키워드
1. 자기 지도 예측을 통한 호기심 기반 탐험 방법 제안. 외재적 보상이 없는 환경에서도 학습을 촉진하기 위해 내재적 보상 개념 도입.
2. ICM, Curiosity-driven Exploration
3. ICM, Intrinsic curiosity Module, Curiosity
호기심 (Curiosity)
현실 세계는 강화 학습 관점의 “보상”이 매우 희박하고 볼 수 있다. 예를 들어, 세 살짜리 아이에게 현대 생활의 대부분의 보상(대학, 좋은 직장, 집, 가족)은 먼 미래의 일이므로 유효한 강화 signal를 제공하지 않는다. 대신 호기심은 환경을 탐색하고 새로운 state를 발견하는데 사용된다. 또한 호기심은 미래에 보상을 추구하는 데 도움이 될 수 있는 새로운 기술을 배우는 방법으로 설명할 수 있다.
강화 학습에서도 실제 시나리오에서 외부(extrinisic) 보상은 극히 드물거나 전혀 없다. 이에 호기심은 에이전트가 환경을 탐색하고 나중에 유용할 수 있는 기술을 배울 수 있도록 하는 본질적인 보상 signal 역할을 한다. 즉, 외적 보상이 부족할 때마다 본질적인(intrinsic) 보상이 중요하다. 대부분은 이를 "새로운(novel)" state를 exploration 하도록 장려하거나, action을 예측하는 에이전트의 오류/불확실성을 줄여 학습하도록 했다. 다만 이러한 방식들은 이미지와 같은 고차원 continuous state space에서 구축하기 어렵다. 또한 추가적인 문제점은 에이전트가 환경의 확률론성을 다루는 데 있다.
이러한 여러 문제에 대해 제안된 해결책 중 하나는, 에이전트가 예측하기 어렵지만 "학습 가능한" state에 직면할 때만 에이전트에게 보상하는 것이다. 다만 현재 state를 기반으로 다음 state를 예측하는 것이 매우 어렵다는 점에서, 본질적으로 유효한 보상 signal인지 판단할 수 없다.
이전 접근 방식의 문제를 에이전트의 action으로 인해 발생하거나, 에이전트에 영향을 미칠 수 있는 환경 변화만 예측하고 나머지는 무시하여 해결하였다. 입력을 에이전트가 수행하는 action과 관련된 정보만 표시되는 feature space로 변환하고, self supervised 방식으로 feature space를 학습한다. 즉, 호기심을 학습된 시각적 feature space에서 자신의 action을 예측하는 에이전트의 성능에 대한 error로 공식화하였다.
먼저 현재, 다음 state를 고려하여 에이전트의 action을 예측하는 proxy inverse dynamics 문제에 대해 NN을 학습한다. 즉 action을 예측하는 데만 사용되기 때문에, 에이전트 자체에 영향을 주지 않는 환경의 요인을 feature space 에 표현할 이유가 없다. 이를 통해 유효한 feature만 self supervised 방식으로 학습한다. 그런 다음 현재 state의 feature representation과 action을 바탕으로 다음 state의 feature representation을 예측하는 forward dynamics 모델을 학습한다. 호기심을 장려하기 위한 본질적인 보상으로 forward dynamics 모델의 예측 오류를 사용한다.
이를 통해 이미지와 같은 고차원 continuous state space에서 픽셀에 대해 direct하게 예측하는 어려움을 우회하고, 에이전트에 영향을 줄 수 없는 환경을 무시한다. 호기심은 에이전트가 새로운 지식을 추구하면서 환경을 탐색하는 데 도움을 주며, 향후 시나리오에 도움이 될 수 있는 기술을 배우는 메커니즘이다. 우연히 target state에 도달하기를 바라는 것은 가장 단순한 환경을 제외한 모든 환경에서는 소용이 없다. 하지만 제안된 방법은 명시적인 목표가 없더라도 일반화 가능한 기술을 학습할 수 있다.
Curiosity-driven Exploration

전체 아키텍처는 크게 두 가지 하위 시스템으로 구성된다. 먼저 호기심에 기반한 본질적인 보상 signal를 출력하는 보상 생성기, 그리고 action을 출력하는 policy이다. 본질적인 보상 외에도 에이전트는 선택적으로 환경으로부터 외부 보상을 받을 수도 있다. 시간 𝑡에 생성한 본질적인 호기심 보상을 𝑟𝑡𝑖로 하고 외부 보상을 𝑟𝑡𝑒라 하며, 합 𝑟𝑡 를 최대화하도록 학습된다.
파라미터 𝜃𝑃를 사용하는 Deep NN으로 policy를 𝜋(𝑠𝑡;𝜃𝑃)로 표현할 수 있다. state 𝑠𝑡 가 에이전트에게 주어지면 policy에서 샘플링된 action 𝑎𝑡∼𝜋(𝑠𝑡;𝜃𝑃)를 실행한다. 𝜃𝑃는 누적 보상를 최대화하도록 최적화된다. 호기심 보상 모델은 policy 부분에 다양한 모델과 함께 사용될 수 있다. 아래 실험에서는 A3C를 사용한다.

Prediction error as curiosity reward
먼저 픽셀에 대한 직접적인 예측 오류를 호기심 보상으로 사용하는 것을 생각할 수 있다. 다만 이는 적절하지 않은데, 에이전트가 바람에 흔들리는 나뭇잎의 움직임을 관찰하는 시나리오를 가정해보자. 바람을 모델링하는 것은 본질적으로 어렵기 때문에, 각 잎의 픽셀 위치를 예측하는 것은 더욱 어렵다. 만약 픽셀에 대한 직접적인 예측 오류를 사용한다면, 픽셀 예측 오류는 계속해서 높게 유지되고 에이전트가 항상 나뭇잎에 대해 호기심을 가질 것이다. 그러나 잎의 움직임은 에이전트에게 중요하지 않으므로 잎에 대한 호기심은 바람직하지 않다. 근본적인 문제는 에이전트가 state space의 일부분은 단순히 모델링할 수 없다는 사실을 인지하지 못한다는 것이다.
이에 호기심의 좋은 척도를 제공하는 적합한 feature space는 무엇일까. 이를 위해 우선 에이전트를 조정할 수 있는 모든 소스를 세 가지로 아래와 같이 나눌 수 있다. 여기서 좋은 feature space은 (1)과 (2)를 모델화해야 하며, (3)의 영향을 받지 않아야 한다.
- 에이전트가 제어할 수 있는 것
- 에이전트가 제어할 수 없지만 에이전트에 영향을 미칠 수 있는 것
- 에이전트의 제어 범위를 벗어나 에이전트에 영향을 주지 않는 것
Self-supervised prediction
모든 환경에 대한 feature representation을 직접 설계하는 대신, 학습된 feature space의 prediction error가 좋은 본질적인 보상 signal를 제공하도록, feature space를 학습하는 메커니즘을 고안하였다. 이를 위해 두 개의 하위 모듈로 구성된 deep NN을 학습하며, 첫 번째 모듈은 state(𝑠𝑡)를 feature vector 𝜙(𝑠𝑡)로 인코딩하고 두 번째 모듈은 𝜙(𝑠𝑡), 𝜙(𝑠𝑡+1)을 입력으로 받아 에이전트의 action 𝑎𝑡를 예측한다.
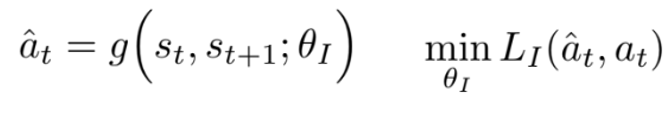
𝑔는 inverse dynamics 모델이며, 학습에 필요한 tuple (𝑠𝑡,𝑎𝑡,𝑠𝑡+1)은 현재 policy 𝜋(𝑠)을 환경과 상호 작용하여 획득한다. 𝐿𝐼는 예측된 action과 실제 action 간의 불일치를 측정하는 손실 함수다.
이후 𝑎𝑡 및 𝜙(𝑠𝑡)을 입력으로 사용하며, 𝑠𝑡+1의 feature encoding을 예측하는 또 다른 NN을 학습한다. 이를 함수 𝑓로 표현하며 forward dynamics 모델이라 한다. 이에 따른 본질적인 보상 signal 𝑟𝑡𝑖는 다음과 같이 계산된다.
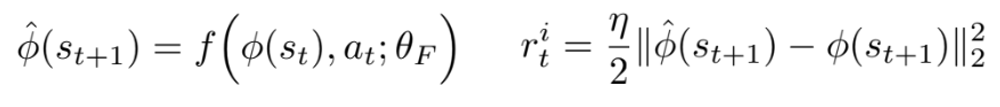
호기심 기반 보상 signal를 생성하기 위해 forward 및 inverse dynamics 손실을 함께 최적화한다. Inverse 모델은 에이전트의 action 예측과 관련된 정보만 인코딩하는 feature space를 학습하고, forward 모델은 이 feature space에서 예측을 수행한다. 이러한 구조를 Intrinsic Curiosity Module(ICM)이라고 부른다.
이 구조를 기반으로 할때, 중요한 요소 중 하나인 feature space는 에이전트의 action에 영향을 주지 않는 환경을 인코딩할 필요가 없다. 이를 통해 에이전트는 근본적으로 도달할 수 없는 state를 예측했을 때의 보상을 받지 않으며, exploration에 있어 신경을 쓰지 않아도 되는 개체의 존재에 대해 견고해진다. 이를 바탕으로 에이전트 학습을 위한 전반적인 최적화 문제는 아래와 같다.

0≤𝛽≤1은 forward 모델 손실에 대한 inverse 모델 손실의 가중치를 부여하는 스칼라 항이며, 𝜆>0은 본질적인 보상 signal 학습과 policy gradient 손실 사이에 가중치를 부여하는 스칼라 항이다.
ICM Architecture
Feature space를 출력하는 NN은 각각 32개의 filter, kernel size 3x3, stride 2m padding 1을 포함하는 4개 conv 레이어를 사용한다. 이후 ELU activation이 뒤 따른다. 출력 𝜙(𝑠𝑡)는 288 차원을 가진다.
Inverse 모델의 경우, 먼저 𝜙(𝑠𝑡), 𝜙(𝑠𝑡+1) vector가 단일 vector로 concat된다. 이후 256개의 unit으로 구성된 FC 레이어를 통과하고, action의 수 만큼의 unit으로 구성된 FC 레이어로 후속 연결되어 action을 예측한다.
마지막으로 forward 모델은 𝜙(𝑠𝑡)를 𝑎𝑡와 concat하고, 이를 각각 256 및 288 unit로 구성된 두 개의 FC레이어 시퀀스로 전달하여 결과를 출력한다.
결과

ICM을 평가하기 위해 두 가지 시뮬레이션 환경을 사용하였다. 첫 번째 환경은 VizDoom이다. 주어진 맵에서 조끼를 찾거나 2100 time step을 초과하면 에피소드가 종료된다. 에이전트는 조끼를 찾은 경우에만 +1의 희소한 보상을 받고 그렇지 않으면 0을 받는다. 최적의 정책이 이 지도에서 가장 먼 방에서 조끼 위치에 도달하려면 약 350 step이 필요하다.

두 번째 환경은 고전 Nintendo 게임인 Super Mario Bros이다. 이 게임은 여러 개의 버튼을 동시에 누를 수 있는 조이스틱을 사용하여 플레이되며, 누르는 시간에 따라 수행되는 작업이 달라진다. 그렇기에 상대적으로 VizDoom보다 난이도가 있으며, 높은 파이프나 넓은 간격을 뛰어넘기 위해 에이전트는 동일한 동작을 최대 12번 연속으로 예측해야 하며 long-term dependency가 필요하다.
'ICM + A3C'가 고안된 전체 알고리즘을 나타내며, 총 3가지 baseline과 비교하였다. 𝜖-greedy exploration 기능을 갖춘 바닐라 'A3C' 알고리즘, inverse 모델이 없는 ICM의 변형인 'ICM-pixels + A3C', VIME(Variation Information Maximization)을 기반으로 TRPO가 사용된 모델이다. 여기서 ICM-pixels은 아키텍처상 ICM에 가깝지만 환경의 제어할 수 없는 부분에 대해 invariant한 임베딩을 학습할 수 없다. 즉, ICM-pixels는 이미지를 직접적으로 사용하여 학습하는 이전 방법을 대표한다.
Sparse Extrinsic Reward
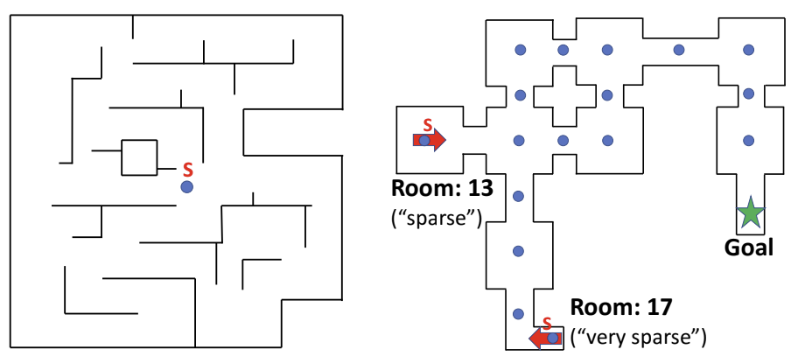
VizDoom 환경에서 외부 보상은 희박하며 에이전트가 지도의 고정된 위치에 있는 목표(조끼)를 찾은 경우에만 제공된다. 이를 "dense", "sparse" 및 "very-sparse" 보상이 있는 세 가지 설정으로 나누었다. "dense" 에서 에이전트는 지도 전체에 균일하게 분포된 17개의 위치 중 하나에서 무작위로 spawn된다. "sparse" 및 "very sparse" 에서는 에이전트가 최적의 policy를 따를 때, 목표에서 각각 270단계와 350단계가 필요하다.

기본 A3C는 희박한 보상으로 인해 성능이 저하되지만 ICM-A3C는 모든 경우에 우수하다. "dense" 사례에서 ICM 에이전트는 기본 에이전트의 𝜖-greedy exploration에 비해 환경을 더 효율적으로 탐색한다. "sparse" 사례에서 기본 A3C는 문제를 해결하지 못하는 반면, ICM-A3C는 문제를 빠르게 학습한다. 여기서 ICM-pixels도 좋은 성능을 보이는데, 이는 에이전트가 고정된 위치에 생성되어 각 에피소드 시작 시 동일한 텍스처를 만나 "dense"에 비해 픽셀 예측 모델을 더 쉽게 학습할 수 있기 때문이다. "very sparse" 사례에서는 기본 A3C와 ICM-pixels 모두 성공하지 못하는 반면, ICM-AC3는 66%에서 목표에 도달했다. 이는 ICM이 hard-goal directed exploration 문제에 더 적합하다는 것을 의미한다.

ICM의 견고성을 테스트하기 위해 이미지의 40%를 고정된 노이즈 영역으로 변환하여 에이전트를 평가했다. 이상적으로 에이전트는 이 소음의 영향을 받지 않아야 한다. "sparse" 설정에서 성능을 비교할 때, ICM은 만점을 달성하지만 ICM-pixels는 이전 "sparse" 작업에 성공했음에도 불구하고 노이즈가 추가된 환경에서는 심각한 어려움을 겪는다. 이를 토해 ICM이 환경의 불필요한 변화에 robust하다는 것을 알 수 있다.
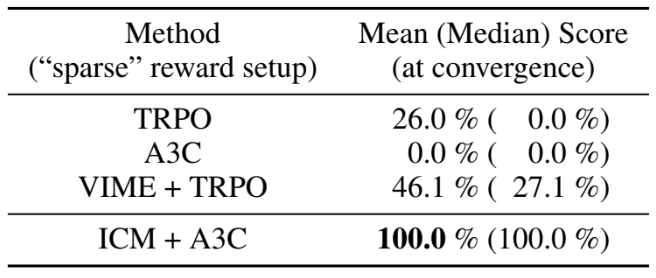
VIME + TRPO로 훈련된 에이전트와 비교한 결과다. 일반적으로 TRPO는 A3C보다 샘플 효율성이 높지만 소요시간이 훨씬 더 오래 걸린다. 이러한 샘플 효율성에도 불구하고 ICM 에이전트은 수렴 속도와 정확성 측면에서 TRPO 및 TRPO-VIME보다 훨씬 더 잘 작동했다.
No Reward
좋은 exploration policy는 에이전트가 목표 없이도 가능한 한 많은 state를 방문할 수 있도록 하는 policy이다. 이를 에이전트가 학습할 수 있는지 테스트하기 위해 아무런 보상도 없이 학습하였다. 이를 바탕으로 VizDoom에서는 어느 부분을 탐색했는지 평가했으며, Mario에서는 얼마나 전진했는지 평가했다.
그 결과 VizDoom에서는 3D Doom 환경에서 복도를 탐색하고, 방 사이를 걷고, 많은 방을 탐색하는 방법을 배울 수 있었다. 또한 Mario에서는 적을 죽이거나 피하거나 치명적인 사건을 피하는 것에 대해 보상을 받지 못했지만 자동으로 이러한 행동을 발견했다. 이는 적에게 죽으면 게임의 일부만 볼 수 있어, 호기심이 제한되기 때문이다. 에이전트는 호기심을 유지하기 하기 위한 새로운 state에 도달할 수 있도록 적을 죽이고 피하는 방법을 배운다.
Generalization
에이전트가 환경을 효율적으로 탐색하기 위해 "일반화"된 기술을 학습하여 이를 수행했는지, 아니면 단순히 훈련 세트를 암기했는지는 확실하지 않다. 이를 검증하기 위해 세 가지 다른 방법으로 결과를 평가했다.

"as-is" 평가 방법은 Level-1에서 훈련된 policy를 통해, Level 1, 2, 3에서 에이전트가 이동한 거리를 측정했다. Level 3이 level 1과 비교하여 구조와 적이 다르다는 사실에도 불구하고, 레벨 3에서 놀라울 정도로 잘 수행되었다. 이는 좋은 일반화 학습했다는 것을 시사한다. 하지만 Level 2에서는 결과가 좋지 않은데, 이는 level 3은 level 1과 전체적인 시각적 특성(낮)이 비슷한 반면, level 2는 상당히 다르기 때문이다(밤)
“fine-tuning with curiosity only”는 level 1에서 호기심으로만 pre-trained된 에이전트를 레벨 2에서도 호기심으로만 fine-tuning하는 방식이다. 이를 통해 시각적 특성의 불일치를 빠르게 극복하고 더 높은 점수를 달성했다.
흥미로운점은 level 2에서 처음부터 학습한 경우보다 “pre-train + fine-tuning”이 성능이 더 좋다는 것이다. 이는 일반화를 위해 일종의 커리큘럼이 생성되었음을 의미한다. 즉, level 1을 플레이하여 얻은 지식을 사용하여 다음 레벨을 더 잘 exploration 할 수 있다.
이 와 반대로 level 3로 pre-trained된 에이전트를 level 1에서 미세 조정하면 "as-is"보다 성능이 떨어진다. 이는 level 3에서 에이전트가 특정 지점을 넘어서는 것이 매우 어렵기 때문이다. 마치 진전을 이룰 수 없으면 지루해지고 탐색을 중단하는 것과 유사하다.
“Fine-tuning with extrinsic rewards”는 호기심으로 pre-train한 다음, 외부 보상으로 fine-tuning하는 방식이다. 이를 통한 ICM 에이전트는 처음부터 둘을 함께 최대화하도록 훈련된 ICM 에이전트보다 더 빨리 학습하고 더 높은 보상을 달성한다. 여기서 ICM-pixels가 이 테스트 환경에 일반화되지 않는다는 점도 주목할만 하다. 이는 ICM-A3C가 일반화하는 학습 기술에 훨씬 더 우수하다는 것을 의미한다.

부가적으로 Mario 환경에서 보상 없이 level 1의 30% 이상을 진행하지 못했다. 이 한계를 넘을 수 없는 이유 중 하나는 게임의 38% 지점에 구덩이가 있기 때문인데, 이 구덩이를 건너뛰려면 15~20번의 키를 특정한 순서로 입력해야한다. 에이전트가 이 시퀀스를 실행할 수 없으면 구덩이에 빠져 죽고 환경으로부터 더 이상 보상을 받지 못한다. 따라서 잠재적으로 탐험할 수 있는 구덩이 너머의 세계가 있음을 나타내는 기울기 정보를 수신하지 못하며, 이는 추가로 연구되어야하는 과제이다.
Reference
논문 링크 : [1705.05363] Curiosity-driven Exploration by Self-supervised Prediction (arxiv.org)
'딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| [RL] SAC (Soft Actor-Critic) (0) | 2025.01.08 |
|---|---|
| [RL] HER (0) | 2025.01.01 |
| [RL] PPO (0) | 2024.12.18 |
| [RL] ACER (1) | 2024.12.11 |
| [RL] AlphaGO (1) | 2024.12.04 |