키워드
1. 상태 가치와 행동 우도를 분리한 듀얼 네트워크 구조를 도입하여 Q-value 추정의 정확성을 높임. 이로 인해 정책의 학습 효율성 및 성능이 향상됨.
2. "Dueling Network Architectures for Deep Reinforcement Learning"
3. Dueling DQN, Dueling network, DQN
Dueling DQN
Dueling DQN은 model-free 강화 학습을 위한 새로운 신경망 아키텍처를 활용한 구조다.Dueling network는 두 개의 estimator를 사용한다. 하나는 state value 함수이고 다른 하나는 state-dependent action advantage function이다. 이러한 분해의 장점은 기본 강화 학습 알고리즘을 변경하지 않고 학습을 일반화할 수 있다는 것이다. 특히 value가 유사한 action이 많은 경우 더 나은 policy를 얻는 경향을 보인다.

Architecture를 간단히 살펴 보면, convolution feature 모듈을 공유하면서 value와 advantage를 나타내는 두 개의 스트림으로 구성된다. 이후 두 스트림은 state-action value function 𝑄의 추정치를 생성하기 위해 결합된다. 직관적으로 dueling DQN은 각 state에 대한 각 action의 효과를 학습할 필요 없이, 어떤 state가 가치가 있는지 혹은 없는지 학습할 수 있다. 이는 해당 action이 환경에 영향을 미치지 않을때 특히 유용하다.
위 이미지는 이를 설명하기 위해 서로 다른 두 time step에 대한 value 및 advantage saliency 맵이다. 첫 번째 단계에서 우리는 value 스트림이 도로, 특히 새 자동차가 나타나는 지평선에 주의를 기울이는 것을 알 수 있다. 하지만 해당 시점의 advantage 스트림은 시각적 입력에 많은 주의를 기울이지 않는다. 왜냐하면 앞에 자동차가 없을 때는 행동 선택이 실질적으로 보상에 영향을 주지 않기 때문이다. 두 번째 time step에서는 바로 앞에 자동차가 있기 때문에, advantage 스트림이 action을 선택하기 위해 주의를 기울이게 되는 것을 알 수 있다.
이를 통해 Value 스트림은 미래의 성능에 영향을 주는 대상에 주목합니다. 이에 점수 판도에 주목합니다. 반면 advantage 스트림은 충돌 경로에 있는 자동차, 즉 즉각적인 점수에 영향을 주는 대상에 더 관심을 갖습니다.
Algorithm
게임 환경에서 에이전트는 시간 단계 𝑡에서 게임 화면 𝑠𝑡를 인식한다. 그런 다음 action space 특정 action을 선택하고, 이후 게임 emulator에서 생성된 reward 𝑟𝑡를 얻는다. 이 과정에서 에이전트는 누적 reward를 최대화하는 방향으로 학습되며, 최적의 action-value는 𝑄¡(𝑠,𝑎)=max𝜋𝑄𝜋(𝑠,𝑎)로 정의된다. 여기서 𝑄 함수는 Bellman 방정식을 따른다.
Advantage function은 value와 𝑄 function에 관한 값이다. 𝑄 function은 해당 state에서 특정 action을 선택하는 가치를 측정하기 때문에, advantage function은 Q function에서 state value을 빼서 각 행동의 중요성에 대한 상대적 척도를 얻는다.
Deep Q-Network
Value function은 고차원 문제를 다루기 때문에, DQN은 파라미터 𝜃를 통해 𝑄(𝑠,𝑎;𝜃)로 근사하여 문제를 최적화한다. 이 접근 방식은 state와 reward가 환경에 의해 생성된다는 점에서 model-free 방식이며, online policy의 학습을 위한 state와 reward가 다른 behaviour policy(ex) epsilon greedy)를 통해 획득되므로 off-policy 특성을 가지고 있다. 또한 성능 개선을 위해 target network, experience replay를 활용한다. 이에 대한 Loss는 아래로 표현할 수 있다.
Double Deep Q-Network
DQN에서 max operator를 통해 동일한 value를 사용하여 action을 선택하고 평가합니다. 이는 지나치게 optimize된 value를 추정하게 되고, 이 문제를 완화하기 위해 Double DQN은 action selection과 value estimation을 분리하였다. 이에 따른 변경된 target은 아래와 같다.
Prioritized Experience Replay
DDQN 위에 추가된 개선 알고리즘이다. 핵심 아이디어는 예상되는 학습 진행률이 높은 experience의 replay 확률을 높이는 것이다. 이전 uniform한 experience replay와 비교하여 대부분의 게임에서 학습 속도가 빨라지고 최종 policy 품질이 향상 되었다.
Dueling Network
Dueling 네트워크의 핵심 개념은 많은 state에서 선택한 action의 value를 추정하는 것이 불필요하다는 것이다. 물론 일부 state에서는 어떤 action을 취해야 하는지 아는 것이 가장 중요하지만, 대부분의 state에서는 action이 상황에 영향을 미치지 않는다. 다만, 특별히 부트스트래핑 기반 알고리즘의 경우 모든 state에 대해 매우 중요하다.
Dueling network의 원래 DQN과 같이 convolution으로 low-level이 구성되어 있고, 이후 FC 레이어가 value와 advantage function을 추정하는 두 스트림으로 분기된다. 이후 두 스트림이 결합되어 단일 𝑄 function을 구하며, 이전 모델들과 같이 action 수와 동일한 크기의 벡터로 구성되어 있다. 최종적으로, 기존 모델과 동일한 입력-출력 인터페이스를 갖추고 있기 때문에, DDQN 및 SARSA와 같은 기존의 많은 알고리즘을 재사용할 수 있다.
여기서 𝑄를 출력하기 위해 두 스트림을 결합하는 방법을 신중하게 설계해야 한다. 먼저 한 스트림은 스칼라 𝑉(𝑠;𝜃,𝛽)을 출력하고, 다른 스트림은 |𝒜|차원 벡터 𝐴(𝑠,𝑎;𝜃,𝛼)을 출력한다고 볼 수 있다. 𝜃는 conv 레이어의 파라미터를 나타내고, 𝛼과 𝛽는 두 스트림의 각 FC 레이어 파라미터를 나타낸다. Advantage의 정의를 사용하여 다음과 같이 결합 모듈을 구성할 수 있다. 이 식은 모든 (𝑠,𝑎) 인스턴스에 적용되기 때문에, 스칼라 𝑉(𝑠;𝜃,𝛽), |𝒜| 만큼 복제해야 한다.
다만 위 식은 𝑄에 대해 𝑉 및 𝐴를 복구할 수 없는 unidentifiable한 특성이 있다. 만약 𝑉(𝑠;𝜃,𝛽)에 특정 상수를 추가하고 𝐴(𝑠,𝑎;𝜃,𝛼)에서 동일한 상수를 빼도, 이 상수는 상쇄되어 동일한 𝑄 값이 출력된다. 이러한 특성은 실제로 열악한 성능을 유발한다.
이 문제를 해결하기 위해 advantage function에서 선택한 작업이 0이 되도록 강제했다. 이를 통해 𝑎*에 대해 𝑄(𝑠,𝑎*;𝜃,𝛼,𝛽)=𝑉(𝑠;𝜃,𝛽)를 구할 수 있다. 즉, optimal action 기준으로 advantage가 없기 때문에, 𝑉(𝑠;𝜃,𝛽) 스트림만 남게 되고 이는 value function을 추정한다. 이를 통해 다른 optimal이 아닌 action에서도 𝑉(𝑠;𝜃,𝛽)는 value function만 추정하고, 𝐴(𝑠,𝑎;𝜃,𝛼) 스트림은 advantage function만 추정할 수 있게 된다.
Max 연산자를 평균으로 대체한 버전이다. 이 버전은 off-target으로 인해 𝑉와 𝐴의 원래 의미는 손실되지만, 최적화의 안정성이 향상되는 효과를 얻을 수 있다. 왜냐하면 advantage가 optimal action보다 평균을 기준으로 업데이트 되는 것이 더욱 빠르기 때문이다.
최종적으로 이 방식을 통해 최종 𝑄 출력이 identifiable하게 되었다. 그리고 기존 𝑄-Network와 마찬가지로 단일 backprop만 수행하며, 𝑉(𝑠;𝜃,𝛽)와 𝐴(𝑠,𝑎;𝜃,𝛼)는 특별한 알고리즘 수정 없이 자동으로 계산된다.
주어진 state에 대한 𝑄 값 간의 차이는 𝑄의 크기에 비해 매우 작은 경우가 많다. 예를 들어, Seaquest 게임에서 DDQN을 사용하여 학습한 후, 방문한 state의 가장 큰 𝑄 값을 가지는 action과 그 다음 action의 차이는 대략 0.04인 반면, 전체 action의 평균 𝑄 값은 약 15이다. 이런 차이는 약간의 noise만으로 action이 재정렬되어 policy를 변동시킬 수 있다. 하지만 별도의 advantage 스트림을 갖춘 dueling 아키텍처는 이러한 현상에 강력하다.
결과
Policy Evaluation
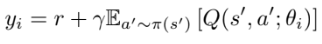
간단한 환경에서 dueling 아키텍처의 policy evaluation 성능을 측정하고자 한다. Temporal difference learning을 통해 Q 값을 학습하였으며, behavior policy 𝜋에서 위 식을 최적화하여 state-action value 𝑄𝜋(⋅,⋅)를 추정하는 방식이다.
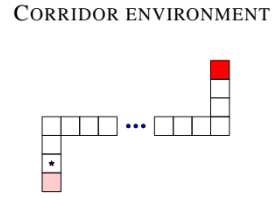
𝑄 를 평가하기 위한 환경은 모든 (𝑠,𝑎)에 대해 정확한 𝑄𝜋(𝑠,𝑎) 값을 개별적으로 계산할 수 있도록 구성되었다. 3개의 복도로 구성되어 있으며, 에이전트는 왼쪽 하단에서 시작하여 보상을 얻으려면 오른쪽 상단으로 이동해야 한다. 이동 및 정지로 구성된 5가지 action을 사용하며, 수직 방향으로 10개의 state가 있고 수평 방향으로 50개의 state가 있다. Behavior policy 𝜋는 𝜖-greedy policy를 사용했다.
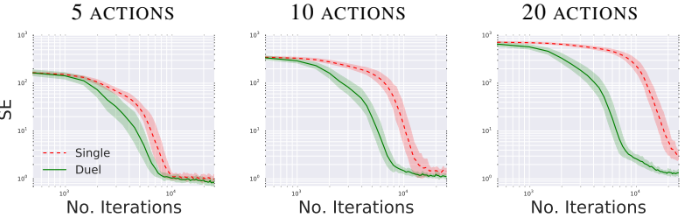
각각 5개, 10개, 20개의 action이 있는 환경에서 단일 스트림 𝑄 아키텍처와 dueling 아키텍처를 비교한 결과다. 10개, 20개의 action은 기존 space에 정지을 추가하였다. 평가 지표는 실제 state value와 Squared-Error이다. 5가지 action을 사용할때는 두 아키텍처가 거의 동일한 속도로 수렴하지만, 작업 수를 늘리면 dueling 아키텍처가 기존 𝑄 네트워크보다 더 나은 성능을 발휘한다.
이는 dueling network의 𝑉(𝑠;𝜃,𝛽) 스트림이 𝑠의 수많은 유사한 action으로부터 일반적인 value를 학습하여 더 빠른 수렴으로 이어지기 때문이며, 큰 action space을 가진 많은 작업에 매우 유망한 결과로 볼 수 있다. 즉, dueling DQN에서 value 스트림을 더 자주 업데이트하면 𝑉에 더 많은 리소스가 할당되므로, Q 에 대한 더 나은 근사가 가능하다.
Atari
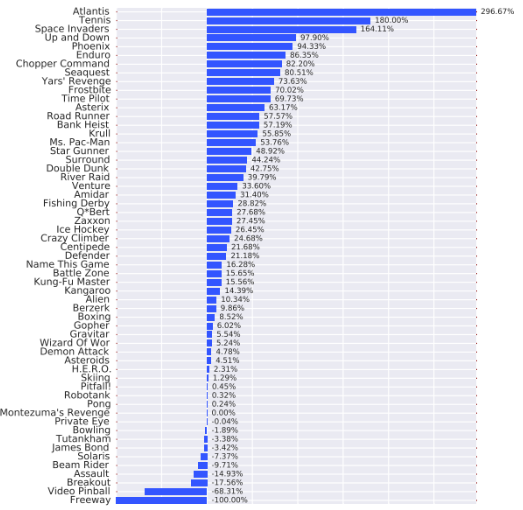
단일 스트림의 Double DQN과 Dueling DQN의 성능 비교 결과다. 두 아키텍처는 동일한 하이퍼파라미터를 사용했다. 다만 Dueling DQN은 두 개의 스트림으로 backprop이 마지막 conv 레이어에 전달되므로, 마지막 conv 레이어에 들어가는 그래디언트의 크기를 1/√2로 조정하였다. 또한, 그라디언트의 norm이 10보다 작거나 같도록 클리핑하였다. 이는 Deep RL에서는 흔히 사용되지는 않지만, recurrent network에서 자주 사용되는 기법이다. 이는 gradient exploding 을 방지하기 위한 기법이다.
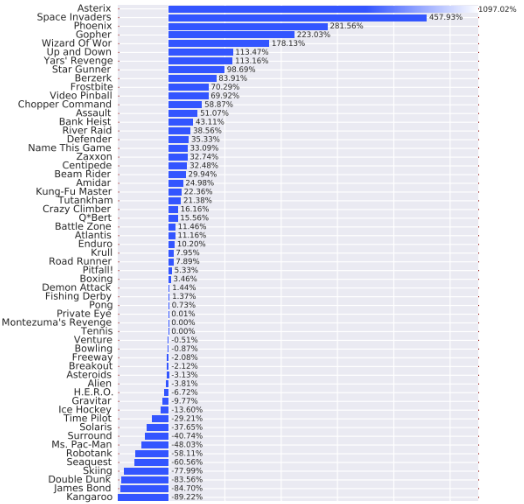
평가 기준은 사람의 점수와 baseline 점수 중 더 높은 점수에 대한 비율로 측정되었다. 이를 통해 기존 방식보다 전반적으로 훨씬 더 나은 성능을 발휘한다는 것을 알 수 있다. 또한 아래 표와 같이 Clipping이 성능 개선에 기여했다는 사실도 알 수 있다. 이를 통해 아키텍처의 변화와 clipping이 함께 기여했다고 판단할 수 있다.
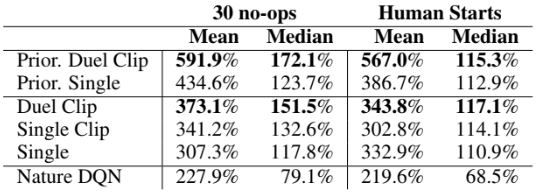
Duel Clip(Dueling DQN + Clipping)은 75.4%의 게임에서 Single Clip보다 더 나은 성능을 발휘하였으며, 18개의 action이 있는 게임 중에서 Duel Clip은 86.6%의 게임에서 더 좋은 성능을 보였다. 또한 Duel Clip는 57개 게임 중 42개 게임에서 사람 수준의 성능을 달성하였다.
에이전트는 Atari 환경의 고유한 시작점을 바탕으로 단순히 일련의 작업을 기억함으로써 좋은 성능을 달성하는 방법을 배울 수 있다. 이에 각 게임마다 사람의 trajectory 중 임의 100개의 시작점을 샘플링한 뒤, 해당 지점에서 에이전트를 평가하였다. 이 Human Starts 지표에서 Duel Clip은 다시 한번 단일 스트림보다 뛰어난 성능을 보였다.
With PER
위는 PER을 결합한 뒤, 기존과 같은 방식으로 성능을 평가한 결과다. PER과 dueling 아키텍처는 서로 매우 다른 영역을 다루기 때문에 둘의 조합은 유망한 결과를 얻는다. 이전 표에서 Prior은 PER을 사용했다는 의미로, Prior.Duel Clip이 Prior.Single과 비교해 봤을때, 더욱 우수한 성능을 보인다는 것을 알 수 있다.
Reference
논문 링크 : https://arxiv.org/abs/1511.06581
'딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| [RL] Gorila (0) | 2024.11.26 |
|---|---|
| [RL] Off-Policy Actor-Critic (3) | 2024.11.25 |
| [RL] PER (0) | 2024.11.23 |
| [RL] Double DQN (0) | 2024.11.22 |
| [RL] DQN (improvements) (0) | 2024.11.21 |