키워드
1. YOLO 아키텍처의 속도와 정확도를 최적화.
2. "YOLOv4: Optimal Speed and Accuracy of Object Detection"
3. YOLO, Bag of Freebies, Bag of Specials
Detector의 발전
CNN 및 object detection 분야에서는 속도의 향상과 정확도를 향상시키기 위해 수많은 기능이 개발되어왔다. 다만 일부 기능은 특정 모델에서만 작동하고, 특정 문제에 대해서만 작동하거나, 특화된 데이터 세트에서만 작동한다. 반대로 Batch normalization, residual connection처럼 일반화가 아주 뛰어난 기능도 있다. 이에 이러한 기능의 조합에 대한 실제 테스트와 결과의 이론적 타당성이 필요하다.
YOLOv4는 다양한 기능을 분석하고 그 중 일부를 결합하여 우수한 성능을 달성했다. 또한 최신 신경망은 속도 측면에서 실시간으로 작동하지 않으며 대규모 배치 크기로 훈련하려면 많은 수의 GPU가 필요하다. 하지만 다양한 응용 분야로 기술이 확산되기 위해, 기존 GPU에서 실시간으로 작동하고 훈련 또한 기존 GPU 하나만 필요하도록 모델을 설계하였다. 따라서 주요 목표는 BFLOP(계산량 이론 지표)가 아닌 시스템에서 빠른 작동 속도를 설계하고 병렬 계산에 최적화하는 것이다. 이를 통해 효율적이고 강력한 object detection 모델을 개발하였다.
Basic Object Detection model

일반적으로 ImageNet에서 pretrain 된 backbone과 객체의 클래스 및 bounding box를 예측하는 head로 구성된다. 헤드 부분은 일반적으로 1 stage detection과 2 stage detection 두 가지로 분류된다. 그리고 backbone의 여러 단계에서 feature map을 수집하는데 이 부분을 neck이라고 부른다. Neck은 top-down 혹은 bottom-up으로 구성되며, 이러한 메커니즘을 FPN(Feature Pyramid Network)이라 말한다. 마지막으로 detection을 위해 feature의 특정 영역을 선정하는 앵커가 주로 사용되나, 앵커를 사용하지 않는 모델도 일부 개발되었다.
Bag of FreeBies
“Bag of FreeBies”란 훈련 방식만 바꾸거나 훈련 비용만 늘리는 방법을 말한다.
Data augmentation
입력 이미지를 변형하여 detector가 다양한 환경에서 얻은 이미지에 대해 더 robust하게 훈련 시키는 방식이다. 픽셀의 정보를 조정하여 새로운 이미지를 형성하거나, 객체를 일부 가려(occlusion) 새로운 이미지를 생성하기도 한다. 유사한 개념이 feature map에 적용되면 DropOut, Dropconnect, DropBlock 등으로 구현된다. 또한 단일 방식만 사용하는 것이 아닌 여러 이미지를 함께 사용하여 data augmentation을 구현한다.
Dataset bias
데이터셋의 분포에 bias가 있을 수 있는 문제를 해결하는 것도 하나의 방식이다. Hard negative example mining, Online hard example mining 등으로 해결되는 경우가 많다. 다만 2 stage detector에서만 가능하며 1stage detector에는 적용할 수 없습니다. 이를 위해 1 stage detector에서는 Focal loss를 대안으로 활용한다. 또한 One-hot hard 방식으로는 서로 다른 범주 간의 연관 관계를 표현하기 어렵다. 이에 라벨링 시 Hard 레이블을 soft 레이블로 변환하는 label smoothing을 도입하여 모델을 더욱 강력하게 만든다. 또한 더 나은 soft 라벨을 얻기 위해 label refinement 네트워크를 설계하기 위해 knowledge distillation 개념을 도입하여 활용하기도 한다.
Bounding box regression loss
일반적으로 MSE(Mean Square Error)를 사용하여 BB의 중심점 좌표와 높이 및 너비에 대한 regression를 직접 수행한다. 하지만 BBox의 각 점의 좌표값을 직접적으로 추정한다는 것은 좌표 x,y와 크기 w,h를 개별 독립변수로 취급하게 된다. 즉, 실제 객체를 고려하는 방식이 아니다. 이에 최근 IoU 손실이 활용되고 있으며, 이는 GT 영역에 대한 예측된 BB의 IoU를 손실로 활용하는 것이다. GIOU 손실은 IoU 외에 물체의 모양과 방향도 포함하는 개념이다. BB와 GT를 동시에 포괄할 수 있는 가장 작은 BB를 찾고 이 BB를 분모로 사용하여 원래 IoU 손실에 사용된 분모를 대체한 방식이다. DIOU 손실은 물체의 중심까지의 거리와 CIOU 손실을 추가적으로 고려한 것으로, 중첩되는 면적, 중심점 간 거리, 종횡비를 동시에 고려했다.
Bag of Specials
“Bag of Specials” 란 추론 비용을 약간만 증가시키지만 정확도를 크게 향상시킬 수 있는 모듈 및 후처리 방법을 의미한다. Receptive field 확대, attention 메커니즘 도입, feature 연결을 통한 feature 강화 등 모델의 특정 속성을 향상시키기 위한 방법들이다. 그리고 후처리는 모델 예측 결과를 선별하는 방법이다.
Receptive field
Receptive field을 향상시키는 모듈에는 SPP, ASPP, RFB 등이 있다. SPP 모듈은 SPM(Spatial Pyramid Matching)에서 유래되었다. SPM은 feature map을 여러 개로 분할하는 것으로, 동일한 d×d 블록으로 feature pyramid를 형성한 후 bag-of-word를 추출한다. SPP는 SPM을 CNN에 통합하고 bag-of-word 연산 대신 max-pooling 연산을 사용한 모듈이다. k = {1, 5, 9, 13} stride =1 의 k × k max pooling을 통해 다양한 receptive field를 활용하며 상대적으로 큰 k × k max pooling은 receptive field를 효과적으로 증가시킨다. ASPP는 3 x 3 kernel 크기를 사용하나 dilated convolution을 사용하며, RFB는 k x k kernel에 dilated ratio 또한 k를 사용하는 방식이다.
Attention
Detection에 자주 사용되는 Attention 모듈은 크게 Channel-Wise Attention과 Point-Wise Attention으로 구분되며, 이 두 Attention 모델의 대표적인 것이 Squeeze-and-Excitation(SE), Spatial Attention Module(SAM)이다. SE 모듈의 경우 계산량은 2%만 증가하지만 GPU에서는 일반적으로 추론 시간이 약 10% 증가한다. 하지만 SAM의 경우 추가 계산량이 0.1%만 필요하며 ImageNet 이미지 분류 작업에서 ResNet50-SE의 Top-1 정확도를 0.5% 향상시킨다.
Skip connection
Skip connection은 낮은 수준의 feature를 높은 수준의 feature에 통합하기 위해 사용되었다. FPN과 같은 multi-scale 예측 방법이 대중화됨에 따라 다양한 feature 피라미드를 통합하는 많은 경량 모듈이 개발되었다. SFAM은 SE 모듈을 사용한 multi scale feature map에서 channel-wise re-weighting을 구현하였다. ASFF의 경우 softmax를 통해 point-wise re-weighting을 구현한 다음 다양한 scale의 feature map을 추가하였고, BiFPN에서는 multi-input weighted 연결을 통해 scale-wise re-weighting을 구현한 후 다양한 크기의 feature map을 활용하였다.
Activaation
좋은 activation 함수는 기울기를 보다 효율적으로 전파할 수 있으며 동시에 너무 많은 추가 계산 비용을 발생시키지 않아야 한다. 전통적인 tanh 및 sigmoid activation 함수에서 자주 발생하는 기울기 소실 문제를 실질적으로 해결하기 위해 ReLU가 사용되었다. 이후 LReLU, PReLU, ReLU6, SELU, Swish, hard-Swish, Mish 등 수많은 변형이 등장하였다. LReLU와 PReLU은 출력이 0보다 작을 때 ReLU의 기울기가 0이 되는 문제를 해결하는 것이다. ReLU6 및 hard-Swish의 경우 quantization 네트워크용으로 특별히 설계되었고, self-normalizing를 위해 SELU activation 함수가 활용되었다. 마지막으로 Swish와 Mish 미분 가능한 activation 함수다.
NMS
딥러닝 기반 detector에 일반적으로 사용되는 후처리 방법으로 동일한 객체를 잘못 예측하는 Bounding Box를 필터링하고 가능성이 더 높은 Bounding Box만 유지하는 데 사용된다. 다만 전통적인 방법은 context를 고려하지 않았다. 이를 위해 신뢰도 점수를 참고로 추가하고, 신뢰도 점수 순서에 따라 높은 점수부터 낮은 점수 순으로 greedy하게 NMS가 수행되었다. Soft NMS는 occlusion으로 인한 신뢰도 점수가 저하될 수 있는 문제를 보완하였으며, DIOU NMS는 soft NMS를 기반으로 BB screening 과정에 중심점 거리 정보를 추가하였다. 마지막으로 앵커가 없는 방식에서는 이미지 특징을 직접 참조하지 않기 때문에 NMS가 필요하지 않다.
Architecture
최적의 모델을 구현하기 위한 방법은 backbone의 입력 네트워크 해상도, conv 레이어 수, 파라미터 수(필터 크기), 레이어 필터 수 간의 최적의 균형을 찾는 것이다. 그리고 receptive field를 증가시키기 위한 추가 블록을 선택하고 다양한 feature 레벨이 다양한 backbone의 feature를 포괄하는 최상의 방법을 선택해야한다. 또한 classifier와 달리 detector에는 다음이 필요하다.
- 더 큰 입력 이미지 크기 : 작은 크기 물체를 감지하기 위함이다.
- 더 많은 레이어 : 증가된 입력 이미지 크기로 인해 더 큰 receptive field 확보를 위한 많은 레이어가 필요하다.
- 더 많은 파라미터 : 단일 이미지에서 다양한 크기의 여러 물체를 감지하기 위해 모델의 용량이 충분해야한다.

또한 GPU에서 더 빠른 연산 속도를 얻기 위해 적은(1~8) conv 레이어 그룹을 사용하는 backbone을 활용하고자 했으며, 위는 네트워크 후보군에 대한 비교 자료이다. 앞서 언급했듯이 더 큰 receptive field와 파라미터 수를 가진 모델을 선정할 필요가 있었으며, 그 중 적절한 값을 가지는 CSPDarknet53 이 탐지기의 backbone으로서 최적으로 판단할 수 있다.
CSPDarknet53에 SPP 블록을 추가하였는데, 이는 receptive field를 크게 늘리고 context feature를 분리하면서 네트워크 작동 속도를 거의 저하시키지 않기 때문이다. 또한 PANet을 적용하고 앵커 기반 YOLOv3 헤드를 사용하여 YOLOv4의 최종 아키텍처를 선정하였다.
BoF와 BoS
Detector 훈련을 개선하기 위해 activation, bounding box regression, data augmentation, regularization, normalization, skip connection 등을 선정해야하며, 앞서 다양한 방법에 대해 소개했다. 이 중 대부분은 “가볍고, 빠르고, 정확한 아키텍처”에 맞는 적절한 방법을 선택하여 적용하였다. 기법을 선택하기 위해 비교 평가가 진행되었으며, mosaic, SAT, CmBN, Modified SAM, Modified PAN은 YOLOv4에서 개선되어 적용되었다..
Mosaic

Mosaic은 4개의 훈련 이미지를 하나의 이미지로 혼합하는 새로운 augmentation 방법이다. CutMix는 2개의 입력 이미지만 혼합하는 방식으로 더욱 많은 이미지를 혼합하였다. 이를 통해 일반적인 context 외부의 개체를 감지할 수 있게 되었으며, Batch normalization은 각 레이어의 4개의 서로 다른 이미지에서 activation 통계를 계산하기에 대규모 미니 배치 크기에 대한 필요성을 크게 줄일 수 있다.
SAT(Self-Adversarial Training)
SAT 또한 새로운 augmentation 기술로, 2개의 forward, backward 단계에서 이미지를 변형하는 기술이다. 첫 번째 단계에서 신경망은 네트워크 가중치 대신 원본 이미지를 변경하여, 이미지에 원하는 개체가 없다는 속임수를 만든다. 두 번째 단계에서 신경망은 이 수정된 이미지에서 일반적인 방법으로 객체를 감지하도록 훈련받게 된다.
CmBN, Modified SAM, Modified PAN
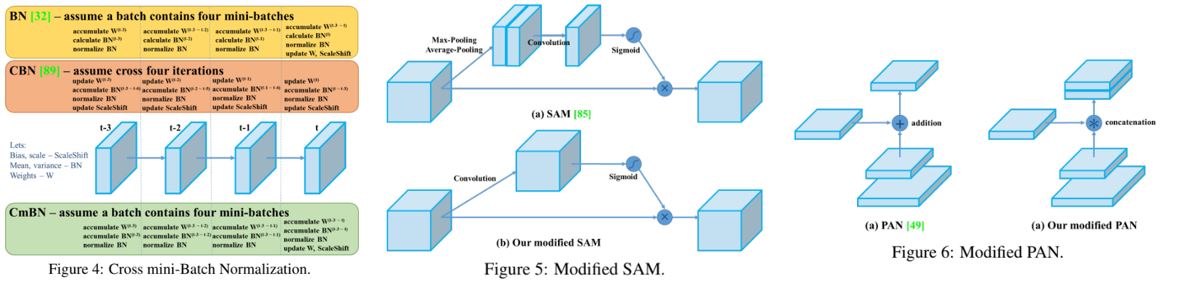
CmBN은 그림과 같이 CBN의 수정 버전으로, Cross mini-Batch Normalization 라는 이름에서 볼 수 있듯이 mini가 추가된 버전이다. 이는 단일 배치 내에서 미니 배치 간의 통계만 수집하는 방식이다. 그리고 SAM을 spatial-wise attention에서 point-wise attention으로 수정하였고 PAN의 연결 방식을 수정하였다.
Backbone 평가

다양한 기능의 영향을 비교한 자료이다. 결과적으로 backbone 훈련에는 가장 좋은 결과를 보인 cutMix, mosaic augmentation, class label smoothing이 적용되었으며, Mish activation를 함께 사용하였다.
Detector 평가

FPS에 영향을 주지 않고 감지기 정확도를 높이는 여러 BoF를 통해 성능을 향상시켰다. 각 항목의 의미는 다음과 같다. S: Grid sensitivity 제거 (YOLOv3에서 좌표를 평가하는 데 사용되었다) / M: Mosaic augmentation / IT: IoU threshold 사용 / GA: Genetic algorithm / CBN: CmBN / CA: Cosine annealing scheduler / DM: Dynamic mini batch size / OA: 최적화된 앵커 / GIoU, CIOU, DIOU, MSE - bounding box regression에 대해 서로 다른 손실 함수
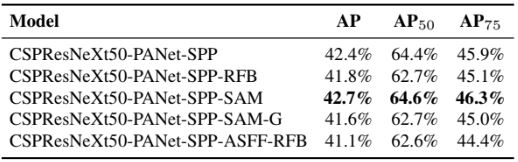
PAN, RFB, SAM, Gaussian YOLO(G), ASFF등 성능에 영향을 끼치는 BoS 항목도 평가를 진행하였으며, SPP, PAN 및 SAM을 사용할 때 최고의 성능을 보였다. 이에 따른 최종 조합은 아래와 같다.
- Backbone을 위한 BoF : CutMix, Mosaic data augmentation, DropBlock regularization, Class label smoothing
- Backbone용 BoS : Mish activation, Cross-stage partial connections (CSP), Multi-input weighted residual connections (MiWRC)
- Detector용 BoF : CIoU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training, Eliminate grid sensitivity, Using multiple anchors for a single ground truth, Cosine annealing scheduler, Optimal hyperparameters, Random training shapes
- Detector용 BoS : Mish, SPP, SAM, PAN path-aggregation, DIoU-NMS
Backbone과 pre-trained weight의 영향성
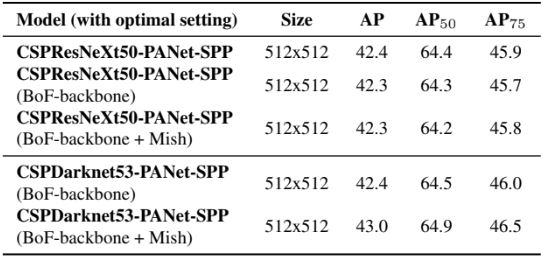
최종적으로 결정된 BoF, BoS 기반으로 서로 다른 backbone 모델에 따른 정확도를 비교하였다. CSPResNeXt 50 모델의 , classification 정확도는 CSPDarknet53 모델에 비해 높지만, detection 측면에서는 CSPDarknet53 모델이 더 높은 정확도를 보인다. 이를 통해 최고의 classification 정확도가 detection의 정확도 측면에서 항상 최고는 아니라는 점을 알 수 있다. 또한 CSPResNeXt50에 BoF와 Mish를 사용하면 classification 정확도가 높아지지만 detection에 pre-trained weight를 적용하면 정확도가 감소한다. 반대로 CSPDarknet53 BoF와 Mish를 사용한 classifier의 pre-trained weight를 사용하면 두 task에서 모두의 정확도가 높아진다. 이를 토대로 CSPDarknet53이 CSPResNeXt50보다 backbone으로 더 적합하다고 판단할 수 있다.
미니 배치 크기의 영향성
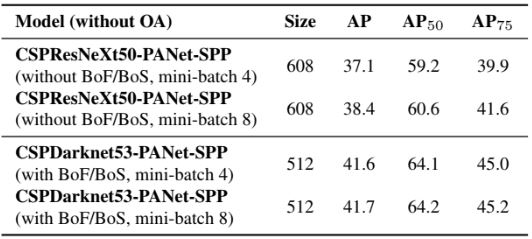
마지막은 다양한 미니 배치 크기로 훈련된 모델을 통해 얻은 결과다. BoF 및 BoS를 사용하게 되면 미니 배치 크기가 감지기 성능에 거의 영향을 미치지 않는다는 것을 발견하였고, 더 이상 훈련에 큰 배치 크기를 구현하기 위한 값비싼 GPU를 필요없다는 것을 의미한다.
결과
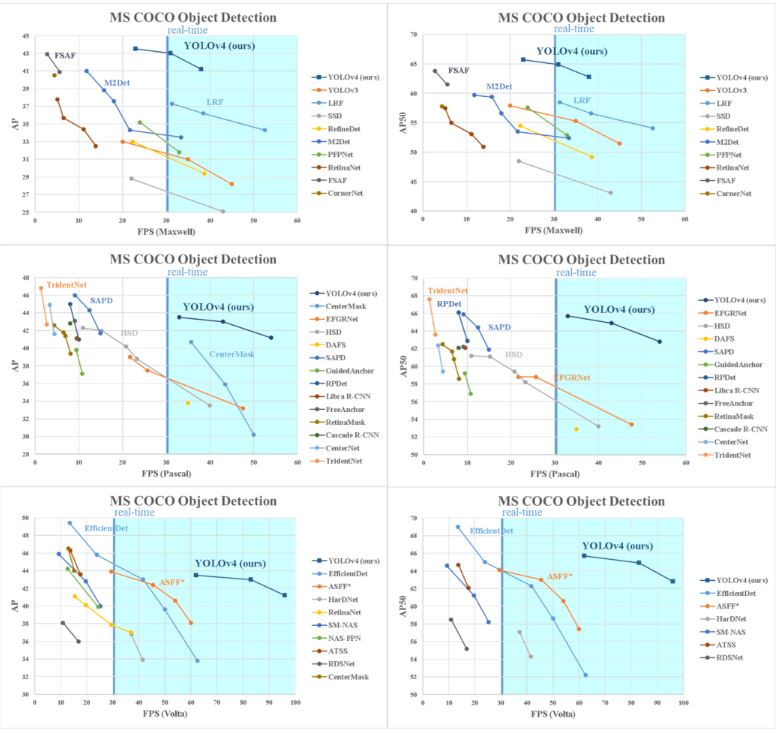
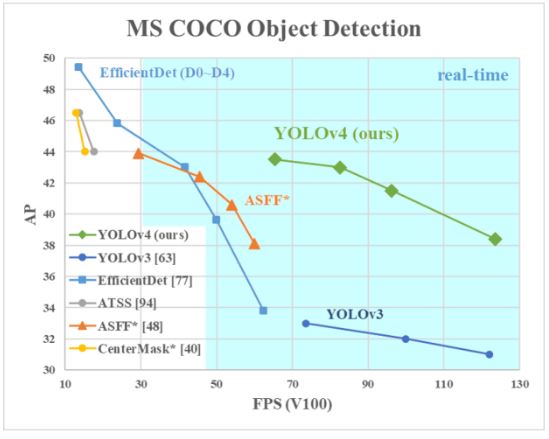
일반적으로 사용되는 Maxwell, Pascal 및 Volta 아키텍처의 GPU에서 YOLOv4와 다른 모델들을 비교한 그래프다. YOLOv4는 모든 조건의 속도와 정확도를 기반으로 가장 빠르고 정확한 탐지기로 판단할 수 있다. 또한 비싸고 많은 GPU가 아닌 8~16GB-VRAM을 갖춘 기존 GPU에서 학습하고 사용할 수 있음으로 많은 응용분야에서 광범위한 사용이 가능하다.
Reference
논문 링크 : https://arxiv.org/abs/2004.10934
'딥러닝 > Object Detection' 카테고리의 다른 글
| [Object Detection] DETR (0) | 2024.10.10 |
|---|---|
| [Object Detection] EfficientDet (2) | 2024.10.03 |
| [Object Detection] YOLOv3 (1) | 2024.09.28 |
| [Object Detection] RetinaNet (0) | 2024.09.26 |
| [Object Detection] YOLOv2 (YOLO9000) (3) | 2024.09.21 |