키워드
1. 강화학습의 분산 학습 방법을 통해 병렬 처리 및 대규모 데이터 사용의 이점을 설명함. 이를 통해 학습 속도와 성능을 크게 향상시킬 수 있음.
2. "Massively Parallel Methods for Deep Reinforcement Learning"
3. Gorila, distributed training
Massively distributed training
Reinforcement learning(RL)은 action-value(Q) function을 CNN을 통한 근사로 딥러닝과 성공적으로 결합되었다. DQN으로 알려진 Deep Q-Network를 훈련하는 새로운 방법을 통해, RL은 고차원 이미지를 입력으로 사용하여 복잡한 환경에서 policy를 학습할 수 있게 되었다. 다만 현실적으로 훈련 시간이 많이 소요되며, 이에 DQN과 같은 Deep 강화 학습 알고리즘을 확장할 수 있는 distributed 아키텍처가 필요하게 되었다.
이를 위한 massively distributed 아키텍처 Gorila를 제안하며, 이는 크게 네 가지 구성 요소를 사용한다. 개념적으로 서로 다른 learner가 experience replay memory에서 저장된 샘플을 읽고, 주어진 RL 알고리즘에 따라 value function 또는 policy를 업데이트한다.
- 새로운 behavior을 생성하는 병렬 actor
- .장된 experience을 통해 훈련된 병렬 learner
- value function 또는 behavior policy을 나타내는 distributed neural network
- distributed experience storage
RL의 고유한 속성은 에이전트가 환경과 상호 작용하며 훈련 데이터 분포에 영향을 미친다는 것이다. 이에 더 많은 데이터를 생성하기 위해, 동일한 여러 개의 환경 인스턴스와 상호 작용하는 병렬로 구성된 여러 에이전트를 활용할 수 있다. 그리고 각 actor 별로 experience를 저장할 수 있어 distributed experience replay를 효과적으로 제공할 수도 있다. 더 많은 데이터를 생성하는 것 외에도 각 actor는 약간 다른 policy에 따라 동작하므로, state space를 보다 효과적으로 exploration 할 수도 있다.
Reinforcement learning

RL에서 에이전트는 누적 reward을 최대화한다는 목표를 가지고 환경과 순차적으로 상호 작용한다. 각 단계 𝑡에서 에이전트는 state 𝑠𝑡를 관찰하고 action 𝑎𝑡을 선택하여 reward 𝑟𝑡를 받는다. 여기서 policy 𝜋(𝑎|𝑠)는 state를 action에 매핑하고 behaivor를 정의하며, reward는 time step당 𝛾∈[0,1] 만큼 discount 된다. Action-value function 𝑄𝜋(𝑠,𝑎)은 𝑠𝑡를 관찰하고 𝑎를 𝜋에 따라 취한 후 예상되는 reward이며, optimal 𝑄*(𝑠,𝑎) 달성할 수 있는 최대 값이다. Action-value function은 Bellman equation을 따른다.
강화 학습의 핵심 아이디어 중 하나는 신경망을 통한 function approximator를 사용하여 𝑄(𝑠,𝑎)=𝑄(𝑠,𝑎;𝜃)로 action-value function을 표현하는 것이다. 즉, 파라미터 𝜃로 Q-network Bellman 방정식을 근사적으로 풀 수 있도록 최적화하게 된다. DQN은 훨씬 더 안정적인 RL 알고리즘으로 이러한 Q-learning 방식에 experience replay, target network 기법을 도입한 모델이다. DQN 손실 및 기울기는 아래와 같다.

Gorila
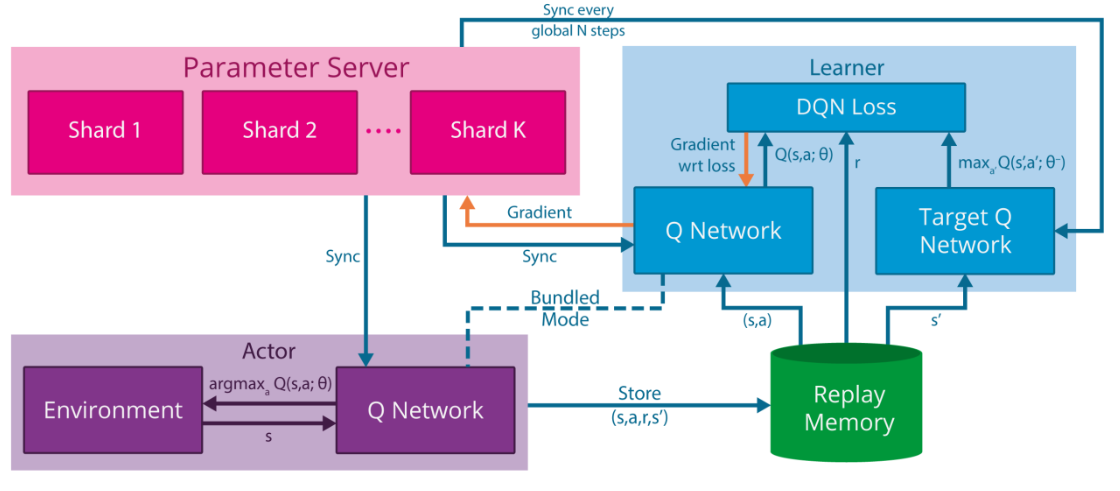
위 이미지는 Gorila (General Reinforcement Learning Architecture)라는 massively distributed RL을 위한 프레임워크를 나타낸 이미지다. Gorila 아키텍처는 RL 에이전트의 병렬화에 있어 상당한 유연성을 제공한다. 먼저, 대량의 데이터를 global replay 데이터베이스에 생성한 다음 단일 learner로 해당 데이터를 처리하는 작동이 가능하다. 이와 대조적으로, 단일 actor가 로컬 replay memory에 데이터를 생성한 다음 여러 learner가 이 데이터를 병렬로 처리하여 experience를 최대한 효과적으로 학습하도록 하는 것도 가능하다. 다만 병목 현상을 일으키는 것을 방지하기 위해, 일반적인 actor, learner, parameter server 수를 사용하여 분산(distributed)된 방식으로 모델을 업데이트하는 것이 좋다.
Actor
모든 강화 학습 에이전트는 궁극적으로 해당 환경에 적용할 action 𝑎𝑡를 선택한다. Gorila에는 동일한 환경의 각 인스턴스에 적용되는 𝑁𝑎𝑐𝑡개의 다양한 actor가 존재한다. 각 actor 𝑖는 환경 내에서 고유한 experience trajectory 𝑠1𝑖,𝑎1𝑖,𝑟1𝑖, … ,𝑠𝑇𝑖,𝑎𝑇𝑖,𝑟𝑇𝑖 을 생성하며, 결과적으로 각 actor는 state space의 서로 다른 부분을 방문한다. 이에 따라 𝑇 time step 후에 actor가 생성하는 experience 수는 대략 𝑇*𝑁𝑎𝑐𝑡가 된다.
각 액터에는 𝜖-greedy policy 등을 사용하여 behavior를 결정하는 데 사용되는 Q-network의 복제본이 포함되어 있다. 이 네트워크의 파라미터는 파라미터 서버에서 주기적으로 동기화된다.
Experience replay memory
Actor가 생성한 experience tuple 𝑒𝑡𝑖=(𝑠𝑡𝑖,𝑎𝑡𝑖,𝑟𝑡𝑖,𝑠𝑡+1𝑖)은 replay memory 𝐷에 저장된다. Local experience memory는 각 actor의 경험을 해당 actor의 로컬 컴퓨터에 저장하며, global experience memory는 experience를 distributed 데이터베이스에 집계한다. 이에 전체 메모리 용량은 𝑁𝑎𝑐𝑡와 독립적이며, 추가 통신 overhead를 희생하면서 원하는 대로 확장이 가능하긴 하다.
Learner
Gorila에는 𝑁𝑙𝑒𝑎𝑟𝑛개의 learner가 존재한다. 각 learner는 actor와 같이 Q-Network의 복제본을 포함하고 있으며, 그 역할은 Q-Network 파라미터의 loss를 계산하는 것이다. 각 learner 업데이트에서 사용하는 샘플은 로컬 또는 글로벌 experience replay memory 𝐷에서 샘플링하며, DQN과 같은 off-policy RL 알고리즘을 적용한다. 계산된 기울기 𝑔𝑖는 파라미터 서버로 전달되며, Q-Network의 파라미터는 파라미터 서버에서 주기적으로 업데이트된다.
Parameter server
Gorila 아키텍처는 중앙 파라미터 서버를 사용하여 Q-Network 𝑄(𝑠,𝑎;𝜃+)의 distributed representation을 유지한다. 파라미터 벡터 𝜃+는 𝑁𝑝𝑎𝑟𝑎𝑚개의 머신으로 서로 분리되어있으며, 각 머신은 파라미터의 일부에 업데이트를 적용하는 일을 담당한다. 파라미터 서버는 learner로부터 기울기를 수신하고,asynchronous stochastic gradient descent 알고리즘을 사용하여 파라미터 벡터 𝜃+를 수정한다.
이에 따라 Gorila 아키텍처는 네 종류의 번들로 구성되어 있으며, 번들 간의 유일한 통신은 파라미터를 통해서 이루어진다. Learner는 자신의 기울기를 파라미터 서버로 전달하고, actor와 learner의 Q-Network는 주기적으로 파라미터 서버에 동기화된다.
Gorila DQN
Gorila 아키텍처에 DQN 알고리즘을 도입한 모델이다. 우선 DQN 알고리즘은 Q-Network의 두 복사본, 즉 파라미터 𝜃가 있는 online Q-Network와 파라미터 𝜃−가 있는 target Q-Network를 활용한다. Gorila 아키텍처에서는 우선 파라미터 서버는 파라미터 𝜃+를 유지한다. 그리고 actor와 learner가 매 action step마다 파라미터 서버와 동기화 되는 online Q-Network 𝑄(𝑠,𝑎;𝜃)를 포함하고 있으며, 여기에 learner만 target Q-Network 𝑄(𝑠,𝑎;𝜃−)를 포함한다. Target Q-Network는 중앙 파라미터 서버에서 𝑁 번 업데이트될 때마다 𝜃+로 learner가 업데이트된다.
또한 DQN 알고리즘과 동일한 기울기를 생성하지만, 네트워크에 직접 적용되지 않고 파라미터 서버로 전달된다. 그런 다음 파라미터 서버는 많은 learner로부터 누적된 업데이트를 적용하게 된다.
아래 실험에서 Gorila DQN은 𝑁𝑝𝑎𝑟𝑎𝑚=31 및 𝑁𝑙𝑒𝑎𝑟𝑛=𝑁𝑎𝑐𝑡= 100을 사용하였으며, replay memory의 크기는 𝐷= 100만 프레임, 각 learner는 파라미터 서버에서 𝑁 = 60K 업데이트가 수행될 때마다 파라미터 𝜃−를 동기화했다.
Stability
Gorila DQN에서는 추가 기능을 통해 노드가 사라지거나, 네트워크 트래픽이 느려거나, 개별 시스템이 느려지는 경우에 대해 안정성을 보장했다. 하나는 로컬 파라미터 𝜃와 파라미터 서버의 파라미터 𝜃+ 사이의 최대 latency의 threshold를 설정했다. 이 threshold보다 오래된 기울기는 파라미터 서버에 의해 삭제된다. 그리고 각 actor와 learner는 현재 관찰 중인 데이터에 대한 절대 DQN loss의 평균 및 표준 편차를 유지하기 위해, 평균에 특정 표준 편차를 더한 것보다 더 큰 절대 손실이 있는 기울기를 삭제한다.
결과
결과 관찰에 앞서 두 가지 유형의 평가 기준이 사용되었다. 첫 번째는 ‘null op’로 DQN이 확립한 프로토콜이다. 이는 훈련된 게임의 30개 에피소드에 대해 평가하는 것이며, 초기 조건의 변화를 보장하기 위해 에이전트에게 제어권을 부여하기 전, null을 반복적으로 수행하거나 아무 작업도 수행하지 않음으로써 임의의 수의 프레임을 건너뛴 이후 에피소드에 대해 평가를 진행하는 것이다. 이후 30개의 에피소드 평균을 활용한다.
두 번째는 ‘human start’로 각 게임마다 사람의 게임플레이에서 샘플링한 무작위 시작점 100개에서 에이전트를 평가하는 것이다. 기존 Atari 에뮬레이터가 완전히 결정적이기 때문에, 에이전트가 얼마나 잘 일반화하는지 평가하는 방식이다. 사람이 획득한 점수는 고려하지 않고 에이전트만 누적한 총점을 평균하여 점수를 구한다.

‘Human start’에서 49개 Atari 게임의 DQN, Gorila 에이전트의 성능이다. 최대 6일 동안 훈련된 Gorila DQN 에이전트와 12~14일 동안 훈련된 DQN 에이전트를 비교했다. Gorila DQN은 기존 DQN 대비 훈련 시간이 절반 가량 줄었음에도, 49개 게임 중 41개 게임에서 DQN보다 성능이 뛰어났다.
마찬가지로 ‘null op’ 평가에서도 Gorila DQN은 49개 게임 중 31개 게임에서 DQN을 능가했다. 이러한 결과는 병렬 훈련이 더 적은 훈련 시간으로 성능을 크게 향상시켰다는 것을 보여준다. 또한, ‘human start’에서 더 나은 결과를 보이는 것은 Gorila DQN이 잠재적으로 보이지 않는 상태를 일반화하는 데 특히 능숙하다고 판단할 수 있다.

‘Human start’ 및 ‘null op’ 평가에 대해 DQN의 개별 평가에 대한 점수로 normalized된 Gorila 에이전트의 성능 결과다. 이를 통해 일반화가 개선되었다는 것을 알 수 있는데, 그 이유 중 하나는 100개의 병렬 actor를 사용하여 Gorila DQN이 보는 state 수가 크게 증가했기 때문이다.

훈련 중에 Gorila DQN의 성능이 어떻게 향상되었는지 관찰한 그래프다. Gorila DQN이 DQN의 성능에 얼마나 빨리 도달했는지(빨간색), Gorila DQN이 human start 평가에서 얼마나 빨리 자체 최고 점수에 도달했는지(파란색) 보여준다. Gorila DQN은 6시간 만에 19개 게임, 12시간 만에 23개 게임, 24시간 만에 30개, 36시간 만에 38개 게임에서 최고 DQN 점수를 넘어섰다. 즉, 훈련 시간이 대략 10배 감소한 효과를 보였다. 또한 일부 게임에서는 Gorila DQN이 이틀 이내에 최고 점수를 달성했지만, 대부분의 게임에서는 훈련 시간이 길어짐에 따라 성능이 계속 향상되었다.
Reference
논문 링크 : https://arxiv.org/abs/1507.04296
'딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| [RL] AlphaGO (1) | 2024.12.04 |
|---|---|
| [RL] A3C (1) | 2024.11.27 |
| [RL] Off-Policy Actor-Critic (3) | 2024.11.25 |
| [RL] Dueling DQN (1) | 2024.11.24 |
| [RL] PER (0) | 2024.11.23 |