키워드
1. 여러 에이전트를 비동기적으로 학습시켜 효율성을 높이는 A3C 알고리즘 제안. Synchronous 학습의 단점을 극복하고 더 빠르고 안정적인 학습을 가능하게 함.
2. "Asynchronous Methods for Deep Reinforcement Learning"
3. A3C, Asynchronous, 1-step Q-Learning, n-step Q-Learning
Asynchronous (비동기)
초기 online RL 에이전트는 관찰한 데이터를 순차적으로 update하여, 강한 상관 관계를 보이는 문제가 있다. 이 문제를 데이터를 메모리에 저장한 후 이후 랜덤 샘플링을 통해 데이터를 얻는 experience replay 방식을 통해 해결하였다. 다만 experience replay의 단점은 interaction마다 많은 메모리와 계산을 사용하며, 이전 policy에 의해 생성된 데이터에 의해 update 된다는 것이다.
이에 asynchronous gradient descent를 사용하는 개념적으로 간단하고 가벼운 프레임워크를 고안했다. 이는 experience replay 대신, 여러 환경 인스턴스에서 병렬로 구성된 여러 에이전트를 asynchronous 방식으로 실행한다. 이 병렬 처리는 주어진 time step에서 다양한 state를 경험하게 되기 때문에 상관성을 줄일 수 있다.
이를 바탕으로 네 가지 기존 알고리즘의 asynchronous 버전을 제시하며, 네 가지 방법 모두 안정적인 훈련을 보였다. 또한 이전 접근 방식은 GPU와 같은 하드웨어에 크게 의존하지만, asynchronous 버전은 표준 멀티 코어 CPU를 갖춘 단일 시스템에서 실행 가능하다. 이를 통해 훨씬 짧은 시간에 훨씬 적은 리소스를 사용하여 더 나은 성능을 보인다.
Reinforcement Learning
각 time step에서 환경과 상호 작용하는 일반적인 reinforcement learning은 아래 단계에 따라 수행된다.
- 각 단계 𝑡에서 에이전트가 state 𝑠𝑡를 받는다.
- Policy 𝜋에 따라 가능한 action 집합 𝒜 에서 action 𝑎𝑡를 선택한다.
- 이후 에이전트는 다음 state 𝑠𝑡+1을 받고 reward 𝑟𝑡를 받는다.
- 최종(terminal) state에 도달할때까지 과정을 반복한다.
Reward 𝑅𝑡는 discount factor 𝛾를 적용한 time step 𝑡의 총 누적 reward를 의미하며, 에이전트의 목표는 각 state 𝑠𝑡에서 예상 reward를 최대화하는 것이다. Action value 𝑄𝜋(𝑠,𝑎)는 state 𝑠에서 policy 𝜋을 따라 action 𝑎을 선택했을때 예상 reward이며, optimal value function 𝑄*(𝑠,𝑎)는 state 𝑠 및 action 𝑎에 대해 달성할 수 있는 최대 action value를 의미한다. 그리고 𝑉𝜋(𝑠)는 단순히 state 𝑠에서 action 𝑎와 상관없이 policy 𝜋에 대한 예상 reward를 의미한다.
Value-based
Value-based model-free 강화 학습 방법에서는 Neural Network와 같은 function approximator를 사용하여 action value function을 표현한다. 파라미터 𝜃를 사용하여 𝑄(𝑠,𝑎;𝜃)로 근사하며, 이러한 알고리즘의 예시로 Q-learning이 있다. 이는 optimal action-value function인 𝑄*(𝑠,𝑎)로 𝑄(𝑠,𝑎;𝜃)를 직접적으로 근사화하는 것을 목표하며, loss는 다음과 같이 정의할 수 있다.

위 방법은 one-step return 𝑟+𝛾max𝑎′𝑄(𝑠′,𝑎′;𝜃) 으로 action value 𝑄(𝑠,𝑎)를 update하므로 one-step Q-learning이라고 한다. 이 방식의 한 가지 단점은 reward r 이 reward를 가져온 state-action 쌍 𝑠,𝑎에만 직접적인 영향을 미친다는 것이다. 다른 state-action 쌍의 값은 update된 value 𝑄(𝑠,𝑎)을 통해 간접적으로만 영향을 받는다. 그리고 관련된 이전 state-action에 reward를 전파하려면 많은 업데이트가 필요하하여 학습이 느려질 수 있다.
이에 보상을 더 빠르게 전파하는 다른 방법은 𝑛-step Q-learning이 있다. 이는 𝑄(𝑠,𝑎)가 𝑛-step의 return을 통해 update 되는 것으로, 단일 보상 𝑟이 𝑛-step 이전 state-action 쌍의 값까지 직접 영향을 미치게 된다. 이를 통해 학습 프로세스를 잠재적으로 더 효율적으로 구성할 수 있다.
Policy-based
Policy-based model-free 방법은 policy 𝜋(𝑎|𝑠;𝜃)을 직접 parameterized하고, 𝔼[𝑅𝑡]에 대한 gradient ascent를 수행하여 파라미터 𝜃를 update한다. 예시로 REINFORCE 알고리즘 계열을 들 수 있다. 이는 unbiased gradient를 활용하여 파라미터를 update하며, baseline 𝑏𝑡(𝑠𝑡)를 통해 분산을 줄이는 방식을 사용한다. Baseline은 주로 value function의 학습된 추정치 𝑉𝜋(𝑠𝑡)가 사용된다.

만약 function approximate를 baseline으로 사용하는 경우, policy gradient를 조정하는 데 𝑅𝑡−𝑏𝑡에 state 𝑠𝑡에 대한 action 𝑎𝑡의 advantage를 활용한다. 이는 𝐴(𝑎𝑡,𝑠𝑡)=𝑄(𝑎𝑡,𝑠𝑡)−𝑉(𝑠𝑡)로 표현 가능한데, 𝑅𝑡가 𝑄𝜋(𝑎)의 추정치이기 때문이다. 이 접근 방식은 policy 𝜋가 actor고 baseline 𝑏𝑡는 critic인 actor-critic 아키텍처로 볼 수 있다.
Asynchronous Reinforcement Learning Framework
네 가지 기존 알고리즘을 기반으로 asynchronous 버전을 적용하였다. On-policy 방식의 actor-critic과 off-policy 방식의 Q-learning 모두 적용할 수 있는 방식다. 주요한 디자인 아이디어는 먼저 Gorila 프레임워크와 유사하게 asynchronous actor-learner를 사용하지만, 별도의 머신과 파라미터 서버를 사용하는 대신 단일 머신에서 여러 CPU 스레드를 사용한다. 이를 통해 통신 비용을 제거할 수 있다. 그리고 병렬로 실행되는 여러 actor-learner가 환경의 서로 다른 부분을 exploration할 가능성이 있다. 즉, 다양성을 극대화하기 위해 각 actor-learner마다 서로 다른 exploration policy을 사용하며, 서로 다른 스레드에서 서로 다른 exploration policy가 실행된다.
이렇게 병렬로 구성된 여러 actor-learner가 파라미터에 업데이트하는 방식은 온라인 업데이트를 적용하는 단일 에이전트보다 상관 관계가 더 적다. DQN 훈련 알고리즘에서 experience replay가 수행하는 안정화 역할을 다양한 exploration policy가 대신 수행한다고 볼 수 있다. 또한 병렬 actor-learner의 수에 따라 선형적인 훈련 시간 감소 효과가 있으며, experience replay가 없기 때문에 SARSA, actor-critic과 같은 on-policy 강화 학습 방법을 사용하여 Neural Network를 안정적으로 훈련할 수 있다.
Asynchronous 1-step Q-learning
각 스레드는 개별로 복사해둔 환경과 상호 작용하고, 각 단계에서 Q-learning loss의 기울기를 계산한다. 다만 backprop 전에 여러 time step에 걸쳐 기울기를 누적하는데, 이는 미니 배치를 사용하는 것과 유사한 효과를 유도한다. 이렇게 하면 여러 actor-learner가 서로의 update를 덮어쓸 가능성이 줄어든다. 또한 데이터 효율성과 계산 효율성의 trade-off를 적절하게 조절하는 기능도 제공한다.
마지막으로, 각 스레드에 서로 다른 exploration policy을 사용하면 robust가 향상된다. 이러한 방식으로 exploration에 다양성을 추가하여 성능이 향상을 기대할 수 있다.
Asynchronous 1-step SARSA
Asynchronous 1-Step Q-learning과 동일하다. 다만 𝑄(𝑠,𝑎)에 대해 다른 target “𝑟+𝛾𝑄(𝑠′,𝑎′;𝜃−)”를 사용한다.
Asynchronous n-step Q-learning
업데이트를 계산하기 위해 먼저 𝑡𝑚𝑎𝑥 step 혹은 terminal state에 도달할 때까지 exploration policy를 사용하여 action을 선택한다. 이를 통해 에이전트는 마지막 transition에서 𝑡𝑚𝑎𝑥 reward를 받는다. 이후 알고리즘은 마지막 transition부터 발생한 각 state-action 쌍에 대한 n-step Q-learning 기울기를 계산한다.
Asynchronous Advantage Actor-Critic
A3C(Asynchronous Advantage Actor-Critic)라고 부르는 알고리즘은 앞선 asynchronous n-step Q-learning과 동일한 n-step reward를 통해 policy와 value function을 모두 업데이트한다. 또한 매 𝑡𝑚𝑎𝑥 action 이후 혹은 terminal state에 도달할 때 업데이트한다.
Policy 𝜋(𝑎𝑡|𝑠𝑡;𝜃)의 파라미터 𝜃와 value function 𝑉(𝑠𝑡;𝜃𝑣)의 파라미터 𝜃𝑣는 일반성을 위해 별개로 표시되지만, 실제로는 일부 파라미터를 항상 공유한다.일반적으로 policy에 대해 하나의 softmax 출력과 𝑉에 대해 하나의 linear 출력하고, 나머지 hidden 레이어가 공유되는 CNN을 사용하기 때문이다.

또한 objective 함수에 policy 𝜋의 엔트로피를 추가하면 deterministic policy에 대한 조기 수렴을 억제하여 exploration이 향상된다. 이에 따른 전체 objective 함수의 기울기는 위와 같으며, 𝐻는 엔트로피를 의미한다.
결과
Atari

Atari 게임에서 평가한 결과다. 네 가지 asynchronous 방법 모두 성공적으로 훈련되었으며, GPU에서 훈련된 DQN 알고리즘에 비해 빠르게 학습하는 경향을 보인다. 또한 일부 게임에서 n-step 방법이 1-step 방법보다 더 빠르게 학습한다는 것을 확인하였으며, policy-based A3C가 세 가지 value-based 방법보다 훨씬 뛰어난 성능을 보였다.
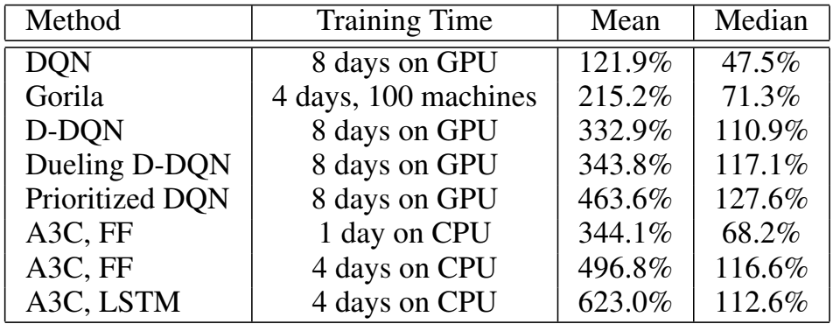
위 표는 A3C와 다른 모델로 얻은 평균 및 중앙값 점수다. A3C 아키텍처의 변형으로 최종 hidden 레이어 뒤에 256 LSTM 셀이 있는 recurrent 에이전트를 추가로 고려했다. A3C는 GPU를 사용하지 않고 16개의 CPU 코어만 사용하면서, 다른 방법에 비해 훈련 시간을 절반으로 단축하고 평균 점수를 크게 향상시켰다. 단 하루의 훈련 후에 A3C는 Dueling Double DQN의 평균 점수와 일치하고, Gorila의 중앙 점수와 동등 수준을 달성한다.
TORCS

TORCS는 Atari 보다 더 사실적인 그래픽을 제공하며, 에이전트가 자동차 제어를 학습한다. 상대 봇의 유무와 속도가 느리거나 빠른 자동차의 조합으로 구성된 네 가지 다른 설정을 사용하여 평가하였다. A3C는 가장 성과가 좋은 에이전트였으며 약 12시간의 교육을 통해 네 가지 게임 구성에서 사람의 75% ~ 90% 수준의 성능을 보였다.
MuJoCo
MuJoCo 물리 엔진은 action space가 연속적인 task를 해결하기 위해 활용된다. 그 중 조작, 이동이 많이 포함된 contact dynamic을 갖춘 rigid body 물리 영역을 평가했다. 모든 문제에서 물리적 state나 픽셀 이미지를 입력으로 사용하였으며, A3C는 일반적으로 몇 시간 이내에 좋은 솔루션을 학습했다.
Labyrinth
Labyrinth라는 새로운 3D 환경에서 A3C를 통해 실험을 수행하였다. 이는 에이전트가 무작위로 생성된 미로에서 보상을 찾는 방법을 학습하는 환경이다. 각 에피소드가 시작될 때 에이전트는 방과 복도가 무작위로 구성된 미로에 배치된다. 미로에는 보상으로 사과와 포털이라는 두 가지 유형이 존재하며, 사과를 따면 1, 포털에 입장하면 10의 보상을 받는다. 에이전트의 목표는 제한 시간 내에 최대한 많은 포인트를 수집하는 것으로 A3C LSTM 에이전트를 학습하였다. 위 결과를 통해 시각적 입력만 사용하여 임의의 3D 공간을 탐색하기 위한 합리적인 전략을 학습했음을 알 수 있다.
Scalability and Data Efficiency

Actor-learner의 수에 따라 훈련 시간과 데이터 효율성이 어떻게 변하는지 살펴봄으로써 프레임워크의 효율성을 분석할 수 있다. 위 표는 단일 스레드를 사용하여 도달하는 데 필요한 시간을 𝑛개의 스레드를 사용할 때 고정 기준 점수에 도달하는 데 필요한 시간으로 나눈 값으로 정의된 값의 결과다. 네 가지 방법 모두 다중 스레드를 사용하여 상당한 속도 향상을 달성하였다. 즉, 제안된 프레임워크가 확장됨에 따라 리소스를 효율적으로 사용한다는 것을 알 수 있다.

다양한 수의 actor-learner의 데이터 효율성 비교를 위한 훈련 프레임 수에 대한 평균 점수의 차트다. 이를 통해 다중 스레드의 긍정적인 효과를 관찰할 수 있다. 아래 차트는 훈련 프레임 수를 실제 소요 시간(wall-clock time)에 따른 평균 점수 차트다.

Robustness and Stability

위는 A3C의 50가지의 다양한 learning rate와 random initialization을 통해 얻은 점수의 scatter plot으로, 이를 통해 안정성과 견고성을 분석할 수 있다. 대부분의 게임에서 다양한 learning rate가 좋은 점수를 얻는다. 즉, 이 방법이 안정적이고 학습 후에 collapse되거나 diverge 되지 않음을 나타낸다.
최종적으로 병렬 actor-learner를 사용하는 것이 value-based 방법보다 안정적인 결과를 보인다는 것을 알 수 있다. 이는 DQN의 experience replay 없이도 안정적인 online Q-learning이 가능함을 의미한다. 뿐만 아니라 experience replay를 asynchronous 강화 학습 프레임워크에 통합하면 오래된 데이터를 재사용하여 데이터 효율성을 크게 향상시킬 수 있다. 이를 통해 모델을 업데이트하는 것보다 환경과 상호 작용하는 것이 더 많은 비용이 드는 TORCS와 같은 도메인에서 훨씬 더 빠른 훈련 시간으로 이어질 수 있다.
Reference
논문 링크 : [1602.01783] Asynchronous Methods for Deep Reinforcement Learning (arxiv.org)
'딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| [RL] ACER (1) | 2024.12.11 |
|---|---|
| [RL] AlphaGO (1) | 2024.12.04 |
| [RL] Gorila (0) | 2024.11.26 |
| [RL] Off-Policy Actor-Critic (3) | 2024.11.25 |
| [RL] Dueling DQN (1) | 2024.11.24 |