키워드
1. "Human-level control through deep reinforcement learning"
2. DQN의 여러 가지 개선사항을 소개하여 안정성과 성능을 높임. 주요 개선사항으로는 경험 재플레이, 타겟 네트워크 사용, 보상 클리핑 등이 포함됨.
DQN (improvements)
논문 내용을 확인하기에 앞서, 앞선 포스팅 DQN과 거의 동일한 내용을 포함하고 있다. 약간의 차이가 있으며 이에 대한 요약은 아래와 같다. 일반적으로 DQN이라 하면 이전 2013년 논문보다 이 논문을 지칭한다.
- 기여 : 첫 번째 논문은 DQN을 처음 소개하며 가능성을 입증하는데 중점을 두었다면, 두 번째 논문은 DQN의 성능을 개선하고 Atari 게임에서 인간 수준의 제어를 달성하는 데 중점을 둔다.
- 발전: 두 번째 논문에서는 첫 번째 논문에서 제안한 DQN에 target 네트워크 등의 기법을 도입하여 더 안정적이고 효율적인 학습을 가능하게 했다.
- 성과: 두 번째 논문에서 첫 논문보다 많은 게임에서 인간 수준의 성능을 달성하였다.
Reinforcement learning은 agent가 environment 제어하는 방법을 최적화하는것이다. 현실 세계의 수준의 복잡성에 대해 agent는 고차원 입력으로 부터 효율적인 representation을 얻고, 과거 경험을 토대로 새로운 상황을 generalize 해야한다. 사람은 이를 강화 학습과 hierarchical 감각 처리 시스템(sensory processing systems)을 통해 처리한다.
Agent는 사람과 달리 hand-crafted된 feature나, 저차원 state를 활용하여 구현되었다. DQN은 이보다 더 발전되어 deep neural network을 바탕으로 고차원 입력으로부터 end-to-end reinforcement learning을 통해 agent를 구현한다. Neural Network는 여러 레이어를 통해 더욱 추상적인 representation을 활용하고, 고차원 입력으로부터 객체라는 개념을 학습할 수 있게 되었다. 이를 통해 입력에 존재하는 상관관계를 파악하고 자연스러운 변형에 대해 robust 해졌다.
Algorithm
Agent는 environment와 observation, action, reward로 상호 작용한다. 이 과정에서 agent의 목표는 미래의 누적 보상을 최대화하는 action을 선택하는 것이며, optimize action-value function으로 정의되고 Bellman equation을 따른다. DQN은 CNN을 바탕으로 iterative update를 통해 최적의 action-value function을 추정한다. 다만 전체 기대값을 계산하는 대신, SGD 방식으로 최적화를 진행한다. 이는 매 time step 마다 가중치를 업데이트하고, 단일 샘플로 기대치를 대체하는 것이다. 즉, reward function r, transition proba p가 아닌 샘플을 활용하기 때문에 model-free 한 특성이 있으며, state를 적절히 탐색하는 behavior distribution을 통해 greedy strategy a~argmax를 학습하는 off-policy 특성을 가지고 있다.
하지만 이렇게 신경망과 같은 non-linear function approximator를 사용하여 action-value(Q) function을 나타내는 경우 학습이 불안정하다. 그 원인으로 time step에 따라 얻은 샘플 간 “observation 순서에 따른 correlation”, Q에 대한 작은 업데이트가 policy를 크게 변경시키고 이에 따른 “데이터 분포의 변경”, “action value와 target value 간의 correlation” 등이 있다.
이러한 문제를 해결하기 위해 experience replay를 사용한다. 이는 샘플을 무작위로 추출하여 observation 순서에 따른 correlation를 제거한다. 그리고 target network를 사용함으로써, 특정 주기로 update되는 target을 통해 action-value(Q)를 조정하는 iterative update를 사용한다. 이를 통해 학습이 안정적이고 target 과의 correlation을 제거할 수 있다.
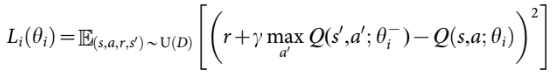
이를 구현하기 위해 먼저 Q(s,a;θ)를 parameterize 한다. 이후 experience replay를 수행하기 위해 agent의 step 별 experience (st,at,rt,st+1)를 저장한다. 이후 무작위로 추출된 experience (s,a,r,s’)를 Q-learning update에 활용하며 위와 같은 손실 함수를 사용한다. Iter i 마다 Bellman equation의 MSE를 줄이도록 θ를 학습하는데, 여기서 θ는 Q-network의 파라미터이며 θ-는 target network의 파라미터이다.
Target network
Neural Network의 안정성을 더욱 향상시키기 위해 별도의 target 네트워크를 사용한다. 이는 Q-learning update에서 사용되는 target yi를 생성하는 네트워크이다. 이 네트워크는 특정 C step 마다 update 되며, Q-Network를 복제하여 파라미터가 변경되게 된다.
기존 Q-learning은 Q(st,a)를 증가하면서 Q(st+1,a)도 증가한다. 이에 따라 모든 a에 대해 target yi도 증가하게 된다. 이는 policy를 진동하거나 발산하게 만들 수 있다. 하지만 별도의 target 네트워크를 사용하는 경우, target이 이전 파라미터를 통해 생성되기 때문에 update 간 지연이 발생하고, 이로 인해 진동이나 발산이 발생할 가능성이 줄어든다.
Error clip (Huber loss)

손실의 기울기를 -1과 1로 clipping 하는 것은 알고리즘의 안정성에 도움이 된다. 그 이유는 absolute value loss function이 negative value에서는 -1의 기울기, positive value에서는 1의 기울기를 가지고 있으며, clipping을 통해 이에 대응되게 설계할 수 있기 때문이다.
Architecture

먼저, 현재 프레임과 이전 프레임에서 각 픽셀 별 최대 값으로 이미지를 구성한다. 이는 일부 개체는 짝수 프레임에만 나타나고 다른 개체는 홀수 프레임에만 나타나는 게임의 깜빡임을 제어하기 위함으로, Atari 2600이 한 번에 표시할 수 있는 스프라이트 수의 제한으로 인해 발생한다. 이후, RGB 프레임에서 휘도라고도 알려진 Y 채널을 추출하고 84 x 84로 조정한 뒤, m개의 최근 프레임을 스택하여 Q 함수에 대한 입력을 생성한다.
전체 구조는 각 작업에 대해 별도의 출력 단위가 있고, state representation만 신경망에 입력되는 아키텍처가 설계되었다. 이를 통해 각 출력은 개별 action의 예측된 Q 에 대응되며, 주어진 state는 네트워크를 한 번만 통과하여 action을 선택할 수 있다.
훈련
동일한 네트워크 아키텍처, 학습 알고리즘, 하이퍼파라미터가 모든 게임에서 사용되었다. 긍정적인 보상은 1이고 부정적인 보상은 -1로 설정되었다. 그리고 총 5천만 프레임에 대해 훈련되었으며, 가장 최근 프레임 100만 개의 메모리를 experience replay에 사용하였다. 마지막으로 frame-skipping 건너뛰기 기술도 사용되었는데, 이는 k번째 프레임마다 action을 선택하며 건너뛴 프레임에서 반복하는 방식으로 훨씬 적은 계산량을 구현하였다.

위는 평균 점수 및 평균 예측 Q 값에 대한 학습 결과다. 두 가지 학습 지표를 통해 SGD를 사용하여 대규모 신경망을 훈련할 수 있음을 보인다.
결과

DQN을 DQN 이전 게임 별로 성능이 가장 좋은 모델과 비교한 결과다. y축에서 100%는 사람, 0% Random 으로 표시된다. 49개 게임 세트 중 43개의 게임에서 기존 최고의 강화 학습 방법보다 성능이 뛰어난 것을 알 수 있으며, 75%의 게임에서 사람보다 더 뛰어난 성능을 보인다.
특정 게임에서 DQN은 이전 논문에서 한계로 언급된 long-term strategy를 학습한 경우도 발견되었다. Breakout이라는 벽돌깨기 게임에서 agent는 벽 측면에 터널을 파고 공을 통과시키는 최적의 전략을 학습하는 모습을 보였다. 하지만 시간적으로 더 확장된 전략을 요구하는 게임은 여전히 아쉬운 결과를 보였다.

위 결과는 DQN의 개별 핵심 구성 요소를 비활성화하고 이에 따른 성능 감소를 정리한 결과이다. DQN의 모든 요소가 성능에 중요한 요소라는 것을 알 수 있다.

위는 게임 state에 따른 DQN의 마지막 hidden layer를 2차원 t-SNE 시각화한 결과다. 왼쪽 결과를 통해 시각적으로 유사한 상태의 DQN 표현을 인근 지점에 매핑하는 경향이 있지만, 시각적으로 차이가 있어도 예상 보상 측면에서 유사하면 유사한 임베딩을 생성하는 것도 관찰 할 수 있다. 또한 오른쪽 결과는 사람의 플레이(주황색)와 DQN의 플레이를 동일한 방식으로 시각화 한 것으로 사람과 DQN 간 유사한 state에 대해 유사한 임베딩 구조가 있음을 알 수 있다. 이를 통해 DQN이 고차원 입력으로부터 adaptive하게 행동하는 representation을 학습한다는 것을 알 수 있다.

Reference
논문 링크 : https://www.nature.com/articles/nature14236
Huber loss 이미지 : https://tutorials.pytorch.kr/intermediate/reinforcement_q_learning.html
'딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| [RL] Dueling DQN (1) | 2024.11.24 |
|---|---|
| [RL] PER (0) | 2024.11.23 |
| [RL] Double DQN (0) | 2024.11.22 |
| [RL] DQN (2) | 2024.11.20 |
| [RL] Reinforcement Learning 발전 과정 (3) | 2024.11.19 |