키워드
1. 인코더-디코더 구조에서 주목 메커니즘을 도입하여 번역 성능 향상. 중요한 부분에 집중하도록 학습.
2. "Neural Machine Translation by Jointly Learning to Align and Translate"
3. Attention, (Soft-)Search, Encoder-Decoder, RNNsearch
(Soft-)Search
전통적인 통계적 기계 번역(SMT)과 달리 신경망 기반 기계 번역에 있어, 번역 성능을 극대화하기 위해 end-to-end로 동작하는 단일 신경망 구축을 목표로 하였다. 확률론적 관점에서 번역은 주어진 원본 문장 𝐱에서 조건부 확률을 최대화하는 대상 문장을 찾는 것으로 볼 수 있다. 즉, 조건부 분포가 번역 모델에 의해 학습되면 원본 문장에서 조건부 확률이 최대화되는 문장을 검색하여 번역이 생성된다.
이를 위한 많은 신경망 모델은 인코더-디코더 구조로 설계되었다. 인코더 신경망은 소스 문장을 읽고 고정 길이 벡터로 인코딩하고, 디코더가 인코딩된 벡터에서 번역을 출력하는 구조다. 전체 인코더-디코더 구조는 올바른 번역의 확률을 최대화하도록 함께 훈련되는 동시에, 각 언어에 대한 인코더 혹은 디코더가 있거나 각 문장에 언어별 인코더가 적용되어 번역을 출력한다.
이러한 구조의 잠재적인 문제는 신경망이 원본 문장의 모든 필수 정보를 고정 길이 벡터로 압축할 수 있어야 한다는 것이다. 이에 긴 문장, 특히 훈련 코퍼스의 문장보다 긴 문장에 대처하기 어려울 수 있다. 이로 인해 bottleneck 현상이 발생한다고 가정할 수 있으며, 모델이 자동으로 (soft-)search 할 수 있도록 하는 새로운 인코더-디코더 구조를 고안하였다.
모델은 번역에서 단어를 생성할 때마다, 원본 문장에서 가장 관련성이 높은 정보가 집중된 위치를 (soft-)search 한다. 여기서 이전 모델과 가장 중요한 차이점은 전체 입력 문장을 단일 고정 길이 벡터로 인코딩하지 않는다는 것이다. (Soft-)search는 입력 문장 및 이전에 출력된 단어와 관련된 context 벡터를 기반으로 동작되며, 번역을 위한 벡터를 매번 adaptive하게 선택할 수 있다. 이를 통해 길이에 관계없이 번역을 잘 수행할 수 있게 되었다. 또한 개선은 긴 문장에서 더 뚜렷하게 나타나지만 짧은 길이의 문장에서도 성능 향상이 확인되었다.
Architecture

새로운 아키텍처의 기본적인 구조는 이전과 비슷한 인코더-디코더 구조와 유사하다. 차이는 인코더는 양방향 RNN으로 구성되어 있으며, 디코더는 원본 문장의 검색을 통해 번역을 생성한다.
Encoder
일반적인 RNN은 첫 번째 기호 𝑥1부터 마지막 기호 𝑥𝑇까지 순서대로 입력 시퀀스 𝐱를 읽는다. 하지만 문장의 의미를 파악하기 위해 앞의 단어뿐만 아니라 뒤따르는 단어도 요약하기를 원한다. 이에 두 개의 RNN으로 구성되며, 순방향 RNN 𝑓→은 입력 시퀀스를 순서대로 역방향 RNN 𝑓←은 시퀀스를 역순으로 수행된다. 이후 순방향 hidden state ℎ→𝑗와 역방향 hidden state ℎ←𝑗를 연결하여 각 단어 𝑥𝑗에 대한 주석(annotation)을 구하며, 이에 주석 ℎ𝑗에는 앞 단어와 뒤 단어의 요약이 모두 포함되어 있다고 볼 수 있다. 실험에서 RNN은 GRU가 사용되었다.
Decoder
Decoder는 기존과 유사한 구조 및 조건부 확률을 활용한다. 𝑠𝑖는 𝑖 step의 hidden state를 의미한다. 기존 인코더-디코더 모델과 차이점은 출력 𝑦𝑖에 대해 고유한 context 벡터 𝑐𝑖에 따라 결정된다는 것이다.
Context 벡터 𝑐𝑖는 시퀀스마다 달라진다. 위 수식에서 ℎ𝑗에는 입력 시퀀스의 𝑗번째 단어에 중점을 둔 전체 입력 시퀀스 정보이다. 𝑐𝑖는 모든 ℎ𝑗의 가중 합으로 계산된다. 이에 대한 가중치 𝛼𝑖𝑗는 𝑒𝑖𝑗의 softmax로 정의된다. 이는 위치 𝑗 주변의 입력과 위치 𝑖의 출력이 얼마나 잘 일치하는지 점수를 의미한다. 이 점수는 RNN의 hidden state 𝑠𝑖−1와 입력 문장의 𝑗번째 주석 ℎ𝑗에 의해 결정된다. 즉, hidden state에 의해 context 벡터가 계산되기 때문에 시퀀스마다 매번 다른 잘 align된 벡터를 구할 수 있다.
Attention
Alignment model 𝑎의 수식은 위와 같다. 𝑊𝑎, 𝑈𝑎, 𝑣𝑎 는 가중치 행렬을 의미한다. 이를 통해 계산된 가중치 𝛼𝑖𝑗는 타겟 단어 𝑦𝑖가 입력 단어 𝑥𝑗에 대해 번역될 확률로 설정할 수 있다. 확률 𝛼𝑖𝑗는 다음 𝑠𝑖를 결정하고 𝑦𝑖을 생성하는 데 있어, 이전 hidden state 𝑠𝑖−1과 관련하여 주석 ℎ𝑗의 중요성을 반영한다. 즉, 𝑖번째 컨텍스트 벡터 𝑐𝑖는 확률 𝛼𝑖𝑗를 통해 모든 주석에 대해 번역해야하는 소스로 예상되는 주석의 위치를 align 해준다.
직관적으로 디코더는 원본 문장에서 주의(attention)를 기울여야하는 부분을 알 수 있으며, 이는 디코더에 attention mechanism을 구현했다고 볼 수 있다. Attention mechanism을 통해 원본 문장의 모든 정보를 고정 길이 벡터로 인코딩해야 필요성을 덜 수 있으며, 정보가 주석 시퀀스 전체에 분산되고 이에 따라 디코더가 이를 선택적으로 검색할 수 있다.
위는 주석 가중치 𝛼𝑖𝑗를 시각화한 것이다. 각 행은 출력과 관련된 가중치를 의미한다. 이를 통해 생성된 번역과 원본 문장의 단어 사이의 attention을 직관적인 확인할 수 있다. 즉, 원본 문장의 어느 위치가 더 중요하게 고려되었는지 알 수 있다는 의미와 같다. 위 예시에서 대부분의 단어 정렬은 단조로운 구성으로 대각선을 따라 강한 가중치가 표시되지만, 형용사와 명사는 일반적으로 프랑스어와 영어 사이에서 다르게 정렬되며 첫 번째 반대 대각선에 큰 가중치가 이를 정확히 인지하였음을 알 수 있다.
결과
모델
Baseline 모델은 RNN Encoder-Decoder이며, attention이 추가된 모델을 RNNsearch라고 한다. 각각 최대 30단어 길이의 문장(RNNencdec-30, RNNsearch-30)으로 훈련한 모델과 최대 50단어 길이의 문장(RNNencdec-50, RNNsearch-50)으로 훈련한 모델이 있다. 두 모델 모두 beam search를 사용하여 조건부 확률을 최대화하는 번역 전략을 사용하였다.
위 차트를 통해 문장의 길이가 길어질수록 RNNencdec의 성능이 급격히 떨어지는 것을 알 수 있다. 반면에 RNNsearch-30과 RNNsearch-50은 모두 문장 길이에 크게 영향을 받지 않는다. 특히 RNNsearch-50은 문장 길이가 50개 이상인 경우에도 성능 저하가 나타나지 않았다. 또한 RNNsearch-30이 RNNencdec-50보다 성능이 뛰어나다는 점도 학습한 문장 길이와 상관없이 attention이 성능 개선에 기여했다는 것을 의미한다.
실험 결과
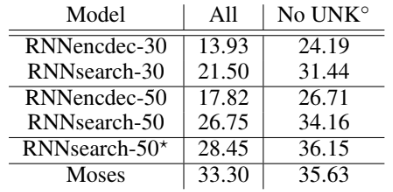
정량적인 평가를 위한 BLEU 점수다. RNNsearch가 RNNencdec보다 성능이 우수하다는 것이 분명하게 나타난다. 또한 알려진 단어로 구성된 문장만 고려할 때 RNNsearch의 성능이 기존 구문 기반 번역 시스템(Moses)만큼 높다는 것을 알 수 있다. 이는 Moses가 별도의 언어 말뭉치를 사용한다는 점을 고려하면 중요한 성과로 볼 수 있다.

정성적인 비교를 위한 번역 예시다. RNNencdec-50은 [medical centre]까지 원본 문장을 정확하게 번역했다. 그러나 이후 밑줄 친 부분은 원래 의미에서 벗어났다. 예를 들어, 원본 문장의 [based on his status as a health care worker at a hospital]가 [en fonction de son état de santé](“그의 건강 상태에 따라”)로 대체되었다. 반면 RNNsearch-50은 세부 사항을 생략하지 않고 입력 문장의 전체 의미를 보존하면서 올바른 번역을 생성하였다.
Reference
논문 링크 : https://arxiv.org/abs/1409.0473
'딥러닝 > RNN, LLM' 카테고리의 다른 글
| [RNN] WaveNet (1) | 2024.11.16 |
|---|---|
| [RNN] Pointer Networks (0) | 2024.11.15 |
| [RNN] Seq2Seq (0) | 2024.11.13 |
| [RNN] GRU (1) | 2024.11.12 |
| [RNN] LSTM (2) | 2024.11.11 |