키워드
1. Focal Loss를 도입하여 불균형 클래스 문제를 해결. 높은 정확도 제공.
2. "Focal Loss for Dense Object Detection"
3. Focal loss, RetinaNet, 1 stage detection, Feature pyramid network
2 stage detection vs 1 stage detection
현재까지 가장 높은 정확도를 보이는 object detection은 R-CNN을 기반으로한 2-stage detection 방식을 이다. 이와 반대로 1-stage detection은 매우 dense한 구조에도 샘플링이 더 빠르고 간단하지만 정확도에 뒤처졌다. 이러한 차이가 발생하는 이유에 대해 알아보자.
Dense detection의 훈련 중 나타나는 극단적인 객체-배경 클래스 불균형이 주요 원인이다. 2-stage detectin 에서는 이를 2단계 cascade, sampling heuristic으로 해결한다. Proposal을 적게 활용하여 대부분의 배경 샘플을 해결하거나, 객체 1 : 배경 3의 샘플을 이용하거나 Hard Negative Mining 같은 샘플링을 활용한다. 하지만 1-stage-detection은 이미지 전체에 대해 샘플링을 진행하며, sampling herusitic이 일부 적용되나 다량의 배경 샘플을 처리하기에 비효율적이다.
이를 해결하기 위해 잘 분류된 샘플에 할당된 손실의 가중치를 낮추도록 cross-entropy loss를 재구성하였으며, 이를 focal loss라고 부른다. 또한 효율성을 평가하기 위해 RetinaNet이라는 간단한 dense detection을 고안하였다. Focal loss로 훈련할 때 RetinaNet이 기존의 모든 2-stage detection의 정확도를 능가하는 동시에 1-stage detecion의 속도를 유지하였다.
손실 함수는 dynamic한 cross-entropy loss이며, 올바른 클래스에 대한 신뢰도가 높아짐에 따라 scaling factor가 0으로 감소한다.이 인수는 학습 중에 쉬운 예제의 손실를 자동으로 줄이고 모델을 어려운 예제에 빠르게 집중할 수 있게 한다. 새로운 손실 함수로 최고의 결과를 달성하였으며, focal loss은 outlier를 해결하기보다는 가중치를 낮춰 클래스 불균형을 해결하도록 설계되었다.
Focal loss

Focal loss는 훈련 중에 객체와 배경 클래스 사이에 극심한 불균형을 해결하도록 설계되었다. 우선 이진 분류에서 일반적으로 사용되는 cross-entropy(CE) 손실부터 살펴보자. CE 손실은 위 이미지에서 파란색 곡선으로 볼 수 있다. 이를 통해 쉽게 분류되는 샘플에서 (pt >> 0.5) 적지 않은 크기의 손실이 발생한다는 점이다. 즉,많은 수의 쉬운 예를 합산하면 이러한 작은 손실 값이 여러운 샘플의 손실을 압도해 버린다.
Balanced Cross Entropy

클래스 불균형을 해결하는 일반적인 방법은 가중치를 도입하는 것이다. 가중치 α는 클래스 1 일때는 α∈ [0, 1] 이며, 클래스가 -1 일때는 1 - α 의 값을 가진다. α 는 하이퍼파라미터로 활용할 수 있다. 이를 통해 위 식과 같이 정의할 수 있으며, 이 손실은 focal loss에 대한 실험 baseline이 되는 loss로 활용될 것이다.
Focal Loss
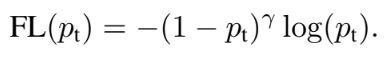
가중치 α는 posi/nega 샘플의 중요성의 균형을 맞춰주지만, 쉬운/어려운 샘플을 구분하지 않는다. Focal loss는 쉬운 예시의 비중을 낮춰 하드 네거티브에 대한 훈련에 집중하도록 유도한다. 이를 구현한 식이 위를 통해 확인 할 수 있다. (1-pt)를 통해 dynamic하게 가중치가 적용되며, 하이퍼파라미터 focusing γ는 γ ≥ 0의 범위를 가진다.
상단에 있는 차트가 γ ∈ [0, 5] 의 범위를 평가한 결과이다. 이를 통해 focal loss는 학습해야하는 샘플의 pt에 따라 손실에 반영되는 비중이 달라지며, γ를 통해 가중치가 낮아지는 속도를 부드럽게 조정할 수 있게된다. 즉, γ가 증가함에 따라쉬운 예제의 손실 기여도를 줄이고 쉬운 예제의 범위를 확장시켜준다. 만약 γ가 0이면 CE와 동일해진다.마지막으로, FL 사용 시 계산을 위해 sigmoid 연산과 결합해야 한다.
RetinNet의 각 이미지에는 100,000개의 앵커가 있다. 다른 아키텍처도 수 많은 샘플이 주어지며, samling heursitics(RPN) 또는 Onine Hard Example Mining(OHEM, SSD) 등을 사용하여 그 수를 줄인다. 하지만 FE를 활용하면 쉬운 예제들의 손실이 무시할 정도로 작기 때문에, 단순히 전체 FE의 합으로 계산한다. 또한 동일한 이유로 객체로 할당된 앵커 수를 기준으로 normalization을 수행한다.
CE vs FE
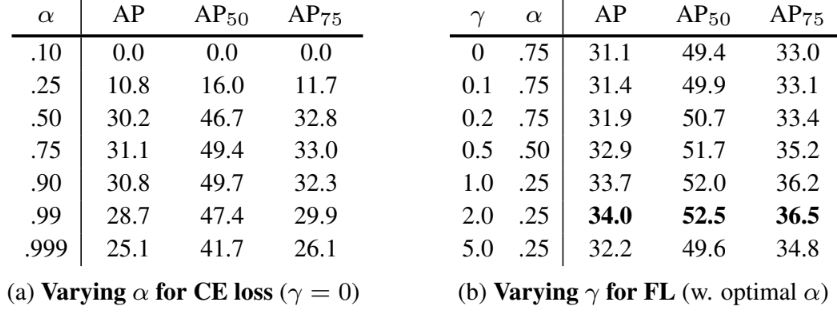
위 결과를 통해 FL가 CE에 비해 효과적이라는 점을 확인할 수 있다. 특히 CE에 단순히 가중치 α를 부여하는 것보다, FL γ를 함께 사용하는 것이 가장 이상적인 성능을 보인다는 것을 알 수 있다. 이는 두 파라미터가 posi/nega 샘플의 중요성에 균형을 맞추고 쉽고 어려운 샘플간 적정한 가중치를 부여한다는 것을 입증했다고 판단할 수 있다.
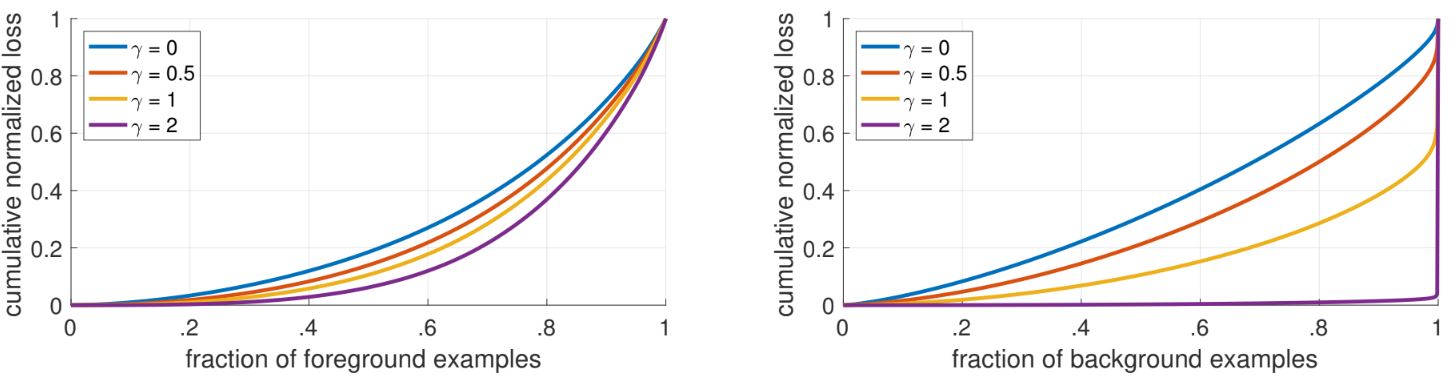
객체(foreground)와 배경에 대한 CDF를 검토하면, posi 샘플에선 CDF가 γ에 따라 유사한것을 확인할 수 있다. γ의 효과는 nega 샘플에서 더욱 극대화되는데, hard negative한 예제에 더 많은 가중치가 집중된다. 이를 통해 FL이 쉬운 부정의 효과를 효과적으로 무시하고 어려운 부정 예시에 모든 주의를 집중시킨다는 점을 확인할 수 있다. Y축은 학습시 확인된 loss를 0~1로 normalize 한 값이다.
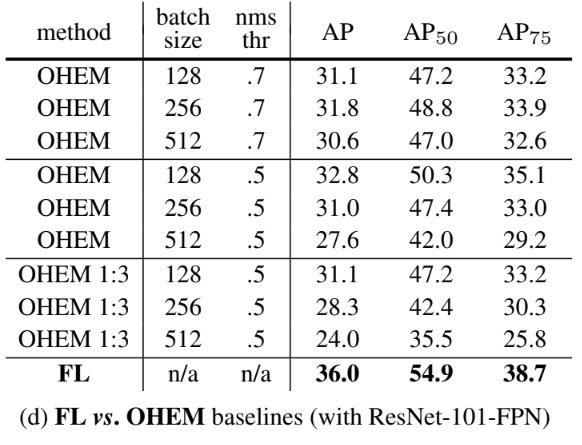
Online Hard Example Mining(OHEM) 과 FL을 비교한 결과이다. OHEM 은 FL과 달리 쉬운 예제를 완전히 삭제하는 방식으로 구현되며,SSD에는 OHEM의 변형인 1:3 비율을 적용하도록 미니배치가 구성된다.FL로 훈련된 ResNet-101을 baseline으로 사용하면 36.0 AP를 달성하며, dense detector에는 FL이 OHEM보다 더 효과적이라는 사실을 검증하였다.
RetinaNet

RetinaNet은 크게 backbone 네트워크와 두 가지 기능별 subnet으로 이루어진다. Backbone은 전체 입력 이미지에 대한 convolutional feature map을 계산하는 역할을 하며 ResNet을사용했다. 첫 번째 subnet은 backbone의 출력에 대해 classification, 두 번째 subnet은 bounding box regression을 수행한다.마지막에는 모든 예측이 병합되고 threshold가 0.5인 NMS(non-maximum supression)이 적용된다.
Backbone에는FPN(Feature Pyramid Network)을 사용했다.FPN은 top-down 경로와 측면(lateral) 연결을 사용하여 네트워크가 단일 해상도 입력 이미지에서 풍부한 multi scale feature 피라미드를 효율적으로 구성하도록 해준다. 이를 통해 구성되는 각 레벨은 서로 다른 규모의 물체를 감지하는 데 사용된다. 총 P3~P7의 feature map을 사용하며, 모든 레벨에는 256개의 채널이 존재한다.
Anchor
ReitnaNet은 RPN과 유사한 translation-invariant 앵커 상자를 사용한다. {1:2, 1:1, 2:1}의 종횡비와 {2^0, 2^(1/3), 2^(2/3)} 의 크기를 혼합하여 앵커를 구성하며, 레벨당 feature map의 모든 위치에서 9개 앵커를 사용한다. 그리고 각 앵커는 (클래스 수 + 좌표 4d)의 크기를 가지며, 0.5 IoU 이상인 경우 객체, 0.4 이하인 경우 배경으로 지정된다.

1 stage detection의 가장 중요한 요소는 이미지에서 box가 공간을 얼마나 전체적으로 밀도 있게 덮고있는지다. 이는 'anchor'를 통해 구현되며, 위치별로 다양한 크기와 종횡비를 사용한다. 위 표는 ResNet-50을 사용하여 다양한 비율을 검토한 결과이다. 앵커 수를 6~9개 이상으로 늘리더라도 성능 개선은 없으며, 추가적인 분류는 가능하지만 성능의 포화 상태로 판단할 수 있다.
Subnet
Classification subnet은 각 공간 위치에 객체가 존재할 확률을 예측한다. 각 FPN level에 연결되어 사용되며, subnet의 파라미터는 모든 FPN level에서 공유된다. 총 4개의 3x3 conv 레이어를 사용하며, 마지막에는 예측을 위해 K*A 개의 filter가 사용된다. 또한 최종 출력은 sigmoide activation이 적용된다. 또한 속도를 향상시키기 위해 confidence threshold를 0.05로 설정한 후 FPN level당 최대 1,000개의 상위 예측만 디코딩되게 하였다.
Box regression subnet은 classification subnet과 동일하게 모든 FPN level에 연결되며, box regression을 위해 마지막 레이어의 filter가 4로 끝나는 점을 제외하면 구조도 동일하다.앵커와 실제 상자 사이의 오프셋을 예측하며,두 서브넷은 구조는 동일하지만 별도의 파라미터를 사용한다.
클래스 불균형과 initialization
일반적으로 모델을 초기화할 땐 기본적으로 1 혹은 -1을 출력할 확률이 동일하도록 초기화한다. 하지만클래스 불균형이 존재하는 경우 더 많은 클래스의 손실이 전체 손실을 지배하고 초기 훈련의 불안정성을 초래한다. RetinaNet을 이러한 기본적인 초기화와 CE를 사용시 학습이 실패 경우가 존재했다.
이를 해결하기 위해 훈련 시작 시 희귀한 클래스에 대해 예측되는 p에 'prior' 개념을 도입했다. Prior를 π로 설정하고 p가 π보다 작아지도록 예측하도록 가중치를 초기화한다. 가장 마지막 conv 레이어의 biasb를 b = − log((1 − π)/π)로 설정하여 ~π의 confidence로 모든 앵커들이 객체로 레이블되도록 구현한다. 이를 통해 클래스 불균형이 심한 경우 CE, FL 모두에서 훈련 안정성을 향상시켰다.
결과

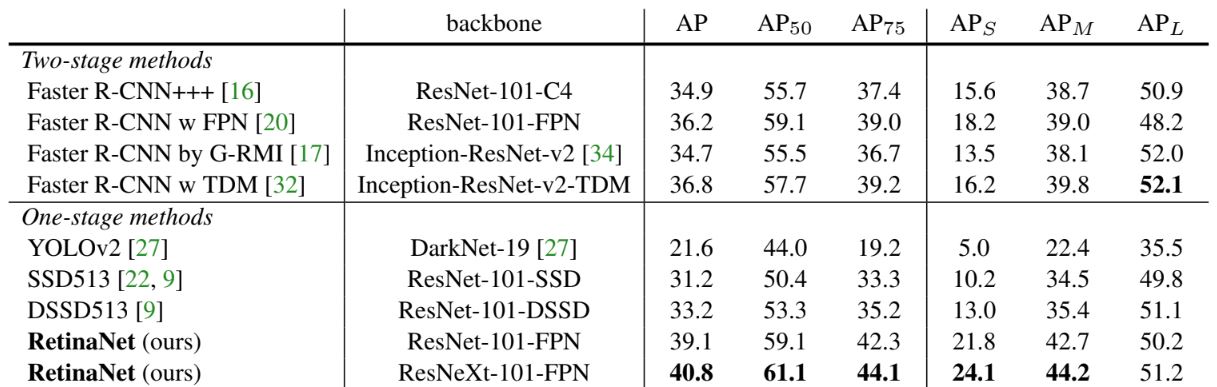
Backbone 네트워크가 클수록 정확성은 높아지지만 속도는 느려진다. 입력 이미지의 크기도 마찬가지 동일하다. 즉, 두 성능은 trade-off 관계이며, RetinaNet에 대한 하이퍼파라미터간 속도/정확도 결과와 다른 모델고 성능 차이를 확인하였다. Depth 101 및 600px 입력 이미지 크기의 ResNet을 backbone으로 사용한 RetinaNet은 동일한 backbone의 Faster R-CNN와 정확도과 동일했다.더 큰 크기를 사용하면 RetinaNet은 모든 2-stage-detection 정확성을 뛰어넘으면서 더 빠른 속도를 보인다. 또한 ResNeXt 32x8d-101-FPN을 backbone으로 RetinaNet을 설계하면 COCO에서 40 AP를 능가한다.
Reference
논문 링크 : https://arxiv.org/abs/1708.02002
'딥러닝 > Object Detection' 카테고리의 다른 글
| [Object Detection] EfficientDet (2) | 2024.10.03 |
|---|---|
| [Object Detection] YOLOv3 (1) | 2024.09.28 |
| [Object Detection] YOLOv2 (YOLO9000) (3) | 2024.09.21 |
| [Object Detection] SSD (0) | 2024.09.19 |
| [Object Detection] YOLO (0) | 2024.09.14 |