키워드
1. Actor-Critic 알고리즘에 경험 재플레이를 도입하여, 샘플 효율성을 높이고 학습 안정성을 향상시킴.
2. "Sample Efficient Actor-Critic with Experience Replay"
3. ACER, A3C, Experience Replay, importance weight truncation, Efficient TRPO
Actor-Critic with Experience Replay
에이전트가 광범위한 레퍼토리를 학습할 수 있게 도움을 주는 시뮬레이션 기술은 AI 발전의 핵심 중 하나다. 더욱 현실감 넘치는 환경으로 인해 에이전트의 능력이 향상되지만, 불행하게도 이러한 발전은 시뮬레이션 비용의 상당한 증가를 동반한다. 따라서 시뮬레이션 비용을 줄이려면 시뮬레이션 단계(즉, 환경 샘플)의 수를 줄여야한다. 또한 이러한 샘플 효율성은 에이전트가 실제 세계에 배포될 때 더욱 중요하다.
Experience replay는 샘플간 상관 관계를 줄이기 위한 기술이며, 뿐만 아니라 샘플 효율성을 향상시키는 중요한 기술이다. 하지만 두 가지 한계점이 존재한다. 먼저, optimal policy의 deterministic한 특성으로 인해 adversarial(적대적)한 도메인에서 사용이 제한된다. 그리고 Q function과 관련하여 greedy behavior를 찾는 것은 큰 action space의 경우 비용이 많이 든다.
Policy gradient 방법은 또한 AI 분야의 중요한 핵심 중 하나이다. 다만 이 방법의 대부분은 continuous하거나 바둑과 같은 매우 특정한 작업으로 제한된다. 그 중 A3C(Asynchronous Advantage Actor-Critic)는 이와 달리 continuous 도메인과 discrete 도메인 모두에 적용 가능한 모델이지만 샘플 비효율적인 특징이 있다.
이에 continuous, discrete action space 모두에 적용되는 안정적이고 샘플 효율적인 actor-critic의 설계가 필요하며, ACER(Actor-Critic with Experience Replay)은 까다로운 환경에서 탁월한 성능을 발휘하며 experience replay 기능을 갖춘 actor-critic deep RL 에이전트이다. 이는 Atari에서 SOTA를 다성한 PER을 사용한 Deep Q-Network의 성능과 동등하며, 샘플 효율성 측면에서 A3C보다 훨씬 뛰어나다. ACER는 bias correction을 통한 TIS(truncated importance sampling), SDN(stochastic dueling network), efficient trust region policy optimization 등의 새로운 방법이 활용되었다.

Policy gradient는 discounted approximation을 통해 업데이트될 수 있으며, 신경망을 통해 이 값을 근사화한다. 이 과정에서 근사로 인한 오류와 편향이 추가된다. 이를 위한 방법 중 Rt를 사용하는 PG approximator는 더 높은 분산과 더 낮은 편향을 갖는 반면, function approximator는 더 높은 편향과 더 낮은 분산을 갖는 경향을 보인다. ACER은 제한된 분산을 유지하면서 편향을 최소화하기 위해 Rt와 function approximator를 결합하였다. A3C도 이러한 trade-off를 조절하고자 했으며, 단일 샘플 trajectory를 통해 다음과 같은 기울기를 활용하였다.
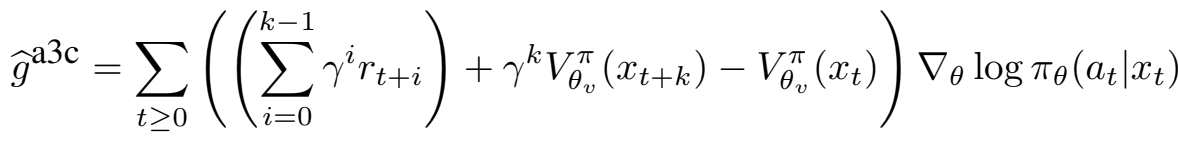
A3C는 k-step의 return과 function approximator를 결합하여 분산과 편향을 조절했다. Vπθ(xt)는 분산을 줄이는 PG의 baseline이다. ACER은 A3C 방법에 대응하는 off-policy 방식으로 이해할 수 있다. 즉, ACER는 단일 심층 신경망을 사용하여 policy πθ(at|xt)와 가치 함수 Vπθ(xt)를 추정하며, 신경망을 기반으로 새로운 모듈이 사용되었다.
Discrete ACER
Experience replay를 통한 off-policy 학습은 actor-critic의 샘플 효율성을 향상시키기 위한 방법이다. 하지만 off-policy estimator의 분산과 안정성을 제어하는 것은 매우 어렵다. Importance Sampling (IS)는 이러한 off-policy의 문제를 해결하기 위한 유용한 기술 중 하나이다. IS의 weighted policy gradient는 아래와 같다.
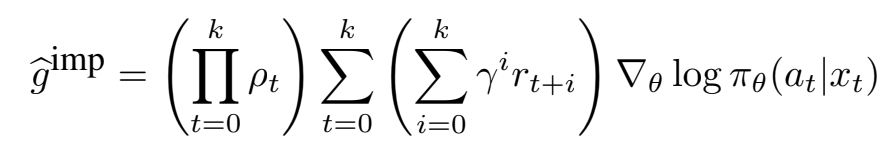
ρt는 importance weight를 나타낸다. 이 estimator는 biased되지는 않지만, 많은 importance weight의 곱을 포함하므로 분산이 매우 크다. 이러한 곱이 폭발하는 것을 방지하기 위해 곱을 truncate 할 수 있다. 전체 trajectory에 대한 truncated importance sampling으로 분산은 제한되지만, 상당한 bias가 문제가 될 수 있다.
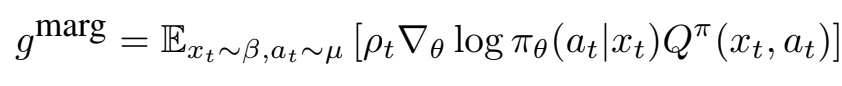
이 문제를 해결하기 위해 위와 같이 marginal value function을 분포를 제한하는데 사용했다. 이 방법은 Qμ가 아닌 Qπ에 의존하므로 결과적으로 Qπ를 추정할 수 있어야 하며, importance weight의 곱이 없고 대신에 marginal importance weight ρt만 추정한다. 이러한 저차원 공간에서의 IS은 더 낮은 분산을 가진다.
State-action function의 Multi-step estimation
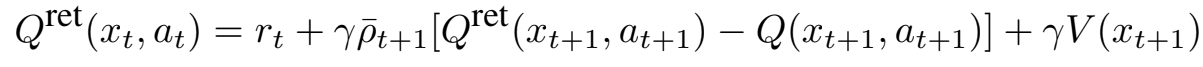
ACER은 Retrace를 사용하여 Qπ(xt, at)를 추정한다. Behavior policy μ 에서 생성된 trajectory가 주어지면 Retrace 추정기는 위와 같이 재귀적(recursive)으로 표현될 수 있다. Retrace는 분산이 작고 모든 behavior policy에 대한 target policy의 value function이 수렴하는 것으로 증명된 off-policy, return-based 알고리즘이다.
Recursive Retrace 방정식은 Q의 estimate에 따라 달라진다. Discrete action space에서 이를 계산하기 위해선 Qθv(xt, at)와 πθ(at| xt)를 출력하는 ‘two head’ CNN을 사용해야한다. 이는 A3C 구조에서 스칼라 Vθv(xt) 대신 벡터 Qθv(xt, at)를 출력한다는 점만 제외하면 나머지는 동일하다. Vθv(xt)는 πθ 아래에서 Qθv의 기대치를 취함으로써 쉽게 도출할 수 있다.
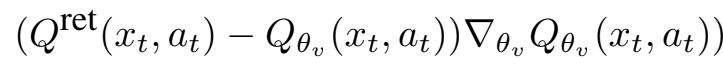
Policy gradient gmarg를 근사화하기 위해 ACER은 Qret을 사용하여 Qπ를 추정한다. Retrace는 multi-step reward를 사용하므로 policy gradient estimation의 bias를 크게 줄일 수 있다.Critic Qθv(xt, at)를 학습하기 위해 다시 Qret(xt, at)을 MSE loss의 target으로 사용하고, 파라미터 θv를 위 기울기로 업데이트한다.
Retrace는 return-based이므로 critic의 학습 속도도 빨라진다. 이에 따라 multi-step Qret은 policy gradient의 bias를 줄이고, critic의 더 빠른 학습을 가능하게 하여 bias를 더욱 줄일 수 있다.
Bias correction을 통한 importance weight truncation
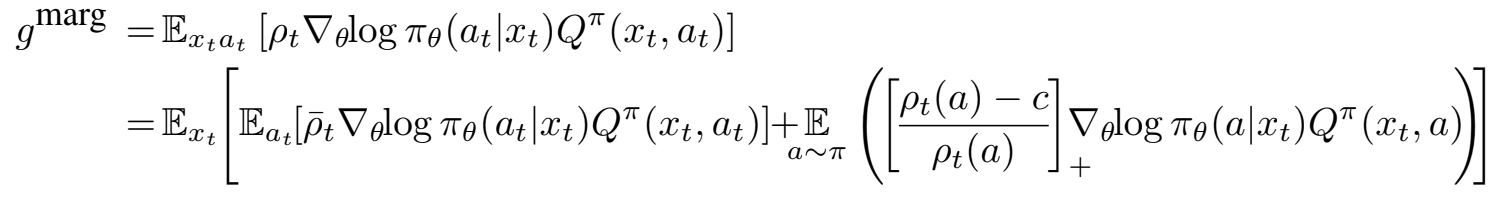
이전 gmarg는 marginal importance weight가 커져 불안정성이 발생할 수 있다. 이에 위와 같이 gmarg를 분해하였다. ρ̅t는 min{c, ρt}를 의미하며, [x]+는 x > 0이면 x이고 그렇지 않으면 0을 의미한다. 첫 번째 항에서 importance weight를 clipping하면 추정된 기울기의 분산이 제한되고, correction term(두 번째 항)은 추정치가 편향되지 않도록 보장한다. 특히 correction term은 ρt(a) > c 에 대해서만 활성화되며, 큰 c 값을 선택하면 원래 off-policy estimate의 분산이 매우 큰 경우에만 correction term이 적용된다. 이러한 분해는 첫 번째 항의 최대 가중치가 c이고, correction term의 수정 가중치가 최대 1이라는 좋은 속성을 띄게한다. 그리고 c가 무한대일 때 off-policy policy gradient로 사용되며, c가 0일 때는 estimate Q에 전적으로 의존하는 actor-critic 업데이트로 사용될 수 있다.

신경망으로 구한 estimate Qθv(xt, at)를 사용하여, correction term의 Qπ(xt, a)를 모델링한다. 이 correction을 “truncation with bias correction trick” 라고 하며, 위와 같이 근사치를 구할 수 있다. 이는 Markov process의 stationary distribution에 대한 expectation을 포함하지만, behavior policy µ에서 생성된 trajectory {x0, a0, r0, µ(·|x0), · · · , xk, ak, rk, µ(·|xk)}를 샘플링하여 이를 근사화한다. 이 trajectory를 통해 off-policy ACER gradient를 계산할 수 있다. 추가적으로 분산을 줄이기 위해 baseline Vθv(xt)를 뺀다.

Efficient Trust Region Policy Optimization
Actor-critic의 policy 업데이트는 종종 높은 변동성을 보인다. 따라서 안정성을 보장하려면 policy의 업데이트를 제한해야한다. 다만 단순히 작은 learning rate를 사용하는 것만으로는, 원하는 학습 속도를 유지하면서 가끔씩 발생하는 변동성만 방지할 수 없다. TRPO(Trust Region Policy Optimization)는 이를 위한 적절한 솔루션이다.
이는 업데이트될 policy과 현재 policy 간의 차이를 제한하는 방식이다. 하지만 업데이트할 때마다 Fisher 벡터 곱을 반복적으로 계산해야 하기 때문에, 큰 규모의 도메인에서는 엄청나게 비용이 많이 들 수 있다. 이에 고차원 문제에 맞게 확장 가능한 새로운 TRPO 방식을 고안하였다.
이는 과거 policy의 running average를 나타내는 average policy 네트워크를 통해, 업데이트된 policy가 이 평균에서 크게 벗어나지 않는 방법을 사용하였다. 이 policy 네트워크는 분포 f와 분포의 통계 Φθ(x)를 생성하는 Deep NN 두 부분으로 분해할 수 있다. f를 통해 policy 네트워크는 Φθ: π(·|x) = f(·|Φθ(x)) 로 characterized 될 수 있으며, policy 파라미터 θ를 업데이트할 때 average policy 네트워크의 파라미터 θa를 통해 "부드럽게" 업데이트한다.
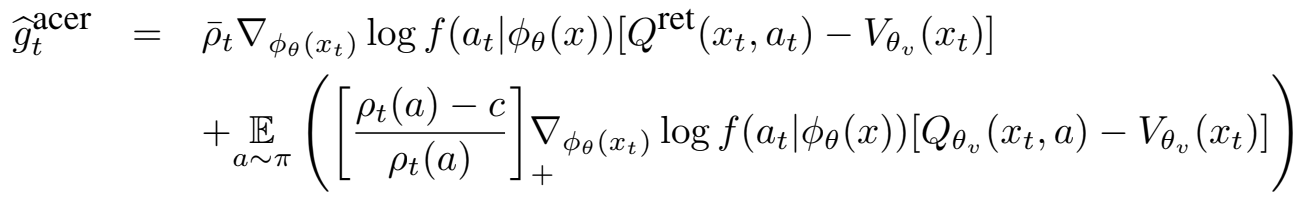
위 식은 ACER policy gradient이다. 이를 바탕으로 trust region 업데이트는 두 단계로 구성된다. 첫 번째 단계는 선형화된 KL divergence 제약 조건을 사용하여 아래 optimization 문제를 해결한다.
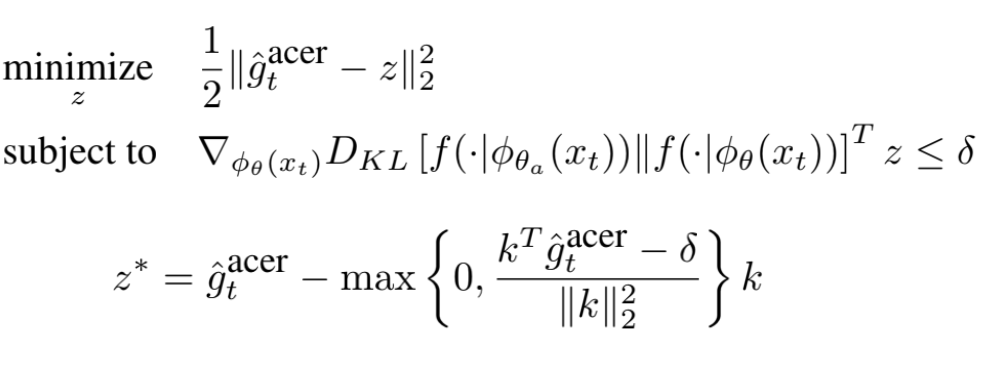
제약 조건이 선형이므로 전체 최적화 문제는 간단한 2차 프로그래밍 문제로 줄어들며, 이 문제의 해는 KKT 조건을 사용하여 closed form으로 쉽게 파생될 수 있다. 이에 따른 해는 z*로 구할 수 있다. 여기서 제약 조건이 충족되면 Φθ(xt)에 대한 기울기의 변화가 없다. 그렇지 않으면 업데이트가 k 만큼 축소되어 변화율을 효과적으로 낮춘다. 두 번째 단계는 backpropagation을 활용한다. z*는 네트워크를 통해 역전파되어 파라미터에 대한 도함수를 계산한다. Policy 네트워크에 대한 파라미터 업데이트는 chain rule을 따른다.
Continuous Actor-Critic
Retrace는 Q와 V 모두의 추정이 필요하지만 continuous action space에서 Q를 통해 V를 도출하기 어렵다. Retrace는 Qθv 학습 목표를 제공하지만 Vθv 학습 목표는 제공하지 않는다. 주어진 Qθv에 대해 importance sampling을 사용하여 Vθv를 계산할 수 있지만 분산이 높은 단점이 있다.
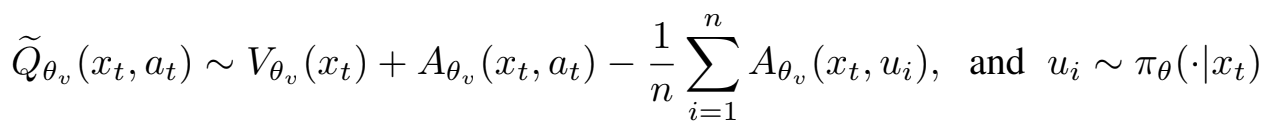
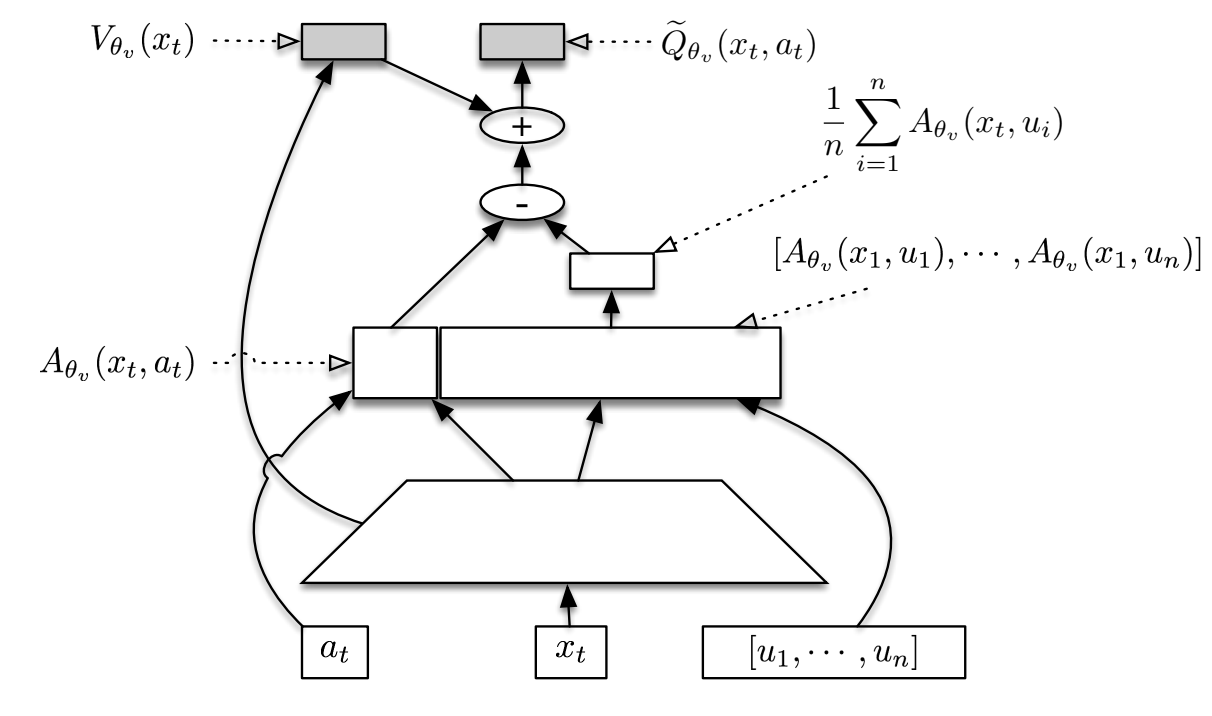
이에 dueling 네트워크에 영감을 받아 Stochastic Dueling Networks(SDN)이라고 하는 새로운 아키텍처를 고안하였다. 이는 두 추정치 간의 일관성을 유지하면서 Vπ와 Qπ off-policy를 모두 추정하도록 설계되었다. 각 time step에서 SDN은 stochastic 추정치 Qθv, Qπ와 deterministic 추정치 Vθv, Vπ를 출력한다.
결과
Atari

Discrete space를 위한 평가로, ACER은 GPU 없이 단일 시스템에서 실행되는 16개의 actor-learner 스레드에서 평가되었다. Atari 57개 게임 전체에 걸친 점수의 중앙값을 평가 지표로 활용하였으며, 각 게임에 대해 인간 점수와 무작위 점수가 각각 1과 0으로 평가되도록 normalize 하였다. 위 이미지는 각 에이전트에 대해 cumulative maximum median 점수다.
4가지 replay ratio에 대해 실험하였으며, ratio 4는 on-policy component(A3C)를 사용한 후, ACER의 off-policy component를 4번 사용한다는 의미한다. 실선과 점선은 trust region의 적용되거나 되지 않은 ACER을 나타낸다. 왼쪽 패널에 표시된 것처럼 replay는 데이터 효율성을 크게 향상시킨다. 그리고 TR을 사용할 때 단계 수에 따른 평균 보상이 replay ratio에 따라 증가한다는 것을 관찰할 수 있다. 이러한 증가로 인해 return은 감소하지만 충분한 replay을 통해 ACER는 SOTA와 동등한 성능을 달성하였다. 또한 ACER이 A3C보다 훨씬 더 샘플 효율적이라는 것도 알 수 있다.
오른쪽 패널은 wall-clock time으로 측정했을 때 ACER 에이전트가 A3C와 유사하게 수행된다는 것을 보여준다. 이는 시간을 희생하지 않고도 더 나은 데이터 효율성을 달성했다는 것을 의미한다.
MuJoCo
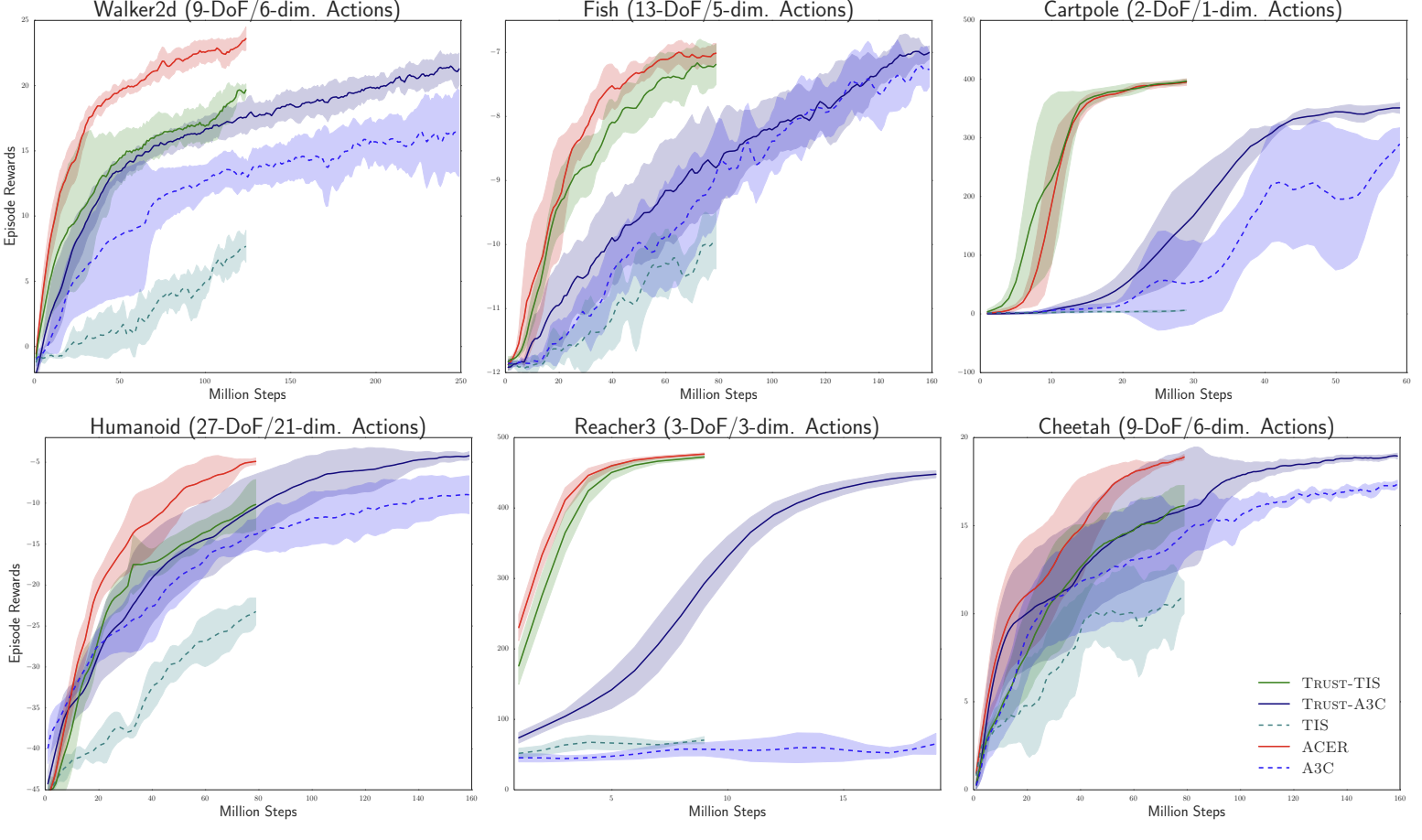
Baseline으로 A3C와 Trust-A3C가 있으며, Truncation importance sampling을 통한 baseline도 Trust-TIS 및 TIS라는 이름으로 비교하였다. 마지막으로 Continuous space를 다루는 SDN 아키텍처를 간단히 ACER이라고 표현하였으며, 다섯 가지 설정은 모두 A3C 프레임워크에서 구현되었다.
ACER는 다른 baseline보다 매우 큰 차이로 성능 차이를 보였다. 특히 새로운 TRPO 방법이 큰 개선을 가져올 수 있음을 알 수 있다. 이는 고차원의 continuous action policy가 Atari와 같은 소규모 discrete action policy보다 최적화하기가 훨씬 어렵기 때문에, continuous 도메인에 훨씬 더 높은 성능 향상을 보인 것으로 판단된다.
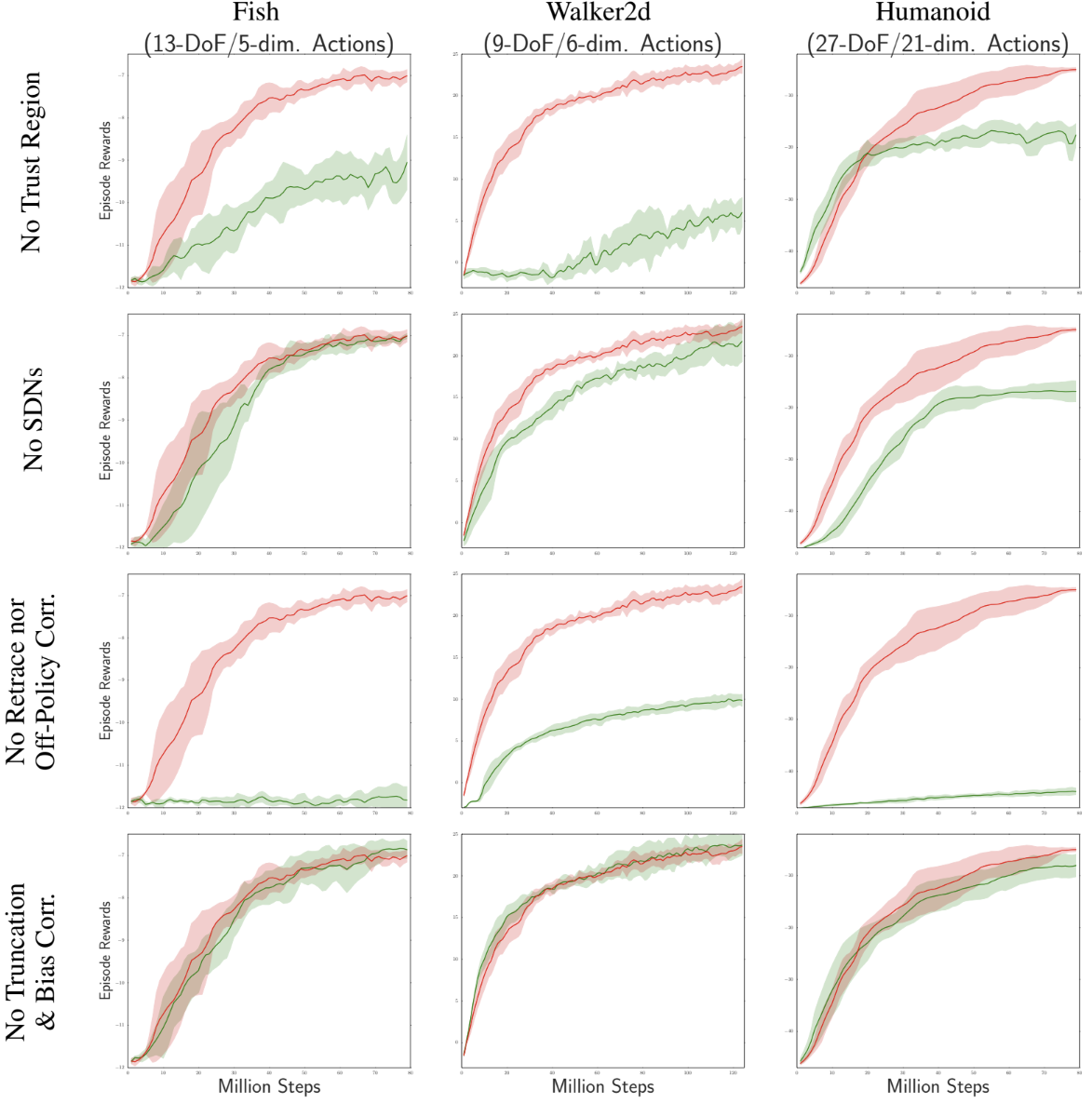
ACER의 다양한 구성 요소의 기여도를 자세히 분석하기 위한 ablation study다. Retrace, SDN, trust region, truncation 을 개별적으로 제거하고 원래 방식과 비교하였으며, 이들 중 하나라도 제거하면 성능이 확실히 저하되었다. 특히 Truncation은 Fish 및 Walker2d 에서 동일한 결과를 보였지만, action space의 차원이 훨씬 더 높은 humanoid에서는 성능에 영향을 미쳤다. 이는 action space의 차원이 증가할 수 록 importance weight의 분산을 증가시키며, bias correction의 필요성을 증가시키기 때문으로 해석된다.
Reference
논문 링크 : [1611.01224] Sample Efficient Actor-Critic with Experience Replay (arxiv.org)
'딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| [RL] ICM (Intrinsic Curiosity Module) (0) | 2024.12.25 |
|---|---|
| [RL] PPO (0) | 2024.12.18 |
| [RL] AlphaGO (1) | 2024.12.04 |
| [RL] A3C (1) | 2024.11.27 |
| [RL] Gorila (0) | 2024.11.26 |