키워드
1. R-CNN의 속도 문제를 개선. RoI Pooling을 도입하여 후보 영역에서의 특징 추출을 가속화
2. "Fast R-CNN" (2015)
3. Fast R-CNN, R-CNN, Roi, Truncted SVD, Multi-task loss
더 빠른 Object Detection
객체 탐지에는 객체 인식 뿐만 아닌 정확한 위치 파악이 중요하다. 이 과정은 수많은 후보 영역을 계산하여 이루어지며, 후보 영역을 Localization 하여 대략적인 위치도 파악하게 된다. 이와 관련되어 R-CNN, SPPnet 등이 좋은 성능을 보였으나, 세 가지의 큰 단점이 있다.
- 훈련 pipeline이 multi-stage로 진행된다. Region proposal에 대해 ConvNet을 fine-tuning, Linear SVM training, bounding box regressor training 등 제각각 다른 역할을 하는 여러 단계를 학습해야한다.
- SVM 및 bounding box regressor 훈련의 경우, 각 이미지의 각 region proposal에서 feature가 추출되어 디스크에 기록되어 있어야한다. 이는 메모리를 크게 사용하는 문제가 있다.
- 결정적으로 속도가 느리다.
SPPnet은 전체 입력 이미지에 대해 feature map을 계산한 후, feature vector를 추출하여 사용하여 개선이 있으나, 메모리, 속도의 문제는 여전히 남아있다. 이에 Fast Region-based Convolutional Network (Fast R-CNN)이 등장하였다. Classification과 detection을 동시에 학습하는 single-stage detection으로 개선했다. Fast R-CNN은깊은 VGG16 네트워크를 R-CNN보다 9배 빠르게 학습시키고, 테스트 시 213배 더 빠르며, 더 높은 mAP를 달성하였다.
Architecture

Fast R-CNN 네트워크는 전체 이미지와 region-proposal을 입력으로 사용한다. 먼저 여러 컨벌루션(conv) 및 max pooling 레이어를 사용하여 전체 이미지를 처리하여 feature map을 생성한다. 그런 다음 각 region proposal에 대해 Region of Interest(RoI) pooling layer가 feature map에서 feature vector를 추출한다. 각 feature vector는 최종적으로 두 개의 FC 레이어에 입력되는데, 하나는 클래스와 배경에 대한 Softmax 출력이고, 4-d vector를 출력하는 또 다른 레이어는 bounding box의 위치를 인코딩한다. 여기서 R-CNN처럼 one-vs-rest linear SVM을 훈련하는 대신 softmax classifier를 사용했다. 바로 아래 소개할 세 가지 테스트 네트워크 모두에서 Softmax가 SVM보다 약간 더 뛰어난 성능났다.

Pre-trained CNN
- R-CNN과 동일한 AlexNet을 사용했으며, 깊이가 가장 얕기 때문에 이후 결과에서 S 모델로 명명했다.
- VGG_CNN_M_1024을 사용했으며, “S”와 깊이는 동일하지만 더 넓기 때문에 M 모델로 명명했다.
- VGG16를 사용했으며, L 모델로 명명 했다.
Fast R-CNN의 base network로 세 개의 미리 훈련된 ImageNet 네트워크를 활용했다. 또한, 마지막 max pooling 레이어를 RoI pooling 레이어로 변경되었으며, 이후 초기 입력 부분과 classifier 부분 또한 Fast R-CNN에 맞게 일부 변경되었다.
RoI pooling layer
RoI pooling 레이어는 max pooling을 사용하여 유효한 관심 영역 내부의 특징을 H × W(예: 7 × 7)의 고정된 크기를 갖는 작은 feature map으로 변환한다. 각 RoI는 왼쪽 위 모서리(r, c)와 높이 및 너비(h, w)를 지정하는 4개의 튜플(r, c, h, w)로 정의된다. 이에 RoI max pooling은 h × w RoI를 대략적인 크기 H × W 그리드로 나눈 그리드 별로 max pooling하는 방식으로 작동한다.
학습 시에는 Ground Truth bounding box와 0.5 이상 IoU가 겹치는 region proposal에서 RoI의 25%를 가져온다. 이는 실제 객체가 있는 예제들이다. 나머지 RoI는 [0.1, 0.5)의 범위의 IoU를 갖는 region proposal에서 샘플링한다. 이는 배경 예제를 의미한다. 이후 RoI pooling 레이어를 통해 backpropagation을 하며, 모든 네트워크 가중치를 훈련한다. 이러한 방식은 128개의 서로 다른 이미지에서 하나의 RoI를 샘플링 (R-CNN, SPPnet 방식) 하는 것보다 대략 64배 빠르다. 다만 동일한 이미지의 RoI가 서로 관련되어 있기 때문에 훈련 수렴이 느려질 수 있다는 문제는 있다.
여기서 region은 많으면 많을수록 좋을까? Object detector에는 sparse set과 dense set을 사용하는 두 가지 유형이 있다. sparse set은 cascade 형식이라고도 불린다. 아래는 Fast R-CNN을 selective search를 사용하여 학습하고, 테스트 시 이미지당 1,000개에서 10,000개의 region을 sweep 한 결과다. Region 수를 늘리면 mAP가 상승한 다음 약간 하락하는 것을 확인할 수 있다. 이에 더 많은 region은 정확성에 도움이 되지 않으며 심지어 악영향을 미친다고 볼 수 있다.

Truncated SVD
네트워크는 이미지와 R개(약 2000) region proposal 목록을 입력으로 사용한다. 네트워크를 통과하면 개별 RoI r에 대해 클래스 확률 p와 r에 대한 bounding box offset을 출력한다. Classification의 경우 FC 레이어를 계산하는 데 소요되는 시간은 conv 레이어에 비해 상대적으로 작다. 다만 detection을 위해 처리할 RoI의 수가 많기 때문에 FC 레이어에 많은 시간이 소요되며,이를 truncated SVD로 압축하여 쉽게 가속화할 수 있다. W를 파라미터로 갖는 레이어는 대략 다음과 같이 factorized 된다.
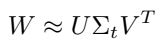
U는 W의 t개의 left eigenvector로 구성된 u × t 행렬, Σt는 W의 상위 t개의 eigenvalue를 포함하는 t × t 대각 행렬, V는 t개의 right eigenvector를 구성하는 v × t 행렬이다. 이를 통해 W에 해당하는 FC 레이어는 non-linearity 없이 두 개의 FC 레이어로 대체되며, truncated SVD는 파라미터 수를 uv에서 t(u + v)로 줄인다. 첫번째 레이어는 bias가 없는 ΣtVT, 두 번째 레이어는 원래 bias를 포함하는 U를 사용한다. 이는 RoI 수가 많을 때 속도를 향상시킨다.
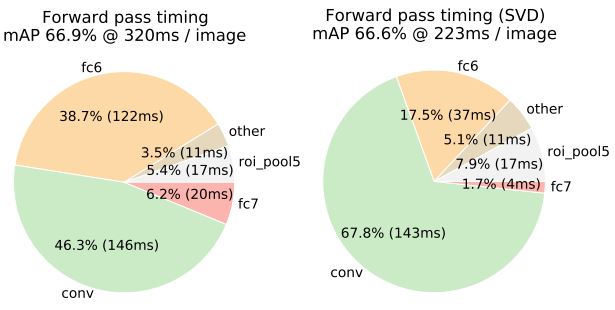
Truncated SVD 이전에는 fc6 및 fc7가 45%의 시간을 차지했다. 이후에는 전체 시간을 30% 이상의 줄였으며, 성능 저하는 0.3% 수준으로 크지 않았다. 25088 × 4096 행렬의 상위 1024개 eigenvector와 4096×4096 fc7 레이어의 상위 256개 eigenvector를 사용했으며, 추가 fine-tuning을 통해 mAP의 감소 폭을 줄이며 속도를 더욱 높일 수 있다.
학습
Multi-task loss
Fast R-CNN의 두 개의 출력을 계산하며, 첫 번째는 RoI당 K + 1개의 카테고리에 대한 이산 확률 분포, 두 번째는 객체 클래스에 대한 bounding box regresor offset tk =tkx, tky, tkw, tkh를 출력한다. 각 RoI에는 GT u와 GT bounding box target v가 레이블이 지정되며, 각 RoI에 multi-stage loss는 아래와 같다.
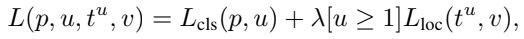
Lcls는 classification loss의 정의이며, Lloc은 target v = (vx, vy, vw, vh)에 대한 예측 tu = (tux, tuy, tuw, tuh)에 대해 정의된다. 하이퍼파라미터 λ는 두 작업 손실 사이의 균형을 제어한다. [u ≥ 1]는 클래스일때 1로 평가되고 배경이면 0으로 평가된다. 즉, 배경 RoI의 경우 GT가 없으므로 Lloc은 무시된다. 이에 따른 Bounding box regresor loss의 수식은 아래와 같다. 일반적으로 L2 손실을 사용한 교육에는 gradient 폭발을 방지하기 위해 learning rate을 신중하게 조정해야 하지만, smoothing을 통해 방지 할 수 있다.

Multi-task가 실제로 유의미한지 결과를 직접적으로 비교해보자. 아래의 이미지에서 각 모델 별로 첫번째 column은 Lcls만 사용하는 기본 네트워크이다. 두 번째 column은 제안된 loss를 사용했으나 bounding box regresion을 비활성화한 네트워크이다. 세번째 column은 첫번째 기본 네트워크에 bounding box regression을 추가, 다른 파라미터를 고정한채로 Lloc을 학습한 네트워크다. 네번째 column은 제한된 학습 방식이다. 이를 통해 multi-task가 유의미하다는 것을 알 수 있다.

Fine-tuning
Softmax classifier와 bounding box regersor를 동시에 최적화하는 하나의 단계로 간소화된 훈련 프로세스를 사용한다. Fine-tuning 단계에서 N개의 이미지를 샘플링한 다음 각 이미지에서 R/N개 RoI를 샘플링한다. 예시로 N = 2, R = 128 크기의 미니 배치를 사용하면 각 이미지에서 64개의 RoI를 샘플링한다. 이후 동일한 이미지의 RoI는 forward 및 backward pass에서 계산 및 메모리를 공유한다.
그렇다면 어느 레이어까지 fine-tuning 하는 것이 유익할까? 얕은 네트워크의 경우 FC 레이어만 fine-tuning하는 것만으로도 우수한 정확도를 얻는다. 다만 매우 깊은 네트워크에는 적용되지 않을 것이라고 예상된다. VGG16에서는 conv 레이어의 fine-tuing이 필요한지 검증하기 위해 Fast R-CNN을 사용하여 여러 case를 테스트했다.

VGG16의 경우, FC 레이어만 학습하도록 fine-tuning 하는 것보다, conv3_1 이상(13개 컨버전 레이어 중 9개)의 레이어만 fine-tuning하면 된다는 것이 확인되었다. 또한 conv1(입력에 가까운 레이어)의 학습을 허용하거나 허용하지 않는 것은 mAP에 의미 있는 영향을 미치지 않는다.
Scale-invariant
Scale-invariant object detection을 "무차별 대입(brute force)" 혹은 이미지 피라미드를 사용하여 학습할 수 있다. Single-sclae(무차별 대입) 방식은 훈련과 테스트 중에 각 이미지가 미리 정의된 픽셀 크기로 처리되며, 훈련 데이터로부터 scale-invariant를 직접 학습하는 것이다 Multi-scale 방식은 이미지 피라미드를 통해 네트워크에 대략적인 scale-invariant를 학습 전 미리 제공하는 것이다.

위 표는 두 방식을 비교한 결과이다. Single-scale 실험에서는 600픽셀을 사용하였고, multi-scale 실험에서는 5개의 480, 576, 688, 864, 1200 픽셀을 사용하였다. 결과를 통해 두 방식이 거의 동일한 성능을 발휘하였고, ConvNet은 scale-invariant를 직접 학습할 수 있고 해석 할 수 있다. 또한 Multi-scale은 계산 시간이 많이 소요되지만 mAP는 약간만 증가할 뿐이기에, single-scale이 속도와 정확성 사이에서 최상의 균형을 제공한다고 볼 수 있다.
결과

Fast R-CNN은 VOC12에서 최고의 성능을 보이며, "느린" R-CNN pipeline을 기반으로 하는 다른 방법보다 2배 더 빠르다. VOC07 에서 "어려움(diff)"으로 표시된 예제를 제거하면 Fast R-CNN mAP가 68.1%로 향상되는 점도 함께 확인할 수 있다.
훈련 및 테스트 시간

Fast R CNN, R-CNN 및 SPPnet 간의 VOC07에 대한 훈련 시간, 테스트 속도, mAP를 비교했다. R-CNN보다 146배, truncated SVD를 사용하면 213배 더 빠르게 이미지를 처리했다. Fast R-CNN은 또한 기능을 캐시하지 않기 때문에 수백 기가바이트의 메모리를 아낄 수 있다.
Reference
논문 링크 : https://arxiv.org/abs/1504.08083
'딥러닝 > Object Detection' 카테고리의 다른 글
| [Object Detection] SSD (0) | 2024.09.19 |
|---|---|
| [Object Detection] YOLO (0) | 2024.09.14 |
| [Object detection] Faster R-CNN (0) | 2024.09.12 |
| [Object Detection] R-CNN (0) | 2024.09.05 |
| [Object Detection] Object Detection의 발전 과정 (0) | 2024.08.31 |