키워드
1. 안정적이고 효율적인 정책 최적화 방법인 PPO 알고리즘을 제안. 정책 갱신 시 큰 변화를 방지하여 안정성을 높이고, 성능을 향상시킴.
2. "Proximal Policy Optimization Algorithms"
3. PPO, Clipped surrogate objective, Adaptive KL Divergence coefficient
PPO (Proximal Policy Optimization)
Q-learning은 많은 간단한 문제에서조차 결과가 좋지 않으며, vanilla policy gradient는 데이터 효율성과 robust가 좋지 않다. TRPO는 효율성 및 성능 측면에서 좋은 결과를 보이나, 상대적으로 복잡하며 노이즈(ex. dropout) 또는 파라미터 공유(policy network, value network 간)를 활용하는 아키텍처와 호환되지 않는다. 이에 first-order optimization만을 사용하면서 TRPO의 데이터 효율성과 안정적인 성능을 얻는 PPO (Proximal Policy Optimization) 알고리즘을 고안하였다. 이는 TRPO의 장점을 가지고 있으면서, 구현이 간단하고 일반화 성능이 더 좋으며 경험적으로 더 나은 sample complexity를 가진다.
PPO는 policy 성능에 대해 lower bound을 형성하는 clipped probability ratio를 통한 새로운 objective을 활용한다. 그리고 policy를 최적화하기 위해, policy에서 데이터를 샘플링하는 것과 샘플링된 데이터에 대해 여러 epoch에 걸친 optimize를 번갈아 수행한다. 이를 바탕으로 stochastic gradient ascent를 수행하며, "surrogate" object function을 최적화하는 새로운 policy gradient 방법이다.
Clipped Surrogate Objective
Policy Gradient

Policy gradient 방법은 policy gradient의 추정량을 계산하고, 이를 stochastic gradient ascent를 통해 업데이트하는 방식이다. πθ는 stochastic policy이고 A_hat은 time step t에서 advantage function의 추정치이다. E는 샘플 배치에 대한 경험적(empirical) 평균을 나타낸다. 여기서 동일한 trajectory로 손실 LPG를 여러번 optimization을 수행하도록 생각할 수 있으나, 이는 경험적으로 파괴적으로 큰 policy 업데이트가 종종 발생한다.
Trust Region
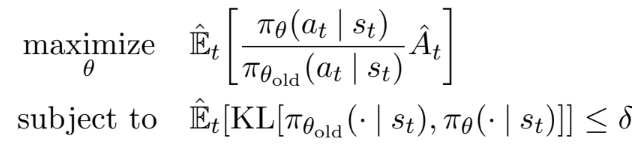
TRPO는 policy 업데이트 크기에 대한 제약 조건에 따른 "surrogate" objective function을 최대화시킨다. θold는 업데이트 전 policy의 파라미터를 의미한다. Maximization은 objective에 대한 linear(1차) approximation과 제약 조건에 대한 quadratic(2차) approximation를 구한 후, conjugate gradient 알고리즘을 통해 근사적으로 풀 수 있다. 아래는 이를 바탕으로 제약이 아닌 페널티를 사용한 방법이다.
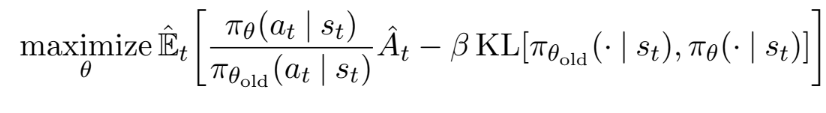
현실적으로 TRPO는 하드 제약 조건을 사용한다. 그 이유는 다양한 문제에서 잘 수행되는 단일 β 값을 선택하기 어렵기 때문이다. 이는 first-order를 바탕으로 TRPO의 monotonic한 특성을 구현하기 위해, 단순히 고정 페널티 계수 β를 선택하고 SGD를 사용한 optimization 방식은 불가능함을 의미한다.
Clipped Surrogate Objective
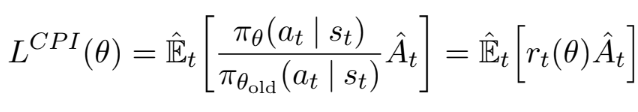
TRPO의 “surrogate” objective function은 위와 같으며, 제약 조건이 없이 maximize하게되면 지나치게 큰 policy 업데이트가 발생할 수 있다. 따라서 probability ratio rt(θ) (여기서 r은 reward가 아니라 ratio의 약자다)가 1에서 멀어지는 경우, policy의 업데이트 되는 크기에 페널티를 주는 방법을 고려했다. 아래가 이를 구현한 objective이다.
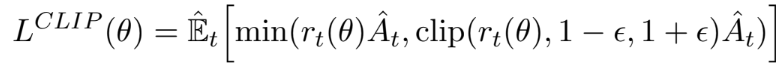
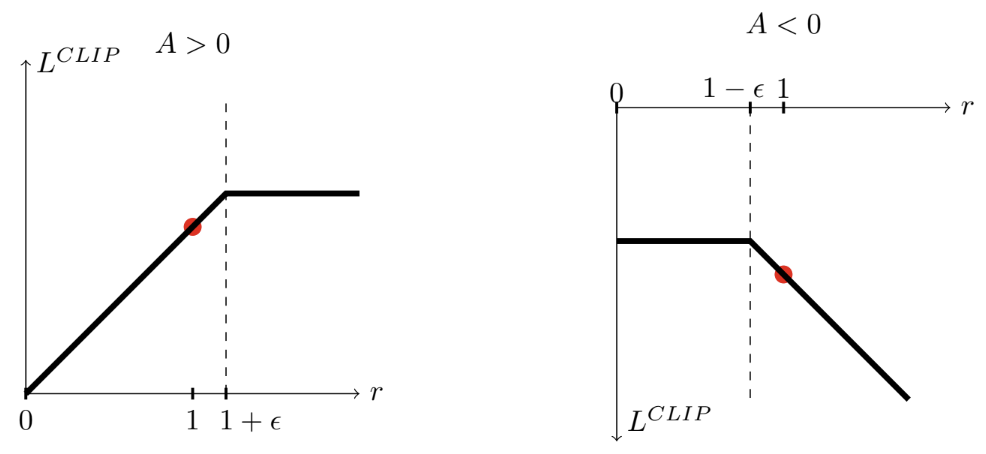
ε은 하이퍼파라미터이다. min 내부의 첫 번째 항은 기존 LCPI 이다. 두 번째 항은 rt(θ)를 clipping하여 surrogate objective를 수정한다. 즉, rt(θ)를 간격 [1 − ε, 1 + ε] 사이에만 존재하게끔 한다. 이 두 항 중 최소값을 취하므로, 최종 objective는 clip되지 않은 objective 의 lower bound가 보장된다. 아래는 probability ratio r이 advantage의 부호에 따라 1 − ε 또는 1 + ε 에서 clipping 되는 것을 시각화한 자료다.
Adaptive KL Penalty Coefficient
Clipping된 surrogate objective에 대한 대안 혹은 추가적으로 사용할 수 있는 또 다른 접근 방식으로 adaptive KL 페널티 계수가 있다. 먼저 KL divergence의 target dtarg를 설정한다. 이후 페널티 기준에 따라 계수 β를 조정하여, 설정된 target을 달성하는 방법이다. 다만 KL 페널티가 clipping surrogate objective보다 성능이 좋지 않다. 그 이유는 KL divergence가 dtarg와 크게 다른 경우를 가끔 볼 수 있지만, 이러한 경우가 매우 드물고 β도 빠르게 조정되기 때문이다. 각 policy 업데이트에서 다음 단계를 통해 수행된다.

Algorithm
대부분의 variance-reduced advantage-function estimator는 학습된 state-value function V(s)를 주로 사용한다. 그리고 policy function과 value function 간 파라미터를 공유하는 신경망 아키텍처를 사용하는 경우, policy surrogate와 value function error 항을 결합한 손실 함수를 사용한다. 이를 바탕으로 각 iteration에서 아래와 같은 objective를 최대화하도록 설계할 수 있다. c1, c2는 계수이고, S는 엔트로피 보너스를 나타내며, LVF는 value function의 squared error loss를 의미한다.

Policy gradient의 구현은 T 만큼의 time step에 동안 수집된 해당 샘플을 통해 업데이트한다. 이 방식을 위해선 time step T를 벗어나지 않는 advantage estimator가 필요하며, 아래 수식으로 구현할 수 있다. PPO 알고리즘도 이를 바탕으로 구현된다. 먼저 각 iteration마다 병렬적으로 구성된 N개의 actor는 각각은 T time step동안 데이터를 수집한다. 이후 N*T 개의 샘플을 기반으로 surrogate 손실을 구성하고, K epoch 동안 minibatch SGD를 사용하여 최적화한다.
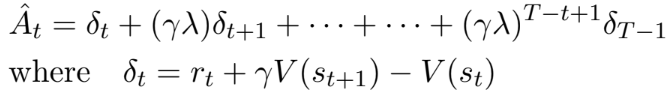
결과

위와 같은 다양한 surrogate objective를 비교한 결과다. Clipping, penalty를 사용하지 않은 경우, clipping을 사용한 경우, 고정형 KL 페널티 혹은 적응형 KL 페널티를 사용한 경우로 구성되어 있다. 100개 에피소드에서 얻은 보상을 평균하여 점수를 측정하였으며, random policy를 0점, 가장 좋은 결과를 1로 normalize하였다. 위 표와 같이 ε = 0.2를 사용한 clipping 기반 결과가 가장 좋은 성능을 보였다. 또한 clipping이나 페널티가 없는 경우 점수가 음수인데, 이는 하나의 환경에서 random policy보다 더 나쁜 보상을 얻었기 때문이다.
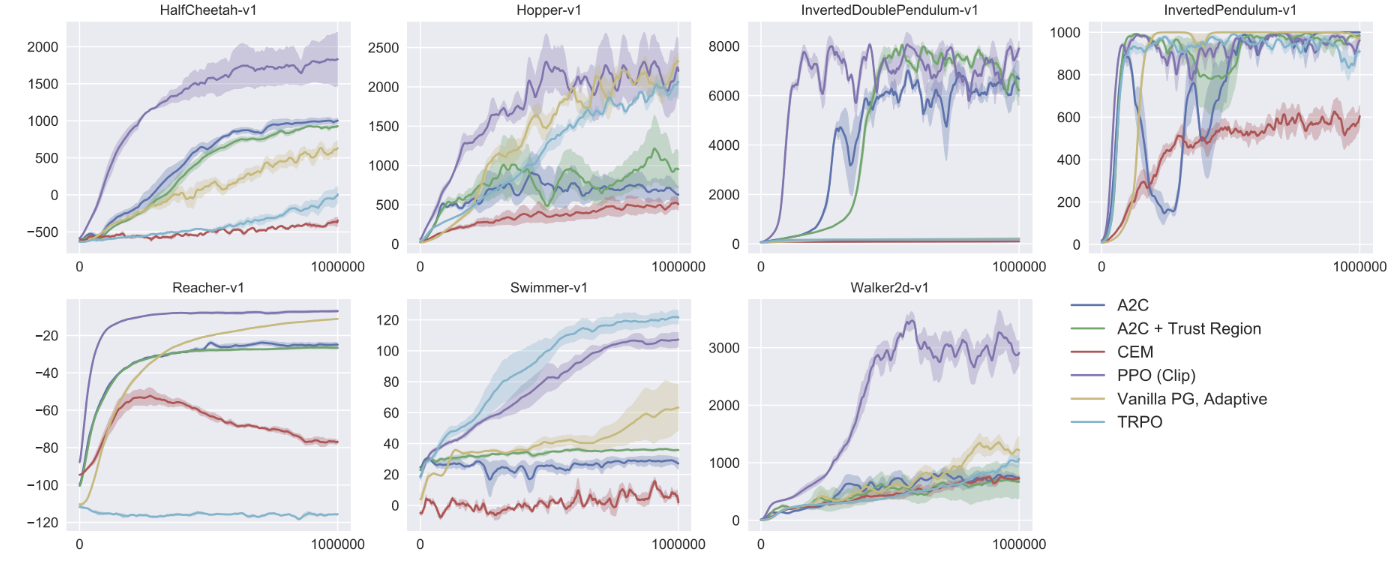
Clipping 기반 PPO를 continuous 문제에 좋은 성능을 보였던 여러 다른 방법과 비교한 결과다. PPO가 거의 모든 환경에서 이전 방법보다 성능이 우수하다는 것을 알 수 있다. 그리고 아래는 PPO 기반 humanoid 시뮬레이션 결과다. 로봇이 큐브에 의해 밀리는 동안 달리고, 조종하고, 땅에서 일어나야 하는 일련의 문제에 대해 학습되었다.

위는 Atari에서 다른 알고리즘과 비교한 결과이며 두 가지 평가 지표를 활용하였다. 먼저 빠른 학습 속도를 평가하기 위해 전체 훈련 기간 동안 에피소드 당 평균 보상을 비교하였으며, 최종 성능 비교를 위해 최근 100개 학습 에피소드의 평균 보상을 비교하였다. 위 표는 각 알고리즘이 "승리한" 게임 수 이며, 점수는 세 번의 시도에 걸친 점수의 평균으로 계산되었다.
Reference
논문 링크 : [1707.06347] Proximal Policy Optimization Algorithms (arxiv.org)
'딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| [RL] HER (0) | 2025.01.01 |
|---|---|
| [RL] ICM (Intrinsic Curiosity Module) (0) | 2024.12.25 |
| [RL] ACER (1) | 2024.12.11 |
| [RL] AlphaGO (1) | 2024.12.04 |
| [RL] A3C (1) | 2024.11.27 |