키워드
1. 다양한 크기의 특징 맵을 사용하여 객체를 검출. 실시간 성능과 높은 정확도를 제공.
2. "SSD: Single Shot MultiBox Detector"
3. SSD, real-time, "zoom-out" augmentation, default box
Single Shot Detection
Object Detection을 구현하기 위해 region proposal을 통해 후보를 추리고, 각 영역의 이미지 또는 feature를 resampling 하여 classifier를 적용 하는 접근 방식이 많이 사용되었다. 특히 selective search는 가장 널리 사용되는 방식 중 하나였다. 이러한 접근 방식은 정확하기는 하지만 임베디드 시스템에서는 너무 계산 집약적이었고 심지어 고급 하드웨어에서도 real-time 애플리케이션에서는 너무 느렸다. 가장 빠르고 정확도가 높은 감지기인 Faster R-CNN도 7프레임(FPS)으로 작동하였다. 이에 detection을 위해 이미지나 feature를 다시 샘플링하지 않는 빠른 detection 네트워크를 필요로 하였다.
SSD(Single Shot Detection)는 단일 심층 신경망을 사용하여 이미지에서 객체를 탐지하는 방식이다. 이는 bounding box를 feature map에서 위치별 다양한 종횡비 및 크기에 대한 기본 상자(default box) 세트로 추출한다. 네트워크는 각 기본 상자에 있는 클래스 별 점수를 생성하고 객체 모양에 더 잘 일치하도록 상자를 조정한다. 이 과정에서 다양한 해상도의 여러 feature map의 상자를 결합하여 예측하기 때문에, 다양한 크기의 개체를 자연스럽게 처리할 수 있다.
모든 계산을 단일 네트워크에 캡슐화하기 때문에 region proposal이 필요한 방법에 비해 간단하며, 고정밀 detection 속도가 크게 향상되었다. 이러한 속도의 근본적인 개선은 region proposal과 후속 이미지 또는 기능 리샘플링 단계를 제거했기 때문이다. 또한 다양한 규모의 예측을 위해 여러 레이어를 사용하는 방식을 통해 상대적으로 낮은 해상도 입력을 사용하여 높은 정확도를 달성하고 감지 속도를 더욱 높일 수 있다.
Architecture
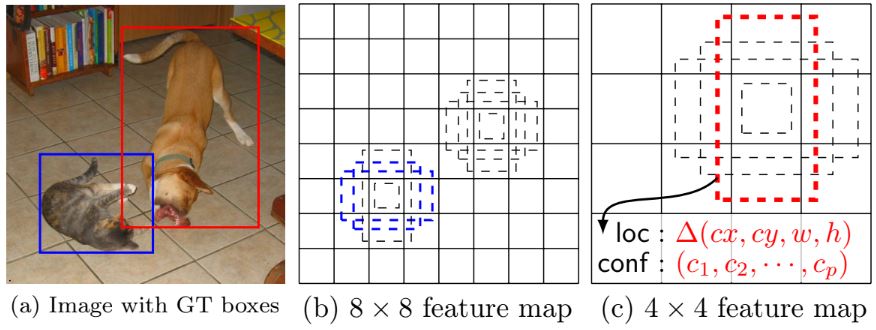
SSD 접근 방식은 고정된 크기의 bounding box 컬렉션을 생성하고 해당 상자에 객체 클래스 인스턴스가 있는지에 대한 점수를 생성한 다음, 최종적으로 NMS(non-maximum suppression)을 수행하는 CNN 네트워크이다. 초기 네트워크는 고품질의 classification 네트워크를 기반으로 하며 이를 기본 네트워크(base network)라고 한다. 이후 네트워크에 보조 구조를 추가하여 detection을 위한 아키텍처를 생성한다.
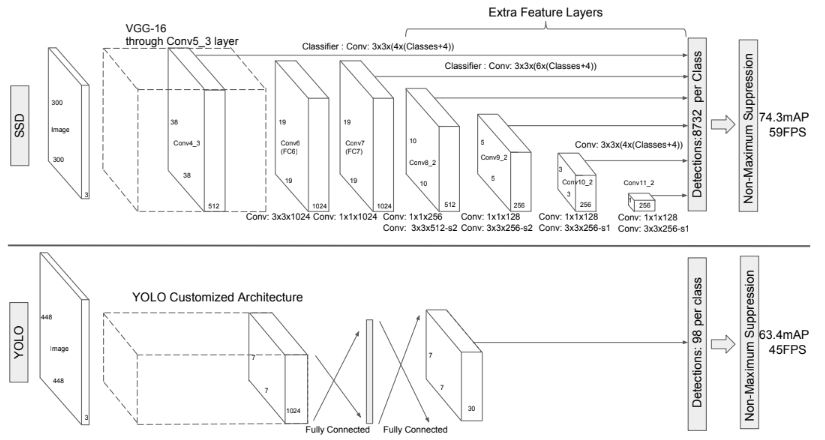
기본 네트워크의 끝에 conv 레이어를 추가적으로 사용하였다. 이 레이어의 크기는 점진적으로 감소하며 이를 통해 다양한 규모의 detection이 가능해진다. 이러한 conv 레이어를 포함하여 여러 feature map은 conv filter 세트를 사용하여 기본 상자(default box)를 생성하며, 기본적으로 3 x 3 의 작은 filter를 사용하여 각 카테고리에 대한 점수 및 좌표를 기준으로 오프셋을 생성한다. 각 feature map 크기 m×n 전체에 filter가 적용되어 출력 값이 생성되며, k개의 서로 다른 기본 상자가 사용되어 각 위치 별 (카테고리 수 + 4)k개의 filter가 사용된다. Detection을 위해 상하위 feature map을 모두 사용하는 것은 실제로 적은 계산으로 더 많은 정보를 사용할 수 있다.
이러한 기본 상자는 Faster R-CNN의 앵커 박스에서 사용되었지만 SSD에서는 이를 서로 다른 해상도의 여러 feature map에 적용했다는 차이점이 있다. 여러 feature map에서 다양한 기본 상자를사용하면 공간을 효율적으로 구분할 수 있다. 또 다른 차이점은 End-to-End 학습을 위해 여러 출력 세트 중 특정 출력에 정답 정보를 할당해야 한다는 것이다. 즉, 어떤 기본 상자가 정답에 해당하는지 결정해야 한다는 것이다. Threshold(0.5)보다 높은 jaccard overlap을 보이는 모든 기본 상자를 정답으로 선정하는 방식으로 학습이 진행되었으며, 최대로 겹치는 기본 상자만 선택하는 방식 보다 학습 문제를 단순화하는 효과를 유도한다.

또한 다양한 해상도의 feature map을 활용하는 것이 성능에 영향을 미친다. 이를 위해 점진적으로 레이어를 제거하며 살펴본 결과, 레이어 수가 적을수록 정확도가 단조롭게 떨어지는 것을 확인 할 수 있다. 그리고 이미지 경계에 있는 기본 상자에 대한 처리 관점에서 Faster R-CNN에서 제시된 제외 전략을 사용하면, 오히려 성능이 크게 저하되는 것을 볼 수 있다. 이는 가장자리의 큰 물체를 덮을 만큼 큰 상자가 작은 해상도의 feature map에서 제외되었기 때문이라 추측되며, 다양한 레이어에 다양한 규모의 상자를 펼치는 것이 중요하는 것을 시사한다.
기본 상자의 크기 및 종횡비
네트워크 내 여러 수준의 feature map은 서로 다른 receptive field를 갖는 것다고 볼 수 있다. 추가로 특정 feature map 개체의 특정 크기에 반응하도록 기본 상자의 타일링을 설계한다. 이에 따른 각 feature map의 기본 상자 크기는 아래 수식으로 계산한다. 만약 가장 낮은 레이어의 배율은 0.2이고 가장 높은 레이어의 배율은 0.9라고 가정하면, 그 사이의 모든 레이어는 규칙적인 간격을 가진다.
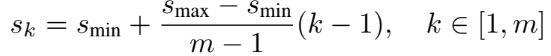
기본 상자에 대해 {1, 2, 3, ½, 1/3}의 서로 다른 종횡비를 적용한다. 이후 크기 sk와 종횡비의 제곱근를 사용하여 곱하면 너비, 나누면 높이를 계산할 수 있다. 추가적으로 sk*s(k+1)의 제곱근 크기를 가지는 기본 상자도 추가하며, 결과적으로 feature map의 위치당 6개의 기본 상자가 생성된다. 많은 feature map의 모든 위치에서 다양한 크기과 종횡비를 가진 기본 상자에 대한 예측을 결합함으로써 다양한 입력 개체 크기와 모양을 포괄하는 예측을 가능하게 한다.
Loss function
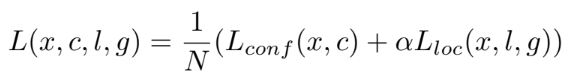
손실 함수는 localization 손실(loc)과 confidence 손실(conf)의 가중합으로 구성된다. 여기서 N은 일치하는 기본 상자의 수 이며, 만약 N = 0이면 손실은 0으로 설정한다. Conf 손실은 여러 클래스에 대한 softmax 손실이며, Loc 손실은 Faster R-CNN과 유사하게 예측(l) 및 Ground Truth(g) 간 regression을 사용한다.
Hard Negative mining
대부분의 기본 상자는 negative이며, 특히 기본 상자 수가 많은 경우 이러한 현상은 두드러진다. 이는 posi 훈련 샘플과 nega 훈련 샘플 사이에 심각한 불균형을 초래한다. 이에 모든 nega 샘플을 사용하는 대신, 기본 상자에 대해 nega와 posi의 비율이 최대 3:1이 되도록 가장 높은 신뢰도 손실을 보이는 상위 항목을 선택한다. 이를 통해 더 빠른 최적화와 더 안정적인 훈련이 가능하다.
Data Augmentation
- 원본 입력 이미지 전체를 사용
- Jaccard overlap이 최소 0.1, 0.3, 0.5, 0.7, 0.9인 패치로 샘플링
- 패치를 무작위로 샘플링
다양한 입력 개체 크기 및 모양에 대해 모델을 더욱 강력하게 만들기 위해 각 훈련 이미지는 위 옵션 중 무작위 하나로 샘플링된다. 이러한 augmentation을 통해 mAP는 8.8% 가량 향상되게 되는데, 패치를 통해 인식할 수 있는 모양이 다양해지고, 이를 통해 네트워크의 box 예측에 도움이 된다고 이해할 수 있다.

결과
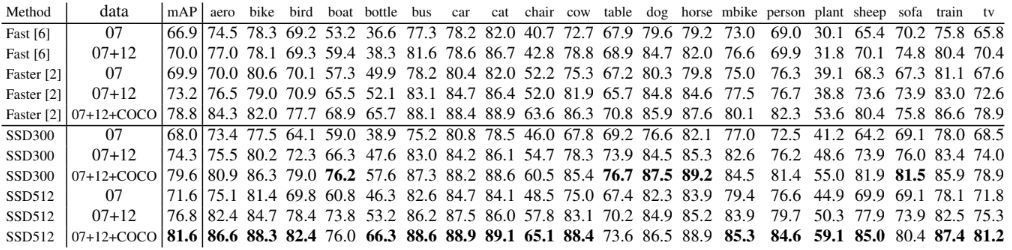

사전 훈련된 VGG16을 base 네트워크로 활용하였으며, 저해상도 SSD300 모델에서 이미 Fast R-CNN보다 더 정확하다는 것 확인할 수 있다. 더 큰 512에서 SSD를 훈련할 때 훨씬 더 정확하여 Faster R-CNN 보다 더 뛰어난 성능을 보인다. 또한 SSD300은 70% 이상의 mAP를 달성한 최초의 real-time 네트워크이다. 소요 시간 중 약 80%가 base 네트워크에서 소비되며, 더 빠른 base 네트워크를 사용하면 속도가 더욱 향상되어 SSD의 속도도 더욱 개선시킬 수 있다.
오류 분석

이후 두 SSD 모델의 성능을 더 자세히 이해하기 위해 오류 분석을 진행하였다. 차트를 통해 SSD가 다양한 개체 범주를 감지할 수 있다는 것을 알 수 있다. 이는 두 개의 분리된 단계를 사용하는 대신, 객체 모양을 회귀하고 객체 범주를 분류하는 방법을 직접 학습하기 때문에 SSD가 객체를 더 잘 위치화할 수 있음. 그러나 SSD는 유사한 개체 간 많은 오류를 유발하는 것을 볼 수 있는데, 이는 여러 범주에 대한 위치를 공유하기 때문이다.
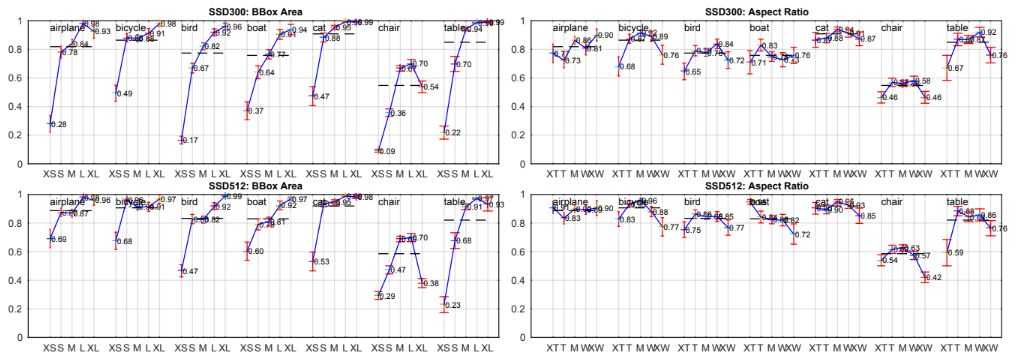
위 차트는 SSD가 boundinb box의 크기에 매우 민감하다는 것을 보여준다. 특히 더 작은 크기에서 성능이 훨씬 나쁘다. 이러한 작은 개체는 출력에 가까운 상위 레이어에 아무런 정보도 없을 수 있기 때문이다. 입력 크기를 늘려 작은 물체 감지를 개선하는 데 도움이 될 수 있지만 근본적인 개선은 어렵다. 긍정적인 부분은 SSD가 대형 개체에서 매우 잘 작동한다는 점, 다양한 종횡비에 매우 강력하다는 점이다.

이러한 작은 물체 감지의 어려움을 해결하기 위해 더 작은 훈련 예제를 생성하는 "zoom-out" augmentation을 수행한 결과이다. 이는 한 이미지에 16개의 무작위 이미지를 합쳐 수행되었으며, 더 많은 훈련 이미지를 얻었기 때문에 훈련 반복을 두 배 늘렸다. 이를 통해 mAP가 2%-3% 증가하는 것을 확인하였고, 동일한 분석에서 작은 이미지의 인식이 개선되었음을 알 수 있다. 이는 기본 상자의 더 나은 타일링을 통해 위치와 크기가 개별 feature map의 receptive field와 더 잘 정렬되었다고 볼 수 있다.

다른 네트워크와 비교
SSD 방법은 region proposal이 없고 기본 상자를 사용하여 한번에 detection을 수행하는 구조다. 이와 유사한 네트워크를 가진 OverFeat는 객체에 대한 신뢰도 점수를 파악한 후 최상위 feature map에서 직접 bounding box를 예측한다. 다른 네트워크인 YOLO는 최상위 feature map 전체를 사용하여 여러 클래스에 대한 신뢰도와 bounding box를 모두 예측한다. 그 중 SSD가 다양한 측면의 기본 상자를 사용할 수 있기 때문에 다른 방법보다 더 유연하다는 장점이 있다.
만약 다양한 feature map이 아닌 최상위 단일 feature map에서 위치당 하나의 기본 상자만 사용하는 경우 SSD는 OverFeat와 유사해 질 것이며, Conv classifier 대신 FC 레이어를 추가하고 여러 종횡비를 명시적으로 고려하지 않으면 YOLO와 유사해질 것이다.
Reference
논문 링크 : https://arxiv.org/abs/1512.02325
'딥러닝 > Object Detection' 카테고리의 다른 글
| [Object Detection] RetinaNet (0) | 2024.09.26 |
|---|---|
| [Object Detection] YOLOv2 (YOLO9000) (3) | 2024.09.21 |
| [Object Detection] YOLO (0) | 2024.09.14 |
| [Object detection] Faster R-CNN (0) | 2024.09.12 |
| [Object Detection] Fast R-CNN (3) | 2024.09.07 |