키워드
1. Off-Policy 학습에서 Actor-Critic 알고리즘의 샘플 효율성을 높이기 위해, off-policy Critic을 사용하는 방법 제안.
2. "Q-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic"
3. Off-Policy, actor-critic, Q-Prop, monte carlo
Off-Policy Actor-Critic
Model-free 강화 학습은 목표지향적인 sequential 의사 결정을 해결하기 위해 high-level reward만 사용하여 유의미한 결과를 보였다. 또한 Neural Network와 결합하여 hand-crafted feature의 필요성을 줄이고, 고차원 입력으로부터 end-to-end 학습을 통해 policy를 얻었다. 하지만 이 구조는 하이퍼파라미터에 민감하여 자칫 수렴에 실패하는 경우를 보이며, 굉장히 높은 sample complexity(대상 기능을 성공적으로 학습하는 데 필요한 훈련 샘플의 수) 특성이 있으 현실 문제에 적용하기에 한계가 있다. Off-Policy Actor-Critic(Q-Prop) 방법은 여러 RL 알고리즘의 장점을 결합하여 샘플 효율성과 안정성을 모두 갖춘 알고리즘이다.
RL은 크게 on-policy와 off-policy로 구성된다. On-policy는 monte carlo policy gradient가 있으며, 이는 policy와 관련하여 누적 reward을 직접 최대화하는 방식이다. 이러한 알고리즘은 편향되지 않은 기울기를 추정하지만, monte carlo 방식에 의존하며 높은 분산이라는 단점이 있다. 이를 보완하기 위해 매우 많은 수의 샘플이 필요한 경향을 보인다. 하지만 policy gradient 방법의 핵심 문제는 현재 policy에 따른 샘플만 사용할 수 있다는 것이다. 즉, policy에 대한 파라미터를 업데이트한 후에 policy에 따른 experience를 대량으로 수집해야 한다는 의미다. 이는 매우 샘플 집약적으로 비효율적이다.
Off-policy는 experience learning을 통한 temporal-difference learning 방법이 주로 사용되며 현재 policy가 아닌 다른 모든 샘플을 사용한다. 이를 통해 샘플 효율성이 더 높지만, 일반적으로 샘플들이 편향되어 있으며 non-linear function approximator에서 수렴이 보장되지 않는다. 이러한 문제는 실제 실험에서 좋은 결과를 얻기 위해 광범위한 하이퍼파라미터 조정이 필요함을 의미한다.
Q-Prop은 policy gradient의 안정성과 off-policy RL의 효율성을 결합하여 각 방법의 이점을 효과적으로 결합한 방법이다. 핵심 아이디어는 off-policy critic의 taylor expansion을 control variate(모르는 값에 대한 추정의 정밀도를 높이기 위해 알고 있는 값에 대한 추정치를 사용)로 사용하여, critic를 통한 analytical gradient와 advantage approximation의 residual로 구성된 policy gradient를 생성하는 것이다. 이 방법은 PG와 Actor-Critic을 통합하였다. 즉, PG의 분산을 줄이기 위해 off-policy critic를 사용하거나, bias를 수정하기 위해 on-policy Monte Carlo를 사용하는 것으로 볼 수 있다.
Monte Carlo policy gradient

기본적으로 Rt는 infinite horizon 문제에 대해 t 시점 이후의 누적 reward을 나타낸다. 강화 학습의 목표는 policy 파라미터 θ에 대해 기대 수익 J(θ)를 최대화하는 것이다. Monte Carlo policy gradient는 목표에 대해 직접적인 gradient-based optimization을 수행한다. 이에 대한 수식은 아래와 같다.

b(st)는 baseline을 의미한다. 이를 아래와 같이 쓸 수도 있으며, ρπ(s) 는 discount factor가 적용된 state 방문 빈도를 의미한다.

위 식은 J(θ)의 편향되지 않은 기울기이다. 하지만 많은 PG 알고리즘은 discount factor가 적용되지 않은 state 방문을 사용하기 때문에, 실제로는 편향이되어 있다. 이 bias를 제거하지 않으면 성능이 저하되는 경향을 보인다.
또한 Monte Carlo 샘플을 사용하여 기울기를 추정하며 분산이 매우 크다. 이에 학습이 가능하도록 분산을 충분히 줄이기 위해서는 적절한 baseline 선택이 필요하다. 일반적으로 baseline을 state의 estimate value function인 Vπ(st)를 사용한다. 이를 통해 action-value function Qπ(st,at)를 활용하여 advantage function Aπ(st,at)의 estimate를 구한다.

Qπ(st,at)는 π를 따른다고 가정하여 주어진 state에서 각 action의 성능을 요약하고, Aπ(st,at)는 주어진 state st에서 평균 성능 Vπ(st)를 통해 각 action을 비교하는 척도를 제공한다. Aπ(st,at)를 사용하면 learning signal의 중심이 지정되고 분산이 크게 줄어든다.
높은 분산 외에도 PG의 또 다른 문제는 policy에 따른 샘플이 필요하다는 것이다. 이는 매우 샘플 집약적으로, off-policy 수준의 효율성을 달성하기 위해 off-policy 데이터를 활용할 수 있습니다.
Policy gradient with function approximation
Policy evaluation 단계에서는, 현재 policy π(θ)에 대한 critic Qw를 최적화하기 위해 temporal difference(TD) learning을 주로 사용한다. 그리고 policy improvement 단계에서는 critic 추정치 Qw에 대해 policy π를 greedy하게 최적화한다. 일반적으로 Deep Q-Network의 experience replay를 통해, critic를 위한 off-policy TD learning을 사용하여 샘플을 효율적으로 활용한다. DDPG(Deep deterministic Policy Gradient)가 대표적인 예시로 들 수 있다.
Q-Prop
Q-Prop estimator는 앞서 언급했듯이 on-policy와 off-policy를 결합한 방식으로, 전자가 거의 편향되지 않았지만 높은 분산의 기울기를 사용하고 후자는 deterministic하지만 편향된 기울기를 사용한다. 즉, 두 가지 유형의 기울기를 효과적으로 결합한 새로운 estimator를 구성하였다.

임의 함수 f(st,at)의 1차 Taylor expansion을 PG estimator에 대한 control variate로 사용한다. State st로부터 action at의 Monte Carlo return을 Q_hat(st,at)으로 표현하며, µθ (st)는 stochastic policy πθ의 expected action을 의미한다.

여기서 f 에 대해 critic Qw를 사용하고, at_bar에 대해 µθ(st)를 사용하면 아래와 같이 표현할 수 있다.

이후 advantage A_hat(st,at)을 추정하므로, Q-Prop estimator를 advantage 항에 대한 식으로 작성하면 아래와 같은 식을 구할 수 있다.

이를 통해 control variate를 갖춘 특별한 형태의 Monte Carlo policy gradient estimator와 Qw를 통해 off-policy 데이터를 사용하여 훈련될 수 있게 되었다. 최종적으로 Q-Prop은 더 이상 Monte Carlo policy gradient 방법이 아니라 actor-critic 방법과 더 유사해진다. Critic는 off-policy 방식으로 update 되지만, actor는 on-policy에 따라 update된다. 여기서 Critic Qw가 Qπ에 근접하면 신뢰할 수 있는 기울기를 제공하고, 분산을 줄이며 수렴 속도를 향상 시킨다.
Control variate
Q-Prop을 안정적으로 적용하기 위해서는 control variate 적용 전후로 분산이 어떻게 변하는지 분석하는 것이 중요하다. 이에 먼저 위 최종 식에 η(st)를 도입한다. 이는 control variate의 강도를 조절하는 가중치 변수다. 이에 따른 추정량의 분산 또한 Var*로 표현할 수 있다.


원래 estimator의 분산을 의미하는 Var보다 작은 분산 값, 즉 Var* < Var이 되는 η(st)를 선택하면 차이를 줄이도록 조절할 수 있다. 다만 기대치를 추정하기 위해 naive Monte Carlo를 사용하는 것 현실적이지 못하기에, surrogate 분산 측정값을 대안으로 사용하였다. 이 방식을 통해 측정이 더욱 쉬워지며 수식은 아래와 같다. 또한 이를 통해 기울기의 분산을 조절하는 Q-Prop의 변형을 고안하였다.


Adaptive Q-Prop

η(st)에 대해 위와 같은 식을 계산할 수 있다. 만약 어떤 state A_bar가 A_hat가 상관된 경우 분산 감소를 보장할 수 있다. 이를 fully adaptive Q-Prop 방법이라 부른다. 이러한 분석은 adaptive Q-Prop에서 critic Qw가 좋은 결과를 생성하기 위해 반드시 Qπ에 근접할 필요는 없다는 것을 의미한다. 단지 A_hat과 양의 상관관계 혹은 음의 상관관계만 있으면 된다는 뜻이다. 이는 이전 actor-critic 방식에서 critic의 정확도가 중요했던 사실과 대조된다.
경험적으로 Cov_at(A_hat,A_bar)의 single sample estimate는 분산이 크기 때문에, 두 가지 현실적인 방법을 고안하였다.


Conservative Q-Prop은 state의 일부 샘플에 대해 control variate을 효과적으로 비활성화한다. 음의 상관관계를 가지면 critic이 형편없을 가능성이 높기 때문이며, 이를 통해 보수적(conservative)으로 접근한다고 명명되었다. 그리고 Aggressive Q-Prop control variate를 보다 자유롭게 사용하므로 aggressive라고 명명되었다.
Algorithm

Pseudo code는 위와 같다. Q-Prop의 단점은 좋지 않은 critic에 대한 robust가 떨어진다는 것이다. Policy를 벗어난 critic이 언제 신뢰할 수 있는지 여부를 추정하는 것은 근본적인 문제 중 하나다.
결과

OpenAI Gym 벤치마크 MuJoCo 환경에서 평가를 진행하였다. "c-" 및 "v-"는 각각 conservative Q-Prop과 aggressive Q-Prop 변형을 의미한다. 그리고 "TR-"는 trust region policy optimization, "V-"는 vanilla policy gradient를 의미한다.

HalfCheetah-v1 도메인의 trust region update와 adaptive Q-Prop의 비교 결과다. Conservative Q-Prop은 다른 버전들 보다 훨씬 더 안정적인 성능을 보인다. 또한 adaptive Q-Prop은 샘플 효율성 측면에서 TRPO를 크게 능가하는 모습을 보이는데, conservative Q-Prop은 TRPO보다 약 10배 적은 샘플을 사용하여 4000의 평균 reward에 도달한다.
오른쪽 차트는 다양한 배치 크기에 걸쳐 TRPO와 conservative Q-Prop의 성능 비교다. 기울기 추정의 높은 분산으로 인해 TRPO에는 일반적으로 매우 큰 배치 크기가 필요하다. 하지만 Q-Prop 방법은 업데이트당 단 1개의 에피소드로도 학습할 수 있으며 작은 배치 크기로 더 나은 샘플 효율성을 달성한다. 즉, Q-Prop이 기존 방법에 비해 분산을 크게 줄인다는 것을 의미한다.
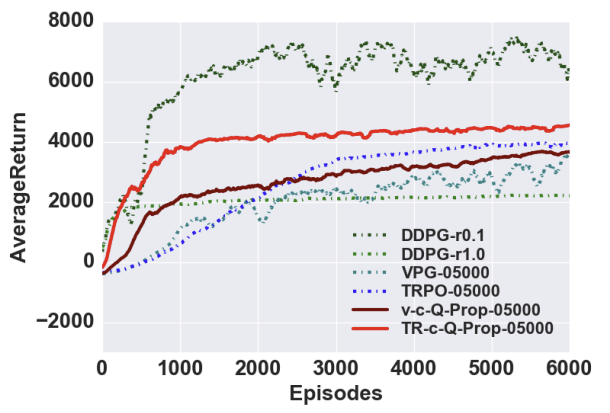
다른 model-free 알고리즘 및 Vanilla PG를 사용하는 v-c-Q-Prop와 trust region update를 사용하는 TR-c-Q-Prop의 두 가지 버전의 conservative Q-Prop을 비교한 결과다. 하이퍼파라미터 설정에 따라 DDPG가 좋은 성능을 보일 때도 있지만 매우 민감하게 반응하는 경향이 있어, Q-Prop은 DDPG와 비교할 때 더 안정적이고 monotonic한 특징이 있다고 판단할 수 있다.

최대 평균 reward와 수렴 단계를 포함한 결과다. Q-Prop은 sample complexity 측면에서 지속적으로 TRPO를 능가하며, 때로는 더 복잡한 도메인에서 DDPG보다 더 높은 보상을 달성한다. 그 중 하나가 오른쪽 그래프이다. Q-Prop은 Humanoid-v1 도메인에서 TRPO에 비해 샘플 효율성을 크게 향상시키며, DDPG는 Q-Prop보다 좋은 솔루션을 보이지 않는다.
Reference
논문 링크 : https://arxiv.org/abs/1611.02247
'딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| [RL] A3C (1) | 2024.11.27 |
|---|---|
| [RL] Gorila (0) | 2024.11.26 |
| [RL] Dueling DQN (1) | 2024.11.24 |
| [RL] PER (0) | 2024.11.23 |
| [RL] Double DQN (0) | 2024.11.22 |