키워드
1. YOLO의 구조를 개선하여 작은 객체에 대한 검출 성능을 향상.
2. "YOLOv3: An Incremental Improvement"
3. YOLOv3, COCO Dataset, Darknet53
YOLOv3
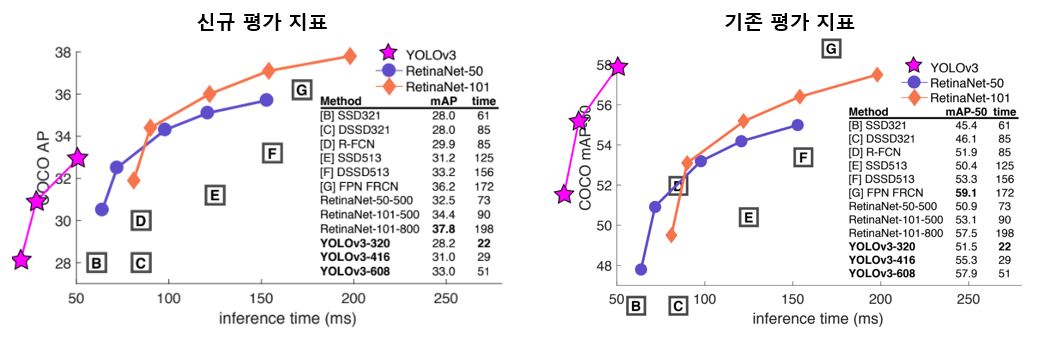
기존 YOLO를 일부 개선하였으며, SOTA를 달성한RetinaNet 대비 동등한 성능을 보이나 훨씬 빠른 속도를 보인다. 다만 논문에서 기술적인 부분보다 더 많이 언급한 듯한 COCO의 성능 평가 지표에 따라 그 수준 차이가 크게 달라짐을 알 수 있다. 아래 이미지는 신규 지표에서 동등한 성능을 보인 두개의 detector를 실제 이미지에서 테스트한 결과이다. 물론 정답을 둘 다 잘 맞추긴 하나, #2 는 추가적인 오류가 함께 발생한 것을 볼 수 있다. "실제 세계"의 사람들이 관심을 갖는 것과 우리가 생각하는 현재 측정 항목 사이에 명백한 괴리가 있다는 주장이다.

Architecture
Bounding box
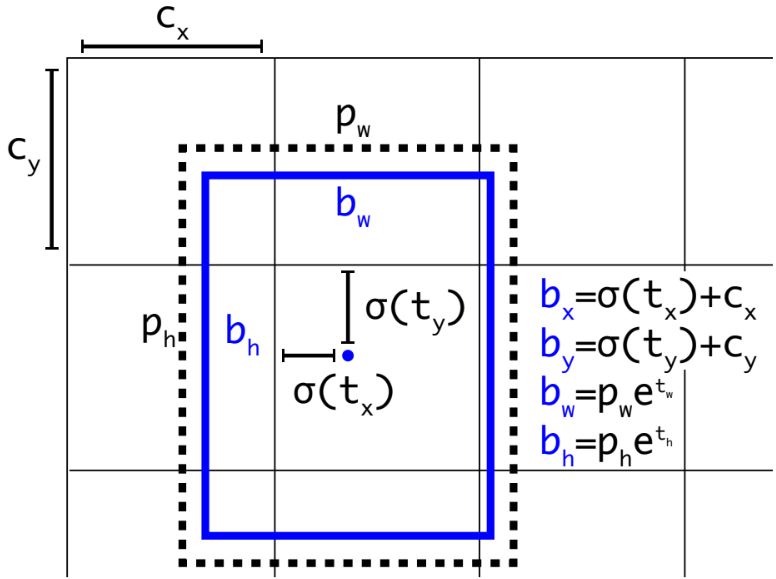
YOLO9000에서는 차원 클러스터를 앵커 상자로 사용하여 bounding box를 예측하고, 제곱합 loss를 사용했다. 이와 다르게YOLOv3는 logistic regression을 사용하여 각 bounding box에 대한 객체 여부 점수를 예측하고, 각 Ground Truth 객체에 대해 하나의 bounding box만 할당했다. 이를 통해Ground Truth 개체에 할당되지 않은 경우 좌표 또는 클래스 예측에 대한 손실은 발생하지 않고 개체 여부 점수만 손실을 역전파한다.
이와 관련하여 좌표를 예측하는 다른 방법도 시도했지만 기존 차원 클러스터가 최고의 방법이었다. 앵커의 x,y 오프셋을 예측하는 방식은 모델의 안정성을 감소시키고, logisitic 대신 linear한 x,y 를 예측하는 경우 성능 저하가 있었다. 또한 SOTA인 RetinaNet에서 제안한 Focal Loss의 경우, YOLOv3에선 큰 효과가 없었다. 그 이유는 단일 box만 할당하는 방식은 FL을 통해 해결하려는 불균형의 문제를 이미 해결했다고 볼 수 있기 때문이다.
Class prediction
Multi label classification을 사용하여 bounding box에 포함될 수 있는 클래스를 예측하였다. 이를 위해 일반적으로 사용되는 softmax를 사용하지 않고 대신 logistic classifier와 binary cross entropy loss를 사용했다. 이러한 방식이 채용된 이유는 중복되는 라벨에 대한 처리하기 위함이었으며, 데이터를 더 효과적으로 모델링한다.
Prediction Scale
YOLOv3 feature pyramid 네트워크와 유사한 개념을 사용하여 총 3가지의 scale에서 feature를 추출한다. 크기는 YOLO9000과 동일하게 k-means clustering을 사용했다.Base 네트워크의 feature에 여러 conv 레이어를 추가하였으며, 그 중 마지막 레이어는 bounding box, 객체 여부 및 클래스 예측을 인코딩하는 3d tensor를 출력한다. 즉, 개별 위치에서 3개의 상자를 예측하므로 tensor 의 크기는 " n × n × [3 * (4 + 1 + class 수)]" 와 같다.
또한 이전 2개의 레이어에서 feature map을 가져와 업샘플링하여 connection을 사용하여 업샘플링된 feature와 병합한다. 업샘플링된 feature에서 더 의미 있는 의미 정보를 얻을 수 있고 더 세부적인 정보를 획득 할 수 있다. 이를 위해 conv 레이어를 몇 개 더 추가하고 크기는 두 배로 늘어나지만, 모든 네트워크 세분화된 feature를 사용하는 이점을 누릴 수 있습니다.
Feature extractor (Darknet-53)
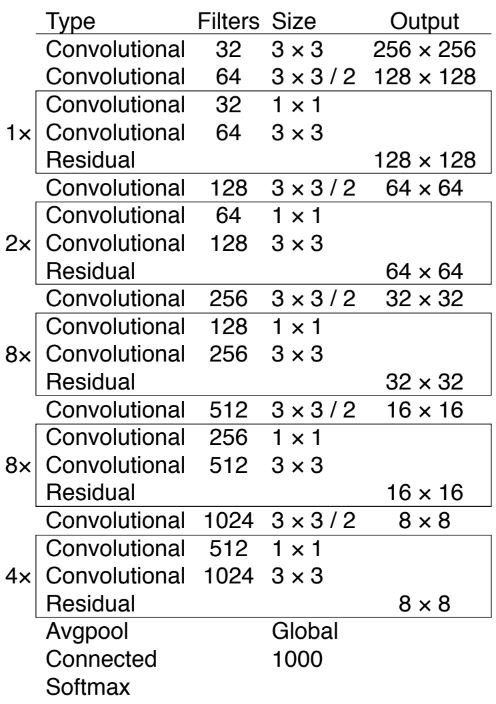
YOLOv2의 Darknet-19에서 사용되는 네트워크와 residual 네트워크 간의 하이브리드 방식의 새로운 아키텍처를 사용했다. 총 53개의 conv layer가 존재하기 때문에 Darknet-53으로 불리며, 1x1과 3x3 conv가 연속적으로 사용된다. 이러한 방식은 ResNet-101 보다 성능이 우수하며 속도도 2배 이상 빠르다. 이는 네트워크 구조가 GPU를 더 잘 활용하여 더 효율적이고 더 빨라진다는 것을 의미한다. 추가로 Multi-scale 훈련, augmenation, batch normalization 등 일반적인 기술들도 전부 활용 되었다.
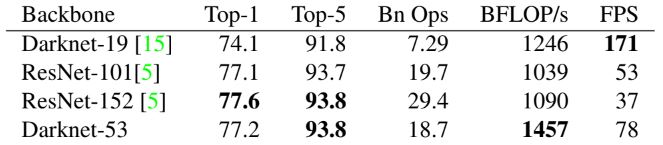
결과
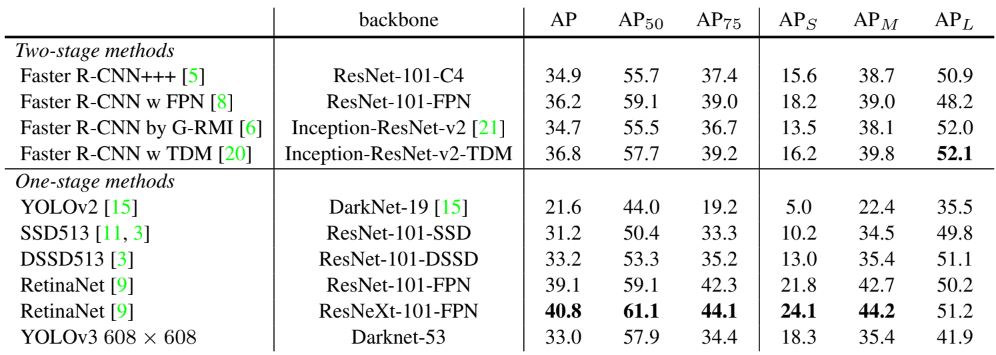
YOLOv3는 RetinaNet 등 다른 모델에 비해 성능이 상당히 뒤떨어져 있다. 다만 가장 처음에 언급했듯이 측정 기준에 따라 성능 차이가 매우 달라지며, 과거 지표 기준으로는 다른 모델보다 매우 강력한 성능을 보인다.이 는 IOU 임계값이 증가함에 따라 성능이 크게 떨어지며 YOLOv3가 box를 객체와 완벽하게 정렬하는 데 어려움이 있다는 것을 의미한다.
또한 과거 YOLO는 작은 물체의 감지에 어려움이 있었으나, 그러한 추세가 반전되고 있으며, multi-scale 예측을 통해 YOLOv3의 AP가 상대적으로 높아진 것을 알 수 있다.
Reference
논문 링크 : https://arxiv.org/abs/1804.02767
'딥러닝 > Object Detection' 카테고리의 다른 글
| [Object Detection] YOLOv4 (2) | 2024.10.05 |
|---|---|
| [Object Detection] EfficientDet (2) | 2024.10.03 |
| [Object Detection] RetinaNet (0) | 2024.09.26 |
| [Object Detection] YOLOv2 (YOLO9000) (3) | 2024.09.21 |
| [Object Detection] SSD (0) | 2024.09.19 |