gradient 방법의 가장 일반적인 솔루션은 likelihood ratio gradient estimator이다. 이는 policy와 target density 네트워크를 통해 기울기를 backprop할 필요가 없다.

SAC의 target density는 NN으로 표현되는 Q function이며, 미분 가능하기 때문에 위 방법보다 reparameterization trick을 적용하는 것이 더 편하다. 이를 위해 위와 같이 neural network transformation으로 policy를 reparameterize 할 수 있다. 𝜖𝑡는 fixed distribution에서 샘플링된 input noise vector이다.


이를 바탕으로 objective를 다시 구성할 수 있다. 𝜋𝜙는 𝑓𝜙에서 암시적으로 정의되며, partition function은 𝜙와 독립적이므로 생략할 수 있다. 이를 통해 기울기도 근사화할 수 있으며, 이러한 unbiased gradient estimator는 DDPG 스타일의 deterministic policy gradient를 다루기 쉬운(tractable) stochastic policy으로 확장한다.
SAC는 또한 value-based 방법의 성능을 저하시키는 것으로 알려진, policy improvement 단계의 positive bias를 완화하기 위해 두 개의 Q function을 사용한다. 파라미터 𝜃𝑖를 사용하여 두 개의 Q function을 parameterized하고 𝐽𝑄(𝜃𝑖)을 최적화하기 위해 독립적으로 훈련한다. 이후 value gradient를 구할때 둘 중 최소값을 사용한다. 이렇게 두 개의 Q function을 사용하면 특히 더 어려운 작업에서는 훈련 속도를 크게 높이는 것을 발견하였다.
부가적으로 현재 policy를 사용하여 환경에서 수집한 experience와 replay buffer에서 샘플링한 experience를 번갈아 가며 업데이트에 사용한다. 이러한 방식은 value estimator와 policy 모두 off-policy 데이터에 대해 훈련할 수 있기 때문에 가능하다.
결과
OpenAI Gym과 휴머노이드 task rllab 환경에서 평가를 진행하였다. 특히, 21차원 휴머노이드(rllab)와 같은 더 복잡한 벤치마크는 off-policy 알고리즘으로 해결하기가 매우 어렵다. 이는 작업이 쉬울수록 하이퍼파라미터를 적당히 조정하여 좋은 결과를 얻는 것이 쉽지만, 가장 어려운 벤치마크에선 하이퍼파라미터가 보다 민감하여 효과적인 하이퍼파라미터를 설정하기 어렵기 때문이다.

위는 학습 중 evaluation rollout의 total average reward 결과다.서로 다른 무작위 시드를 사용하여 알고리즘 별 5개 인스턴스를 훈련하였고, 각 인스턴스는 1000 step마다 하나의 evaluation rollout을 수행한다. 실선은 평균, 음영 영역은 5회 시행에 대한 최소, 최대를 의미한다.
전반적으로 SAC가 학습 속도와 최종 성능 측면에서 쉬운 task는 기본 방법과 비슷한 성능을 발휘하고, 어려운 task는 큰 차이로 능가했다. 또한 PPO보다 상당히 빠르게 학습할 수 있는데, 이는 PPO가 고차원적이고 복잡한 작업을 안정적으로 학습하는 데 필요한 배치 크기가 크기 때문이다. 다른 maximum entropy RL 알고리즘인 SQL도 모든 task를 학습할 수 있지만, SAC보다 느리고 성능이 더 나쁘다. 이를 바탕으로 SAC의 우수한 샘플 효율성과 성능을 확인할 수 있다.
Ablation

Stochastic vs. deterministic policy. SAC는 maximum entropy objective를 통해 stochastic policy를 학습한다. Entropy는 policy distribution의 조기 수렴을 방지하고, value function에서 state space의 value를 증가시켜 exploration을 장려한다. 이러한 특성이 성능에 어떤 영향을 미치는지 비교한 결과다.
SAC의 deterministic 버전은 두 개의 Q 함수를 갖는 것을 제외하고 DDPG와 매우 유사하다. 별도의 target actor가 없고, 학습된 탐색 노이즈가 아닌 고정된 노이즈를 사용한다. SAC는 훨씬 더 일관되게 수행되는 반면, deterministic 버전은 시드 전체에 걸쳐 매우 높은 변동성을 나타내어 안정성이 상당히 낮다는 것을 알 수 있다. 즉, entropy maximization을 통한 stochastic policy가 훈련을 획기적으로 안정화시킨다는 것을 의미한다. 이는 하이퍼파라미터 튜닝이 어려운 복잡한 task에서 특히 중요하다.

Policy evaluation. SAC는 stochastic policy로 수렴되지만, 최상의 성능을 위해 최종적으로 deterministic policy를 사용하는 것이 유용한 경우가 많다. Evaluation 단계에서도 이러한 전략으로 얻은 reward가 stochastic을 활용한 evaluation보다 더 나은 성능을 얻었다는 것을 확인할 수 있다.
Reward scale. SAC는 reward의 scale에 특히 민감하다. 만약 scale이 작은 경우 policy가 거의 균일해지며 결과적으로 보상 signal을 활용하지 못해 성능이 크게 저하되며, scale이 큰 경우 모델은 처음에는 빠르게 학습하지만 policy가 사실상 deterministic하게 되어 적절한 탐색이 불가하고 local minimum에 빠진다. 즉, 적당한 scale을 통해 모델은 exploration과 exploitation의 균형을 잘 유지하여 더 빠른 학습과 성능을 제공한다. 경험적으로 SAC 성능에 영향을 주는 유일한 하이퍼파라미터이다.
Target network update. 안정성을 높이기 위해 value function를 천천히 추적하는 별도의 target value 네트워크를 사용하는 것이 일반적이다. SAC에서는 target value 네트워크의 가중치를 업데이트하기 위해 smoothing constant 𝜏를 통한 지수 이동 평균을 사용한다. 예시로 1은 가중치가 매 반복마다 직접 복사되는 하드 업데이트에 해당하고, 0은 전혀 업데이트하지 않는 것을 의미한다. 큰 𝜏은 불안정을 유발하고, 작은 𝜏은 훈련 속도를 느리게 만든다. 다만 적절한 𝜏의 범위가 상대적으로 넓다는 것을 알 수 있다.

지수 이동 평균을 사용하는 대신 1000 step마다 현재 네트워크 가중치를 target 네트워크에 직접 복사하는 SAC의 다른 버전과도 비교한 결과다. 이 방식이 step 간 둘 이상의 gradient step을 취함으로써 이점을 얻을 수 있다는 것을 발견했다. 다만 성능 향상만큼 계산 비용도 증가되게 된다.
Reference
논문 링크 : https://arxiv.org/abs/1801.01290
'딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| [RL] Large-scale Curiosity-driven Learning (0) | 2025.01.15 |
|---|---|
| [RL] HER (0) | 2025.01.01 |
| [RL] ICM (Intrinsic Curiosity Module) (0) | 2024.12.25 |
| [RL] PPO (0) | 2024.12.18 |
| [RL] ACER (1) | 2024.12.11 |