키워드
1. 원시 오디오 데이터를 생성하기 위한 확장 가능한 RNN 기반 모델 제안. 음성 합성 분야에 혁신적 기여.
2. "WaveNet: A Generative Model for Raw Audio"
3. WaveNet, Dilated causal convolution, Gated activation, TTS
WaveNet

WaveNet은 오디오 파형을 생성하기 위한 Deep NN이다. 이는 이미지의 복잡한 분포를 모델링하는 PixelCNN 같은 autoregressive generative 모델서 영감을 받은 모델이다. 즉, 출력은 완전히 확률적이며, 각 오디오 샘플에 대한 예측 분포는 모든 이전 샘플을 기준으로 조정된다. 모델에 적용된 가장 큰 특징은 long-term dependence를 처리하기 위해, 매우 큰 receptive field를 가지는 dilated causal convolution을 기반으로 설계되었다는 것이다.
WaveNet은 초당 수만 개의 오디오 샘플이 포함된 데이터에 대해 효율적으로 훈련할 수 있다. 이렇게 훈련된 단일 WaveNet은 다양한 화자의 특징을 캡처할 수 있으며, 조건으로 특정 화자가 주어지면 해당 조건에 맞게 전환된다. 뿐만 아니라 음악을 모델링하도록 훈련시키면 매우 사실적인 음악 단편을 생성하고, 음소를 인식하는 판별 (discriminative) 모델로 사용될 수도 있다.
Architecture
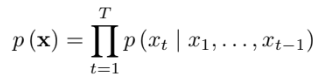
기본적으로 출력은 파형 𝐱={𝑥1,…,𝑥𝑇}에 대한 조건부 확률의 곱으로 표현할 수 있다. 각 오디오 샘플 𝑥𝑡은 모든 이전 단계의 샘플을 의미하며, 어떤 샘플이 존재하는지에 따라 확률이 조정된다. 네트워크에는 pooling 레이어가 없으며 모델의 출력은 입력과 동일한 차원을 가진다.
Dilated causal convolutions

WaveNet의 주요한 구성 요소는 Causal convolution이다. 위 이미지처럼 이전 step 정보만 연산에 활용하는 구조로, 이를 통해 모델이 데이터를 모델링할때 순서를 지키도록 한다. 이는 미래를 보고 예측을 할 수 없다는 것을 의미한다.
훈련 시에는 모든 time step의 Ground Truth 𝐱가 알려져 있으므로 모든 단계에 대한 조건부 예측을 병렬로 수행한다. 이후 생성할 때는 예측은 순차적으로 수행하고, 각 샘플이 다음 샘플을 예측하기 위해 네트워크로 피드백된다. Causal convolution은 반복 연결이 없기 때문에 일반적으로 RNN보다 훈련 속도가 더 빠르며, 특히 매우 긴 시퀀스에 효과가 두드러진다.
단순 causal convolution의 문제점 중 하나는 receptive field를 늘리기 위해 많은 레이어나 큰 필터가 필요하다는 것이다. 이러한 문제는 dilated convolution을 사용하여 계산 비용을 크게 늘리지 않고 receptive field를 수십 배로 늘릴 수 있다. Dilated convolution이란, 특정 간격으로 입력 값을 건너뛰어 더 큰 영역에 필터가 적용되게 하는 convolution으로 일반적인 conv보다 더 거칠게(coarse) 동작한다. 아래는 dilated 1, 2, 4, 8에 대한 dilated causal convolution을 묘사한 이미지다.

위 와 같이 stacked dilated causal convolution을 사용하면 네트워크 전체에 대해 계산 효율성을 유지하면서 단 몇 개의 레이어만으로 매우 큰 receptive field를 가질 수 있다. 예를 들어, 각 1,2,4,…,512 dilated 레이어 층은 1024 크기의 receptive field를 가지며 1×1024 conv보다 효율적이고 더 많은 non-linearity가 존재한다. 즉, exponential 하게 dilated factor를 증가시키면 깊이에 따라 receptive field도 exponential하게 증가하고, 이를 통해 모델 용량도 증가한다.
Softmax
데이터가 이미지의 픽셀 값이나 오디오처럼 연속적인 경우에도 softmax 분포가 더 잘 작동하는 경향이 있다. 이는 categorical 분포는 분포의 모양을 가정하지 않기 때문에 더 유연하고 임의의 분포를 쉽게 모델링할 수 있기 때문이다.
Raw 오디오는 일반적으로 16비트 정수 값 시퀀스로 저장되므로 단계당 65,536개의 softmax 확률을 출력해야한다. 이를 μ-law companding transformation으로 256개의 값으로 양자화하였다. 이 비선형 양자화 방식은 단순한 선형 양자화 방식보다 성능이 좋으며, 음성의 경우 재구성된 신호가 원본과 매우 유사하다.
Gated Activation Unit

WaveNet은 Gated activation이 ReLU 보다 좋은 성능을 보였다. 이를 계산하는 식은 위와 같다. 각각 *는 convolution 연산자, ⊙는 dot product 연산자, 𝜎(⋅)는 시그모이드 함수, 𝑘는 레이어 인덱스, 𝑓 및 𝑔는 각각 필터와 게이트, 𝑊는 학습 가능한 convolution 필터를 의미한다.
Residual and Skip connection

Skip connection은 네트워크 전체에서 사용되며 수렴 속도를 높이고 훨씬 더 깊은 모델의 훈련을 가능하게 해준다. 최종적으로 skip connection까지 추가하면 위 이미지와 같이 전체 아키텍처를 구할 수 있다.
Conditional WaveNet
WaveNet에 추가 조건을 입력하면, 해당 조건에 맞게 출력을 구한다. 예를 들어 음악 생성 모델에 장르나 악기를 입력하면 해당 조건에 맞게 음악을 생성하게 되는 것, 그리고 TTS에서 입력한 문장을 음성으로 출력하는 것이다. 이는 추가 입력 h가 주어지면 주어진 조건에 맞는 오디오의 조건부 분포 𝑝(𝐱∣h)를 모델링한다고 볼 수 있다. 이를 계산하는 방식은 크게 두가지다.

먼저 글로벌 컨디셔닝(Global Conditioning)은 모든 time step 출력 분포에 영향을 미치는 단일 latent 표현 h를 학습하는 방법으로, 이에 따른 activation은 위와 같다. V는 학습 가능한 linear projection이며 시간 차원에 브로드캐스팅된다.

다음은 로컬 컨디셔닝(Local Conditioning)으로 이는 TTS 모델의 문장 정보같이 오디오보다 길이가 짧은 경우에 활용된다. 이 시계열을 오디오 신호와 동일한 크기를 가지는 새로운 시계열로 매핑(y = f(h))한 뒤, activation에 추가한다. 𝑉𝑓,𝑘 * y는 1×1 conv이다.
결과
Multi-speaker speech generation
첫 번째 실험은 음성 생성이다. 모델은 텍스트를 입력으로 받지 않았기 때문에, 실제로 존재하지 않지만 인간의 언어와 유사한 단어를 현실적인 억양으로 부드럽게 생성한다. 이러한 이유는 long-term dependence가 부족하기 때문인데, 모델의 receptive field는 생성한 마지막 2~3개의 음소 정도로 제한되어 있기 때문이다.
그리고 원-핫 인코딩을 조건으로 조정하여 다양한 화자의 음성을 모델링하게 되면, 데이터셋의 109개 화자 모두의 특성을 포착할 만큼 강력한 성능을 보인다. 특히 단일 화자만을 대상으로 훈련하는 것보다 검증 세트에서 더 우수한 성능을 보였다. 이는 WaveNet의 내부 표현이 여러 화자 간에 공유되었음을 의미한다. 부가적으로 음성 자체 외에 오디오의 다른 특성도 포착하는데, 음향과 녹음 품질은 물론 화자의 호흡과 입 움직임도 모방한다.
Text to Speech (TTS)
TTS에 사용된 데이터셋은 북미 영어 24.6시간의 음성 데이터, 중국어 34.8시간의 음성 데이터로 구성되어 있다. TTS 작업을 위한 언어적 특징을 학습하기 위해 로컬 컨디셔닝이 수행되었으며, 이에 추가로 해당 언어가 가지는 기본적인 특징의 주파수 F0를 logF0로 추가 학습하였다.
TTS 작업에 대한 WaveNets의 성능을 평가하기 위해 subjective paired comparison과 MOS(Mean Opinion Score) 테스트를 수행하였다. 첫 번째 평가는 사람들이 선호하는 것을 선택하지만 선호하는 것이 없으면 "중립"을 선택하며, 두 번째 평가는 5개의 점수(1: 나쁨, 2: 나쁨, 3: 보통, 4: 좋음, 5: 매우 좋음)로 평가를 한다.
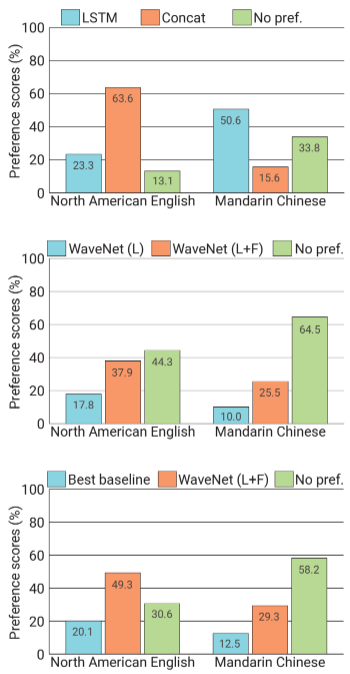
WaveNet은 두 언어 모두에서 baseline보다 성능이 뛰어났다. 다만 Local Conditioning을 기반으로 한 WaveNet이 자연스러운 분할 품질의 음성 샘플을 생성하지만, 때로는 잘못된 단어를 강조하여 부자연스러운 운율을 생성하였다. 이는 receptive field가 240ms로 long-term dependence를 포착할 만큼 길지 못하기 때문이며, logF0를 통해 이를 보완할 수 있었다.
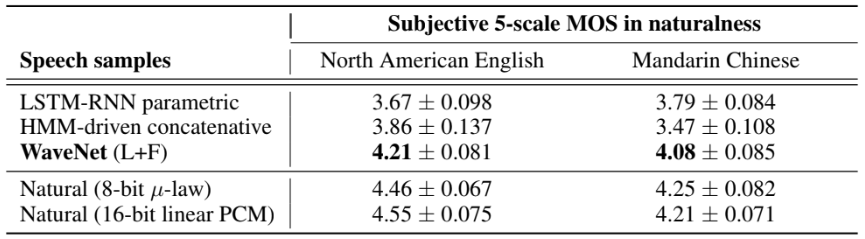
MOS 평가에서도 WaveNets는 4.0 이상의 점수로 baseline 보다 훨씬 뛰어난 성능을 보였다.
Music
정량적으로 평가하기는 어렵지만 생성된 샘플을 통해 주관적인 평가를 하였다. 실험적으로 receptive field를 확대하는 것이 더욱 음악적으로 들리는 샘플을 얻는 데 중요하게 작동하였다. 몇 초 수준의 큰 receptive field에서도 모델은 부족한 long-term dependence로 인해 장르, 악기, 볼륨 및 음질이 초 단위로 변했다.
하지만 흥미로운 것은 조건부 음악 모델이었다. 장르나 악기에 대한 태그 집합이 주어지면 해당 태그에 맞는 음악을 생성했다. 이는 원하는 속성을 인코딩하는 이진 벡터를 통해 샘플링 시 모델 출력의 다양한 측면을 제어할 수 있음을 의미한다.
Reference
논문 링크 : https://arxiv.org/abs/1609.03499
'딥러닝 > RNN, LLM' 카테고리의 다른 글
| [RNN] Reformer (4) | 2024.11.18 |
|---|---|
| [RNN] Transformer (3) | 2024.11.17 |
| [RNN] Pointer Networks (0) | 2024.11.15 |
| [RNN] Attention Mechanism (2) | 2024.11.14 |
| [RNN] Seq2Seq (0) | 2024.11.13 |