키워드
1.
2. "FinRL: A Deep Reinforcement Learning Library for Automated Stock Trading in Quantitative Finance"
3. FinRL, Stock trading library
FinRL
Deep RL은 환경과의 상호 작용을 통해 학습함으로써 동적인 의사 결정 문제를 해결하는 데 강력하다. 금융학 (Quantitative finance)에서 주식 거래는 복잡한 주식 시장의 종목, 가격, 수량 등을 기반하여 매우 확률적이고 역동적으로 판단하게 된다. DRL 트레이딩 에이전트는 여러 가지 복잡한 금융 요소를 고려한 multi-factor 모델을 구축하고, 인간 트레이더에게는 어려운 알고리즘 트레이딩 전략을 제공한다. 보다 강력한 모델과 전략이 개발됨에 따라, 일반적인 기계 학습 접근 방식과 특히 DRL 방법의 신뢰성이 더욱 높아지고 있다.
FinRL은 주식 거래를 위한 DRL 라이브러리이다. 가상 환경은 주식 시장 데이터 세트로 구성되고, 거래 에이전트는 신경망으로 학습되며, 거래 성과를 통해 광범위한 백테스팅이 분석이 가능하다. 또한 거래 비용, 시장 유동성, 투자자의 위험 회피 정도와 같은 중요한 거래 제약 조건이 포함되어있다.
DRL은 개발 및 디버깅이 힘들고 오류가 발생하기 쉽다. FinRL은 미세 조정된 표준 DRL 알고리즘을 갖춘 초보자 친화적인 라이브러리이며, “완전성(모든 DRL 요소를 갖춤), 실습 튜토리얼, 재현성”에 초점을 맞춰 개발되었다.
Architecture
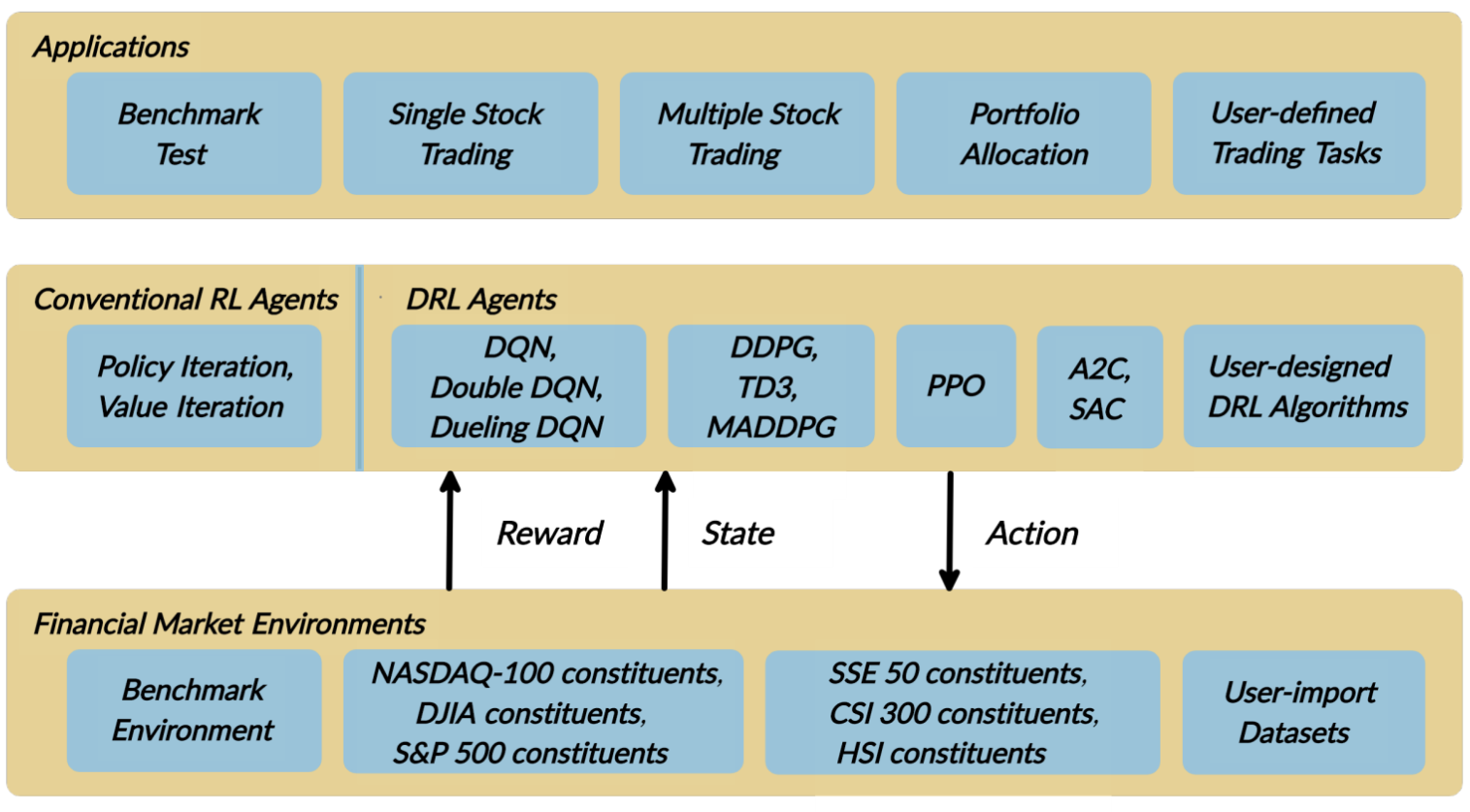
FinRL은 “주식 시장 환경”, “DRL 거래 에이전트”, “주식 거래 어플리케이션”으로 구성된 세 개의 레이어로 설계되었다. 가장 낮은 “환경”에는 종가, 주식, 거래량, 기술 지표 등과 같은 다양한 환경 속성을 가진 6개 주요 지수의 실제 과거 데이터를 사용한다. 중간 “에이전트” 레이어는 정교한 정보를 제공하며, state space와 action space에서 적절하게 정의된 reward function을 통해 환경과 상호 작용한다. 최상위 레이어는 자동화된 주식 거래 애플리케이션이 포함되어있다. 백테스팅 지원을 제공하는 거래 시뮬레이터가 구축되어 있다.
각 레이어에는 여러 모듈이 포함된다. 주식 거래를 구현하기 위해 모든 계층에서 특정 모듈을 선택할 수 있으며, 이를 통해 단순성, 적용성(applicability), 확장성을 확보하였다. 또한 각 계층에 사용자가 직접 새 모듈을 개발할 수 있도록 인터페이스가 포함되어 있다.
Environment
자동 주식 거래 문제는 stochastic, interactive 특성을 고려하여 MDP(Markov Decision Process) 문제로 모델링된다. 에이전트는 환경과 상호작용함으로써 시간이 지날수록 보상이 극대화되는 거래 전략을 구한다. FinRL은 OpenAI Gym 프레임워크를 기반으로 time-driven 시뮬레이션 원칙에 따라, 실제 시장 데이터로 실시간 주식 시장을 시뮬레이션한다.
State space 𝒮 는에이전트가 환경으로부터 받는 observation 정보다. 에이전트는 interactive 환경에서 나은 학습을 위해 아래와 같은 다양한 feature를 관찰한다. 데이터 빈도는 일, 시간, 분 단위로 사용할 수 있다.
- 잔액 𝑏𝑡 / 보유 주식 𝒉𝑡
- 종가 𝒑𝑡 (거래 기준) / 시가,고가,저가 o𝑡,𝒉𝑡,𝒍𝑡 (주가 변동을 추적) / 거래량 𝒗𝑡
- 기술적 지표: MACD 𝑴𝑡 ,RSI 𝑹𝑡∈
Action space 𝒜 는 일반적으로 𝑎∈𝒜 일 때, 𝑎∈{−1,0,1}의 세 가지 action이 사용되며, −1,0,1은 각각 한 주식의 매도, 보유, 매수를 의미한다. 또한 다중 종목 task에 대해 action space {−𝑘,…,−1,0,1,…,𝑘}을 사용한다. 이는 주식의 수량을 의미하며, 예를 들어 "AAPL 10주 매수" 또는 "AAPL 10주 매도"는 각각 10 또는 -10 이 사용된다.
Reward function 𝑟(𝑠,𝑎,𝑠′)은 에이전트가 더 나은 행동을 학습하도록 하는 인센티브 메커니즘이다. 이는 다양한 형태가 사용될 수 있다. 𝑣′ 과 𝑣는 각각 state 𝑠′ 과 𝑠의 포트폴리오 value라고 가정하자. 먼저, 𝑟(𝑠,𝑎,𝑠′) = 𝑣′−𝑣를 통해 포트폴리오 value의 변화를 사용할 수 있다. 그리고 𝑟(𝑠,𝑎,𝑠′) = log(𝑣′/𝑣)로 포트폴리오 log return도 사용되며, 아래 수식과 같은 T 기간 동안의 sharpe ratio도 사용된다. 여기서 Rt는 Rt = vt − vt−1 이다.
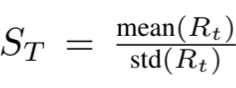
거래를 실행할 때 수수료, 세금 등 거래 비용이 발생한다. FinRL은 거래 비용을 처리하도록 설계되어 있다. 또한, 호가 스프레드 등 주식 거래에 있어서 시장 유동성도 고려한다. 매수-매도 스프레드란 주식에 대한 즉시 매도 호가와 즉시 매수 호가의 차이로, 주식 종가에 매수-매도 스프레드를 추가하여 agent에게 제공한다.
Agent
금융 분야의 RL은 체스나 카드 게임 등 다른 분야와는 다르다. 후자는 본질적으로 환경에 대한 명확하게 정의된 규칙이 있다. 하지만 금융 시장은 정의가 존재하지 않으며, 따라서 자동 거래 에이전트를 얻기 위해 가장 적합한 DRL 알고리즘이 필요하다. 아래는 다양한 RL 에이전트의 특징을 정리한 자료다.
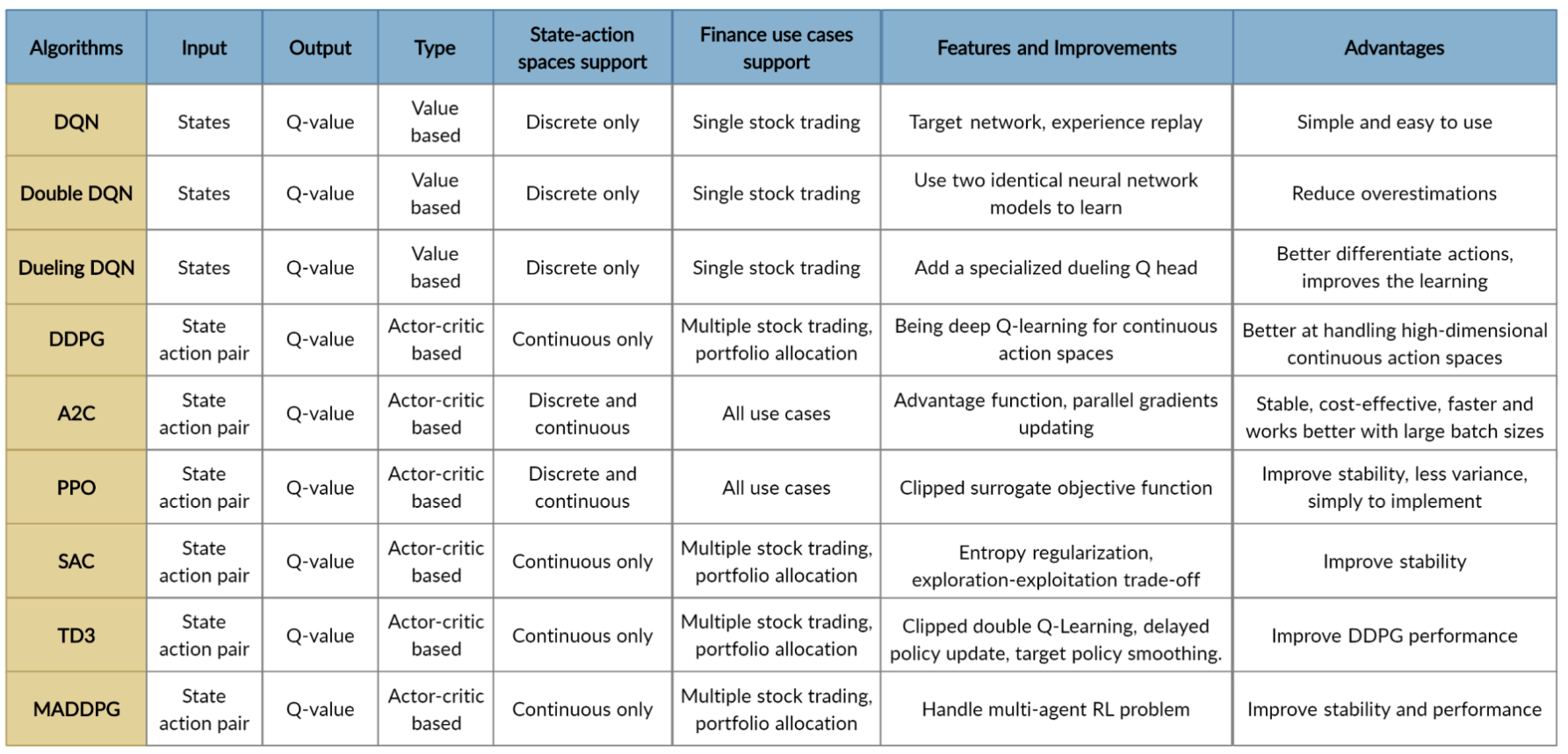
위험 회피(Risk-aversion)는 투자자가 자본을 보존할지 여부를 반영하는 것이다. 또한 심각한 변동성에 직면할 때 거래 전략에 영향을 미친다. 예를 들어, 2008년 금융 위기와 같은 최악의 시나리오에서 위험을 통제하기 위해 극심한 자산 가격 변동을 측정하는 financial turbulence index turbulence 𝑡를 사용한다.

여기서 𝒚𝒕는 현재 t의 수익률을 나타내고, 𝝁는 과거 수익률의 평균을 나타내며, 𝚺은 과거 수익률의 공분산을 의미한다. 이를 매수 또는 매도 조치를 제어하는 파라미터로 사용하며, 지수가 사전 정의된 threshold에 도달하면 에이전트는 매수 조치를 중단하고 보유 주식을 점진적으로 매도하기 시작한다.
Application
FinRL 라이브러리에서는 Quantopian pyfolio 패키지를 사용 자동화된 백테스팅을 제공한다. 이 패키지는 사용하기 쉽고 거래 전략 성과에 대한 포괄적인 이미지를 제공하는 다양한 개별 plot으로 구성되어 있다.
Result
투자자들은 일반적으로 가능한 가장 높은 수익과 가장 낮은 불확실성을 고려하여 결정을 내린다. 이와 관련된 5가지 평가 지표 최종 포트폴리오 가치, 연간 수익률, 연간 표준 편차, 최대 하락 비율, sharpe ratio를 통해 평가를 진행하였으며, 기존 거래 전략을 DRL 전략과 비교하기 위한 baseline으로 사용하였다. 이를 바탕으로 단일 주식 거래, 다중 주식 거래, 포트폴리오 배분의 세 가지 task를 평가했다.
단일 주식 거래

다중 주식 거래 및 포트폴리오 배분
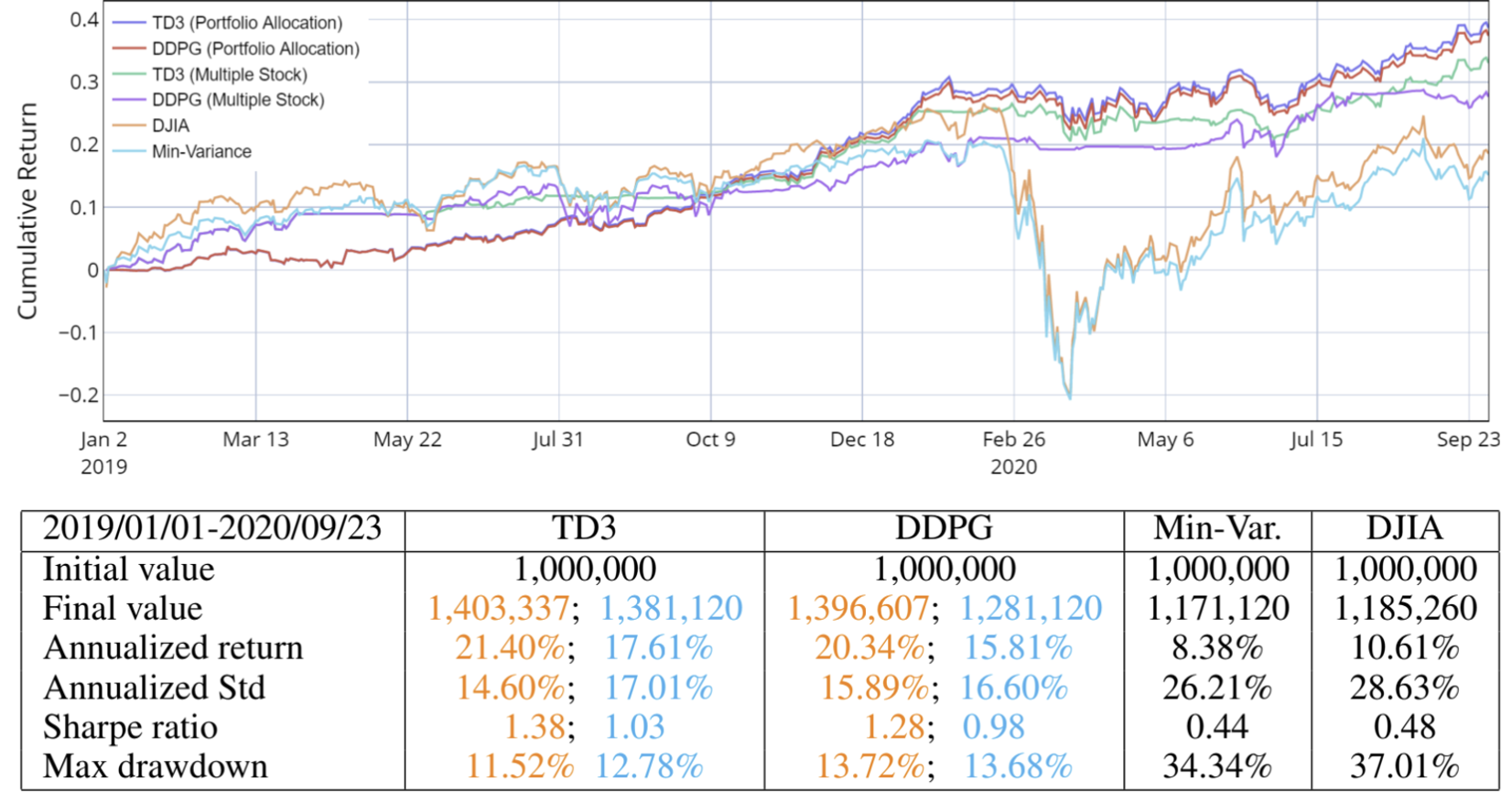
TD3 및 DDPG의 sharpe ratio은 DJIA 지수와 전통적인 min-variance 포트폴리오 할당 전략을 능가하는 성능을 보인다.
Reference
'딥러닝 > Reinforcement Learning' 카테고리의 다른 글
| [RL] DreamerV3 (1) | 2025.03.05 |
|---|---|
| [RL] Decision Transformer (0) | 2025.02.26 |
| [RL] Reward is Enough (0) | 2025.02.19 |
| [RL] TD3 + Behavior Cloning (0) | 2025.02.12 |
| [RL] CQL (0) | 2025.02.05 |