키워드
1. 트랜스포머의 메모리 및 계산 효율성을 개선한 모델 제안. LSH 및 반사동소를 통해 더 큰 시퀀스 처리 가능.
2. "Reformer: The Efficient Transformer"
3. Reformer, Transformer, Locality-sensitivity hashing, Reversible connection
Reformer (The Efficient Transformer)
Transformer는 다양한 작업에서 최고의 성능을 달성하지만 학습하는 데 비용이 많이 든다. 특히 음악, 이미지와 같은 긴 시퀀스를 활용하는 경우 그 영향이 더욱 부각 되게 된다. 또한 더 좋은 성능을 얻기 위해 많은 모델의 크기가 점점 더 커지고 있다. 이로 인해 현실적으로 대규모 산업 연구 실험실에서만 학습이 가능한 상황이다.
단순하게 Transformer 레이어에 사용된 파라미터 수는 0.5B으로 2GB의 메모리가 필요하다. 추가로 차원이 1024이고 배치가 8인 64K 토큰에 대한 activation은 64K×1K×8=0.5B을 차지하므로 추가로 2GB의 메모리가 필요하다. BERT를 훈련하는 데 사용되는 전체 코퍼스는 저장하는 데만 17GB 필요하다.
Reformer는 transformer의 비효율적인 부분을 개선한 모델이다. 크게 두 가지 구성요소로 효율성을 개선하였다. 먼저, dot-product attention을 locality-sensitive hashing attention을 사용하는 것으로 대체하였다. 이를 통해 복잡성을 O(𝐿2)에서 O(𝐿log𝐿)로 변경하였다. 추가적으로 chunk를 활용하여 feed-forward 레이어의 깊이 𝑑𝑓𝑓에 대한 메모리를 절약하였다.
그리고 일반적인 residual 대신 reversible(가역적) residual을 사용하였다. 𝑁 레이어가 있는 모델의 메모리는 역전파를 위해 activation를 저장해야 하기 때문에 단일 레이어 모델 메모리의 𝑁배가 필요하다. Residual residual은전체 모델에서 단일 activaion를 활용하므로 𝑁 요소가 사라진다.
효율성을 검증하기 위해 64K인 시퀀스의 텍스트 작업(enwik8) 및 길이가 12K인 시퀀스의 이미지 생성 작업(imagenet-64 생성)에서 실험을 진행하였다. Reformer는 Transformer 모델과 동등한 성능을 발휘하는 동시에 긴 시퀀스에서 훨씬 더 메모리 효율적이고 훨씬 빠르다.
Locality-sensitive hashing attention
Standard attention

Transformer에서 사용되는 attention은 scaled dot-product attention이다. 이는 value의 가중 합을 사용하는 방식이며, 가중치는 dk로 scaled된 query와 key의 dot-product를 softmax를 취해 구한다. 추가적으로 Q, K, V를 서로 다른 h개의 linear projection으로 나누어 계산하는 multi head attention 방식을 사용한다.
Attention mechanism에서 일반적으로 Q, K, V가 모두 [𝑏𝑎𝑡𝑐ℎ_𝑠𝑖𝑧𝑒,𝑙𝑒𝑛𝑔𝑡ℎ,𝑑𝑚𝑜𝑑𝑒𝑙]의 크기를 가진다. 메모리 관점에서 중요한 문제는 𝑄𝐾𝑇를 구하기 위한 계산에 있다. 만약 64𝐾인 시퀀스를 활용할 경우 배치 크기가 1인 경우에도 64𝐾×64𝐾 행렬이며, 32bit float에서 16GB의 메모리가 필요하다.
𝑄𝐾𝑇 행렬 중 일부만 메모리에 구체화(materialized)하여 Memory-efficient attention을 구현할 수 있다. 각 쿼리 𝑞𝑖에 대해 개별적으로 attention을 계산한 뒤, 단일 softmax에 대해서 계산한다. 이 방법은 효율성이 떨어질 수 있지만 𝑙𝑒𝑛𝑔𝑡ℎ에 비례하는 적은 메모리만 사용한다. 이 방법은 이후 실험의 baseline 모델에 적용되었다.
shared-QK Trasnformer
Reformer는 동일한 Q,K를 활용한다. Transformer는 서로 다른 파라미터를 사용하는 linear 레이어로 개별 Q, K, V를 구한다. 이와 달리 Reformer는 동일한 파라미터를 통해 Q, K를 구하며 V는 다른 파라미터를 통해 구하며, Q와 K가 같아진다. 이를 shared-QK Transformer라고 부른다. 여기서 q가 자기 자신을 attention하게 하지 않기 위해, K를 normalize한다.
위 표는 두 데이터셋에서 일반적인 QK와 shared-QK의 perplexity를 비교한 결과다. shared-QK의 성능이 떨어지지 않는 것을 알 수 있으며, 이는 정확성을 희생하지 않는다는 것을 의미한다.
Locality-sensitive hashing
Softmax는 가장 큰 요소에 dominant한 특성을 가진다. 이에 각 쿼리 𝑞𝑖에 대해 가장 가까운 k에만 집중하면 된다. 따라서 만약 K의 길이가 64K인 경우, 각 𝑞𝑖에 대해 가장 가까운 키 32개 또는 64개의 작은 하위 집합만 고려해도 크게 문제가 되지 않는다.
이러한 고차원 공간에서 가장 가까운 이웃을 빠르게 찾는 문제를 LSH(Locality Sensitive Hashing)를 통해 해결하였다. 각 벡터 𝑥를 locality-sensitive로 불리는 hash ℎ(𝑥)를 통해 hashing하는 방식으로, 벡터가 가까울 수록 높은 확률로 동일한 hash를 얻는다.
위 이미지는 이를 구현한 간단한 예다. 할당되는 hash bucket의 수 b는 4이며, 구형으로 투영된 점에 임의의 회전을 적용하고 해당하는 bucket을 구한다. 거리가 먼 위 두 벡터는 동일한 bucket을 공유할 가능성이 낮지만, 아래는 그와 반대되는 결과를 보인다.
Hashing을 사용하면 유사한 항목이 다른 bucket에 포함될 가능성은 적다. 다만 hashing을 여러번 반복하면 이 확률을 더 줄일 수 있다. 이를 multi-round LSH attention라고 하며 LSH attention을 𝑛번 병렬로 수행하는 것과 같다.
Locality-sensitive hashing attention
위 이미지는 full-attention과 LSH가 적용된 예시를 비교한 것이다. Full-attention은 attention matrix가 sparse하며 계산 관점에서 효율성이 떨어진다. LSH에서는 Q,K가 hash bucket에 따라 정렬되어 있다. 유사한 항목이 높은 확률로 동일한 bucket에 속하므로 각 bucket 내에서만 attention을 허용하며 full-attention을 근사화한다.
다만 이 방식의 hash bucket은 크기가 고르지 않은 경향이 있어 bucket 간에 일괄 처리가 어렵다. 또한 bucket 내의 query 수와 key 수가 동일하지 않을 수도 있다. 이에 쿼리를 bucket 별로 정렬하고, 이후 각 bucket 내에서 시퀀스 위치별로 정렬한다.이렇게 정렬된 attention matrix에서 동일한 bucket내 pair들은 대각선 근처에 클러스터된다. 여기에 𝑚개의 청크(chunk)를 통해 동일한 chunk 및 하나 직전의 chunk에 있는 같은 bucket을 attention한다.
추가적으로 Transformer 디코더에서 식에서는 마스킹을 통해 미래의 정보를 활용하지 못하게한다. 하지만 자기 자신에 대해서는 attention이 가능하다. 다만 shared-QK attention에서는, query 자체의 내적이 대부분 다른 위치에 있는 벡터와 query의 내적보다 크기 때문에 바람직한 방식이 아니다. 이에 토큰이 자기 자신을 attention하는 것을 원천적으로 허용하지 못하도록 마스킹을 수정하였다.
Analysis
LSH attention의 성능을 확인하기 위해 간단한 샘플을 생성하였다. 0𝑤0𝑤 형식의 일련의 기호가 반복되는 샘플로 길이가 3인 단어 𝑤의 경우 “0,19,113,72,0,19,113,72”가 하나의 샘플이 된다. 실험에는 𝑤의 길이가 511인 즉 입력 0𝑤0𝑤의 길이는 1024가 되는 샘플을 활용하였다.
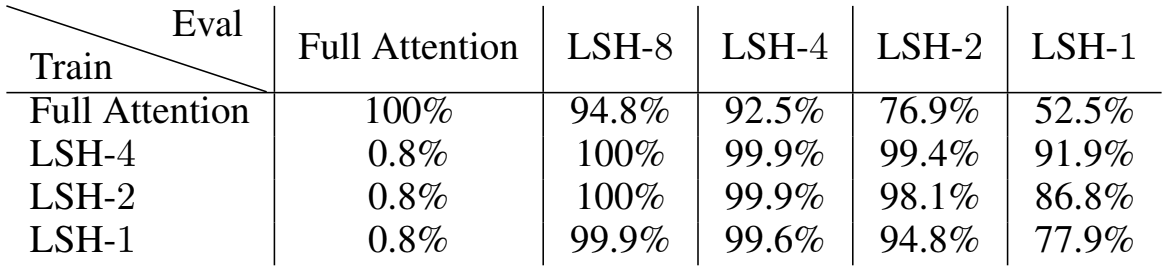
일반적인 Transformer 모델은 정확도 100%로 완벽한 성능을 보였다. LSH attention 학습 모델에 full-attention을 사용하는 경우, 제한된 범위의 Sparse Attention으로 인해 문제를 해결할 수 없다. 하지만 이와 반대로 full-attention 모델에 LSH Attention 으로 평가하는 경우 약간 손실만 보였다.
주목할만한 부분은 4개의 hash로 훈련한 모델에 LSH attention으로 평가해도 거의 완벽한 정확도를 달성한다는 것이다. 심지어, 단 1개의 hash로 학습된 모델이라도 8개의 hash로 평가하면 거의 완벽하게 수행한다. 이는 적당한 수의 hash를 사용하는 LSH attention이 정확도에 영향을 미치지 않는다는 것이다.
Reversible Transformer
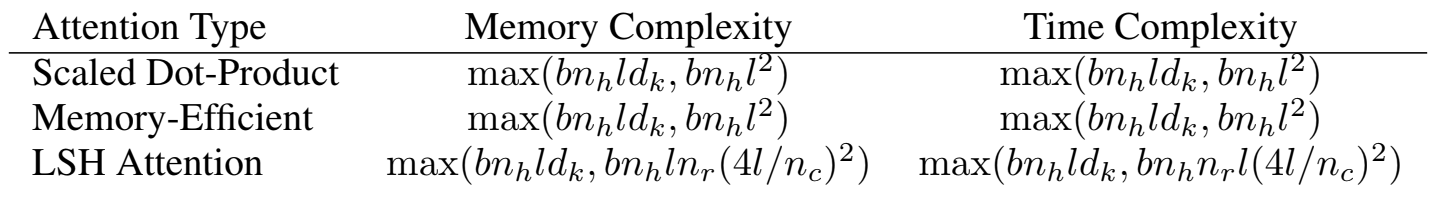
LSH를 통해 근사치의 활용이 허용된다면 attention의 복잡성은 length^2에서 length로 줄어든다. 하지만 𝑏⋅𝑙⋅𝑑𝑚𝑜𝑑𝑒𝑙(배치 수 * 길이 * 차원)에 해당하는 연산량은 여전히 필요하다. 여기에 𝑛𝑙 레이어를 사용하는 전체 모델의 메모리 사용량은 최소 𝑏⋅𝑙⋅𝑑𝑚𝑜𝑑𝑒𝑙⋅𝑛𝑙 가 필요하다. 특히 일반적인 경우에 이보다 더 큰 연산이 Transformer의 feedforward 레이어에서 필요로 한다. 𝑏⋅𝑙⋅𝑑𝑓𝑓⋅𝑛𝑙 가 필요하며, 𝑑𝑓𝑓=4𝐾 및 𝑛𝑙=16의 모델에 𝑙=64𝐾를 사용하면 16𝐺𝐵의 메모리를 사용한다.

Reformer 구조에서는 𝑛𝑙의 비효율성을 reversible 레이어를 통해 보완하였다. 더불어 chunking을 통해 𝑑𝑓𝑓를 효율적으로 처리하여 비용을 획기적으로 줄였다. 이에 따른 복잡성은 위와 같으며 각 구조에 대한 설명은 아래와 같다.
Reversible residual Network
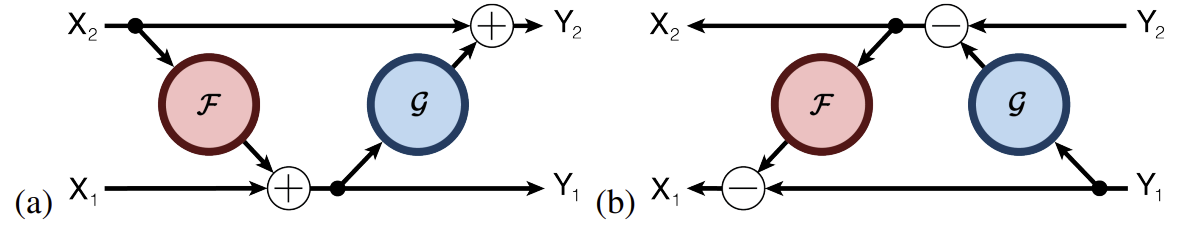
Reversible 레이어의 아이디어는 모델의 파라미터만 사용하여 특정 레이어의 activation으로 다음 레이어의 activation을 복구하는 것이다. 이는 backprop에서 사용하기 위해 중간 값을 저장할 필요 없이, backprop이 진행됨에 따라 레이어를 하나씩 역전파할 수 있다. 일반적인 residual 레이어는 단일 입력에 대해 작동하고 단일 출력을 생성하며 𝑦=𝑥+𝐹(𝑥) 형식이면, reversible 레이어는 입력/출력 쌍에서 작동하여 (𝑥1, 𝑥2)↦(𝑦1,𝑦2) 형태의 방정식을 따른다.

Reversible Transformer
RevNet 아이디어를 attention 과 feed forward 레이어에 적용하였다. F는 attention, G는 feed forward를 의미한다. Layer norm은 residual 블록 내부로 이동한다. 이를 통해 각 레이어에 activation을 저장할 필요가 없어 𝑛𝑙 을 제거할 수 있다. 또한 동일한 수의 파라미터를 사용할 때 기존 Transformer와 동일한 성능을 보인다.
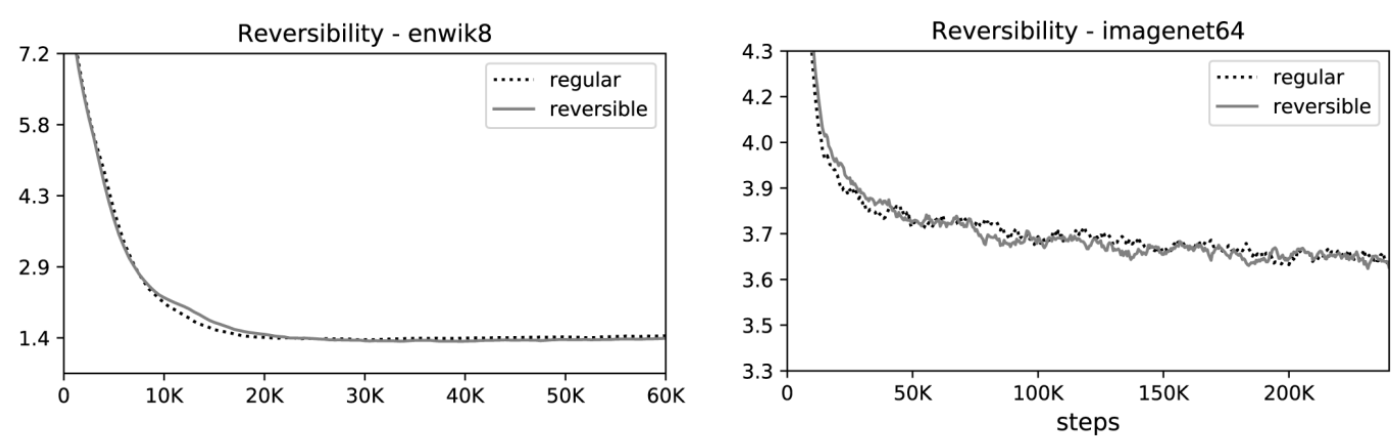
서로 다른 방식을 사용한모델의 learning curve다. 두 모델의 파라미터 수는 동일하며 학습에도 다른 차이를 보이지 않는다. 이를 통해 reversible transfomer의 메모리 절약이 정확성에 영향을 주지 않는다는 것을 알 수 있다.
Chunking
Reversiblity는 𝑛𝑙 을 제거하지만 여전히 레이어는 많은 메모리를 사용한다. 특히 feedforward 레이어는 차원 𝑑𝑓𝑓를 4𝐾 이상으로 사용한다. 이 feedforward 레이어의 계산은 시퀀스의 위치에 따라 완전히 독립적이므로 𝑐개의 chunk로 분할할 수 있다. 일반적으로는 병렬로 모든 위치에 대해 일괄 처리되는 것과 달리, chunk를 활용하여 한 번에 하나의 청크에 대해 작업하여 메모리가 줄어든다. Backward 패스도 chunk를 활용한다.
Large batch and parameter reuse
두 구조를 통해 전체 네트워크에서 activation에 사용하는 메모리가 레이어 수와 무관하게 되었다 하지만 파라미터의 경우에는 레이어 수에 따라 증가하게 된다. 이 문제는 레이어가 컴퓨팅을 수행하지 않을 때 파라미터를 CPU 메모리와 교환하여 해결할 수 있다. 기존 Transformer는 CPU로의 메모리 전송이 느리기 때문에 비효율적이다. 하지만 Reformer에서는 배치 크기에 길이를 곱한 값이 훨씬 더 크므로 파라미터를 사용하여 수행된 계산량이 전송 비용을 상쇄한다.
결과

영어- 독일어 번역 결과다. 비교 모델들과 동등한 성능을 보이는 것을 알 수 있다. 번역 예제는 단일 문장이고 문장이 상대적으로 짧은 경향이 있기 때문에 LSH attention을 적용하지 않았다. LSH attention은 hashing 및 정렬 후 128개 토큰 chunk를 사용하는 반면, 번역 테스트 세트의 예제는 모두 128개 토큰보다 짧다.
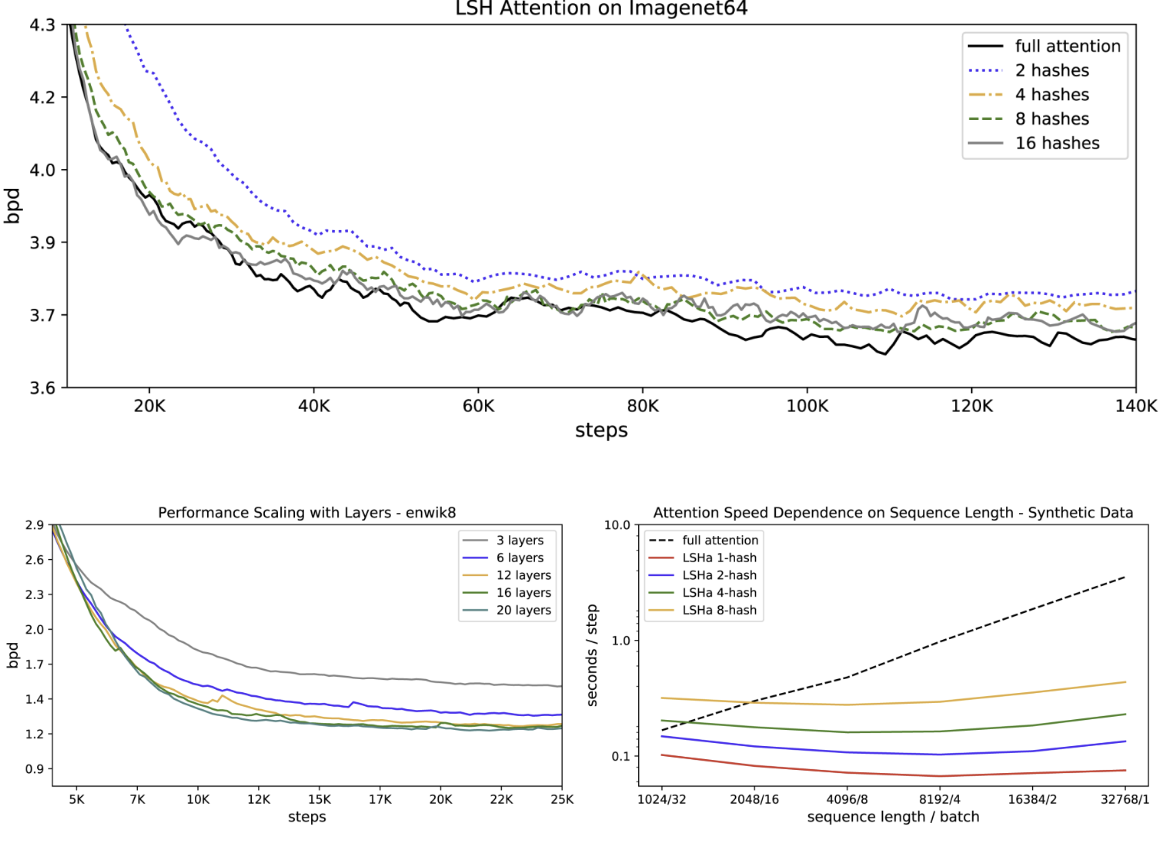
LSH attention는 full-attention의 근사치이며, hash 수가 증가할수록 더 정확해진다. 이미지 데이터셋 기준 𝑛=8이면 거의 full-attention과 성능이 동등해진다. 또한 시퀀스 길이가 길어질수록 full-attention은 속도가 느려지는 반면 LSH attention은 속도를 유지한다.
이 외에도 Reformer가 단일 코어에 대형 모델을 적용하고 긴 시퀀스에서 빠르게 훈련할 수 있는지 확인하기 위해, 최대 20개 레이어의 대형 Reformer를 훈련하였다. 훈련도 가능하였고 레이어가 늘어날 수록 성능이 개선되었지만, baseline인 기존 Transformer는 훈련 자체가 불가능하였다.
Reference
논문 링크 : [2001.04451] Reformer: The Efficient Transformer (arxiv.org)
'딥러닝 > RNN, LLM' 카테고리의 다른 글
| [RNN] Transformer (3) | 2024.11.17 |
|---|---|
| [RNN] WaveNet (1) | 2024.11.16 |
| [RNN] Pointer Networks (0) | 2024.11.15 |
| [RNN] Attention Mechanism (2) | 2024.11.14 |
| [RNN] Seq2Seq (0) | 2024.11.13 |