키워드
1. Transformer를 기반으로 한 객체 검출 모델. 복잡한 포스트 프로세싱 단계를 제거.
2. "End-to-End Object Detection with Transformers"
3. DETR, Transformer, Hungariang algorithm, Prediction Feed-Fowrard Network
DETR (DEtection TRansforemr)
이전의 detector는 수 많은 region 혹은 anchor에 대한 regression 및 classification 문제를 정의하여 간접적인 방식으로 예측을 했다. 이 과정에서 중복된 예측을 축소하는 후처리 단계, 앵커 세트중 유효한 앵커에 할당하는 heuristic한 기법에 의해 크게 영향을 받는다. 이에 사전에 정의된 지역을 사용하지 않고 직접적인 세트(set) 예측을 사용하면, NMS나 앵커와 같이 직접 설계한 많은 구성 요소의 필요성을 효과적으로 제거할 수 있다. 다만 dense한 네트워크에서는 cost가 매우 많이 필요하며, 이에 transformer를 활용한 직접 예측 접근 방식을 고안하였다.

DEtection TRansformer 또는 DETR이라고 하는 새로운 프레임워크의 주요 구성 요소는 bipartite(양방향) 매칭을 통해 고유한 예측을 강제하는 세트 기반 전역 손실과 transformer 인코더-디코더 아키텍처이다. 학습된 object query의 고정된 작은 세트가 주어지면 DETR은 객체의 관계와 전역 이미지 context를 추론하여 최종 예측 세트를 “병렬”로 “직접” 출력한다. 여기서 “병렬”은 출력을 하나씩 생성하는 기본적인 auto-regressive 모델과 달리, 한 번에 모든 예측을 출력하는 병렬 디코딩 방식을 결합한 transformer를 사용하여 구현되었다.
Transformer의 self-attention 메커니즘은 모든 요소간 상호 작용을 명시적으로 모델링하며, 이를 통해 중복 예측 제거, 동일한 클래스의 복수 객체 예측 등에 특히 적합하다. 또한 transformer는 모든 객체를 한 번에 예측하고, 예측된 객체와 실측 객체 간의 양방향 매칭을 수행하는 손실 함수를 통해 end-to-end 학습을 하여 학습 파이프라인을 간소화할 수 있다.
DETR은 대형 개체에서 훨씬 더 나은 성능을 보여 주는데, 이는 transformer의 non-local 계산의 영향이다. 그러나 작은 물체에서는 성능이 저하되며, FPN 과 같은 방식의 추가 모듈이 필요하다.
Architecture
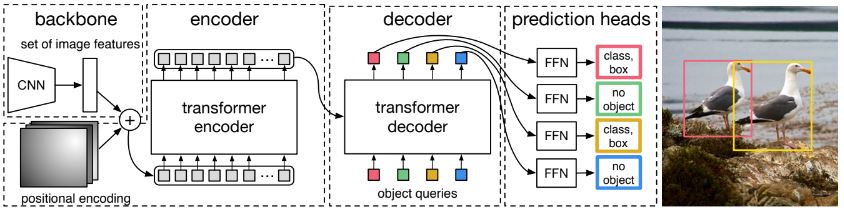
Backbone
Backbone 네트워크의 초기 입력은 H0 x W0 x 3 (RGB)의 이미지를 받는다. 해당 이미지를 통해 저해상도의 activation map을 생성하며, 그 크기는 H0/32 x W0/32 x 2048 이다. Backbone으로 다양한 classification 모델을 사용할 수 있으며, 성능 평가를 위해 ResNet 모델이 사용되었다. 그 중 ResNet 50과 ResNet-101 을 통해 구현 되었으며, 각각 DETR 및 DETR-R101 으로 지칭한다. 추가로 백본의 마지막 레이어에 dilation을 추가하고, 첫 번째 conv 레이어에서 stride를 제거하여 해상도를 높인 비교 모델도 있으며, 이는 DETR-DC5 및 DETR-DC5-R101 로 지칭한다. 해당 모델은 해상도를 2배 증가시켜 작은 개체의 성능을 향상시켰다.

Transformer encoder
우선 1x1 conv를 통해 최종 activation map의 채널 차원을 줄인다. 이를 통해 d×HW feature map을 얻으며 이를 입력으로 사용한다. 또한 transformer 아키텍처의 permutation-invariant한 특성을 고려해 “고정된” positional encoding이 입력에 추가되며, 각 인코더 레이어는 표준 아키텍처를 가지며 multi head Self-Attention 모듈과 FFN(Feed Forward Network)으로 구성된다.

인코더의 개수에 따라 모델의 성능 차이가 확인된다. 이를 통해 이미지 전역 추론에 있어, 인코더는 객체를 풀어내기 위해 중요하다고 가정할 수 있다. 아래는 마지막 인코더 레이어의 attention map을 시각화한 이미지다. 가정과 같이 인코더는 인스턴스를 분리한 것으로 보이며, 이를 통해 디코더의 객체 추출 및 localization을 수행할 가능성이 높다.

Transformer decoder
디코더 또한 인코더와 같이 transformer의 표준 아키텍처(multi head self-attention, encoder-decoder multi head attention, FFN)를 따른다. 원래 transformer와의 차이점은 표준 모델은 한 번에 한 요소씩 출력 시퀀스를 예측하는 auto-regressive 모델을 사용하는 반면, DETR은 디코더 레이어에 병렬로 N개의 객체를 배치하는 점이다.
디코더 역시 permutation-invariant이기 때문에, 서로 다른 결과를 생성하려면 입력 임베딩이 달라야 한다. 이러한 입력 임베딩을 object qurery 라고 부르며, 이는 네트워크가 참조하는 “학습된” positional encoding이다. 인코더와 유사하게 각 Attention 레이어의 입력에 추가한다. 이를 통해 object query는 디코더에 의해 N개의 출력 임베딩으로 변환되고 이후 FFN을 통해 상자 좌표와 클래스 레이블가 예측된다.

각 디코딩 단계 별로 예측된 객체를 평가하여 각 디코더 레이어의 중요성을 분석한 차트이다. 매 레이어마다 성능이 향상되며 첫 번째 레이어와 마지막 레이어 사이에 8.2/9.5 AP 수준으로 차이가 큰 것을 확인 할 수 있다. 또한 세트 기반 예측으로 NMS가 필요하지 않는 구조를 함께 검증하였다. 기본적인 NMS를 통해 첫 번째 디코더의 예측 성능을 향상되나, 이는 요소 간의 상호 상관을 아직 계산할 수 없으므로 동일한 개체에 대해 여러 예측을 하는 경향이 존재하기 때문이다. 이후 후속 레이어에서는 활성화에 대한 self-attention 메커니즘을 통해 모델이 중복 예측을 억제되는 경향을 확인 할 수 있다.

디코더 attention을 시각화한 이미지다. 디코더의 attention이 상당히 국소적이라는 것을 관찰할 수 있다. 주로 머리나 다리와 같은 물체의 말단(extremitiy)에 주의를 기울인다는 것을 의미한다. 이에 최종적으로 인코더가 전역 주의를 통해 인스턴스를 분리한 후, 디코더는 클래스 및 경계를 추출하기 위해 말단에만 주의를 기울인다고 가정할 수 있다.
Transformer 구조 별 영향성
Transformer 내부의 FFN은 1x1 conv 레이어로 볼 수 있다. 이 구조의 필요성을 판단하기 위해, FFN을 완전히 제거하여 평가를 진행했다. 이를 통해 41.3M의 파라미터가 10.8M로 크게 줄었지만, 성능이 2.3AP 감소하므로 FFN이 좋은 결과를 얻는 데 중요한 역할을 한다고 볼 수 있다.

그리고 DETR에는 기본적으로 spatial positional encodings과 output positional encodings(object query)의 두 인코딩 코딩이 포함된다. 두 인코딩을 고정된 인코딩과 학습된 인코딩의 조합으로 평가한 결과이다. 기본적으로 출력 위치 인코딩이 필수이기에 제거할 수 없으므로 디코더 입력에서 한 번만 전달하거나 모든 디코더 레이어의 쿼리에 추가하는 방법을 실험으로 나누어 평가하였다. 인코더에 spatial encoding을 전달하지 않으면 1.3AP 수준의 생각보다 작은 AP 하락만 발생했으나 최적의 조합은 spatial 에 고정, output에 학습된 encoding을 전달하는 방식이다.
이를 통해 transformer의 모든 구성 구성 요소(encoder, FFN, decoder, positional encoding)가 모델 성능에 기여한다고 판단할 수 있다.
Prediction feed-forward networks (FFN)
FFN은 ReLU activation과 d 차원의 hidden state를 갖춘 3 레이어 MLP와 linear layer로 구성된다. 각각 normalized 된 중심 좌표, 상자의 높이, 너비와 softmax를 통과한 클래스 점수를 계산한다. Object query의 크기 N은 일반적으로 예상되는 실제 개체의 수보다 훨씬 크므로 특수 클래스 레이블 ∅을 추가로 사용하며, 이는 "배경" 클래스와 유사한 역할을 한다.
Auxiliary decoding 손실
Auxiliary loss의 구현은, 훈련 중 각 디코더는 모델이 각 클래스 별 올바른 수의 객체를 출력하는 데 도움이 된다. 이는 각 디코더 레이어에 prediction FFN과 Hungarian 손실를 추가하여 구현되었으며 prediction FFN은 파라미터를 공유한다. 또한 다른 디코더 레이어에 추가적인 layer-norm을 통과시켜 prediction FFN에 대한 입력을 normalize 하였다.
손실 함수
손실 함수는 이미지에서 객체가 예측된 순서에 무관해야 한다. 이를 위한 일반적인 해결책은 GT와 예측간 bipartite 매칭을 찾기 위해 Hungarian algorithm 기반으로 손실을 설계하는 것이다. 이를 통해 permutation-invariant를 보장하고 각 요소가 고유하게 매칭되도록 한다.
객체는 디코더를 한 번만 통과하면 예측이 가능하며, N개의 고정된 개수의 집합을 추론한다. 여기서 N은 일반적인 개체 수보다 훨씬 더 크게 설정된다. 이 과정에서 GT와 예측된 개체(클래스, 위치, 크기)에 점수를 매기는 방식을, 최적의 bipartite 매칭을 생성한 다음 객체 별 손실을 최적화하는 순으로 구현하였다.
y는 GT, y_hat은 N개의 예측을 의미하며, N개를 맞추기 위해 GT 또한 부족한 만큼 ∅(객체 없음)을 추가한다. 이 두 세트 간의 bipartite 매칭을 찾기 위해 hungarian 알고리즘을 사용하여 최적 할당을 효율적으로 계산한다. 매칭을 위한 일치 비용(matching cost)은 클래스 예측과 예측 box와 GT box의 유사성을 모두 고려한다. y = (ci, bi)로 볼 수 있으며, ci는 클래스 정보, bi는 bounding box 정보를 담고있다. 이를 표현한 수식은 아래와 같다. 이렇게 매칭을 찾는 절차는 다른 모델에 사용되는 heuristic한 할당 규칙 혹은 anchor와 동일한 역할을 한다. 가장 큰 차이점은 중복 없이 직접적인 세트 예측을 위해 일대일 매칭을 찾아야 한다는 것이다.

이렇게 매칭된 쌍들에 대해 손실 함수를 계산해야 한다. 이는 일반적인 detector의 손실과 유사하게 손실을 정의한다. 즉, 예측에 대한 음의 log-likelihood와 bounding box loss의 조합으로 이루어진다. 여기서 클래스 불균형을 해결하기 위해 객체가 없는 ∅의 log-probability 항을 10 배 낮춘다. 이는 Faster R-CNN에서 subsampling을 통해 posi/nega의 균형을 맞추는 방법과 유사하다.

이후 bounding box에 대한 손실을 정의한다. 몇 가지 가정을 통해 예측을 수행하는 다른 detector와 달리 DETR은 직접적인 예측을 수행한다. 그리고 일반적으로 사용되는 L1 loss를 사용하면 큰 객체와 작은 객체가 상대적으로 비슷한 오류 수준이어도, 손실 기여하는 비중이 달라지게 된다. 이러한 문제를 완화하기 위해 L1 loss와 generalized IoU loss의 조합을 사용한다. 또한 IoU loss를 계산할 때, 일반적인 IoU 대신 soft 버전을 사용한다. B는 b와 b_hat을 담고 있는 가장 큰 box로, B를 이용한 추가 항을 사용함으로써 SGD를 통한 기울기가 훨씬 더 원활하게 전파되도록 도와준다.

최종적으로 모든 손실은 배치 내부의 개체 수로 normalization한다.

손실에는 classification loss, bounding box distance loss, GIOU loss 세 가지 구성 요소로 구성되어있다. 분류 손실은 훈련에 필수적이며 제외할 수 없으므로 bounding box distance loss가 없는 모델과 GIOU loss가 없는 모델을 훈련하고 baseline 과 비교한 결과이다. 이를 통해 GIOU loss가 대부분의 손실을 포함하는 것을 알 수 있다.
결과
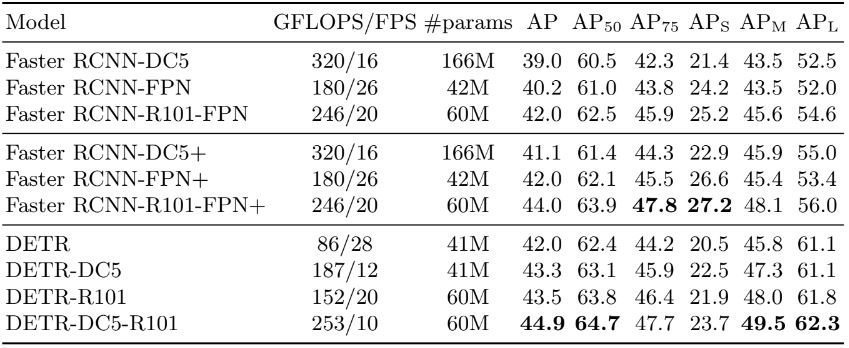
Baseline인 Faster R-CNN과의 비교 결과이다. 일부 "+" 표시가 있는 모델은 9배 추가 epoch을 훈련한 동일 모델이다. 파라미터 수의 비교를 위해 8개의 attention head가 있는 width 256의 encoder, decoder 6개를 갖춘 모델을 선택하였다. DETR은 동일한 수의 파라미터를 사용하여 42AP를 달성하여 Faster R-CNN과 동등 수준을 보였다. 다만 APs (작은 개체)에 대해서 성능이 떨어지며, APl (큰 개체)에 대해서 뛰어난 성능 차이를 보인다.

디코더의 각 출력 slot의 중심 좌표 분석 이미지다. 객체의 중심 좌표가 있는 지점을 scatter로 표시하였으며 녹색은 작은 상자, 빨간색은 큰 수평 상자, 파란색은 큰 수직 상자에 해당하도록 색상이 구분되어 있다. 이를 통해 각 slot이 각기 다른 모드로 통해 특정 영역과 상자 크기에 대해 전문화되는 방식으로 학습된 것을 알 수 있으며, 가운데 빨간 점들의 집합을 통해 모든 슬롯에 이미지 전체를 예측하는 모드도 함께 존재한다고 판단할 수 있다. 즉, 모든 slot이 specialize와 generalize가 골고루 학습되었다고 예상할 수 있다.

학습에 사용된 COCO 데이터셋에는 동일한 이미지에서 동일한 클래스가 많은 인스턴스로 잘 표현되어 있지 않다. 특히 13개 이상 포함된 이미지가 없으며, 많은 개체에 대한 일반화를 검증하기 위해 합성 이미지를 만들어 테스트하였다. 24마리의 기린을 합성한 이미지를 통해 DETR은 모든 객체를 찾았고, 이를 통해 object query의 각 slot 별로 클래스에 특화(class-specialization)되지 않았다고 판단할 수 있다.
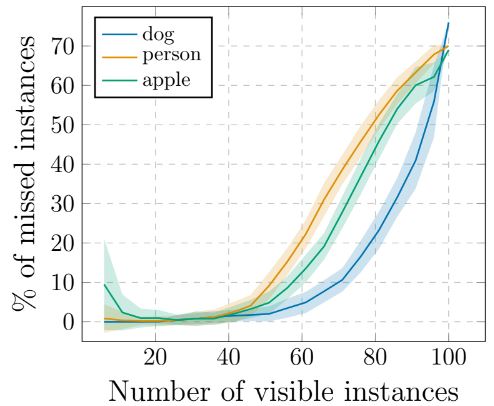
데이터셋과 무관하게 DETR은 설계상 query slot N(100)보다 더 많은 개체를 예측할 수 없다. 이 한계에 도달했을 때 DETR의 동작을 분석한 결과이다. 기린 합성이미지 처럼 100개의 개체가 있는 이미지를 만들고 일부 개체를 무작위로 마스킹하며 테스트를 진행하였다. 모델은 최대 50개까지 표시될 때 모든 인스턴스를 감지하지만, saturation되기 시작하며 이후 점점 더 많은 인스턴스를 놓치게 된다. 특히 이미지에 100개의 인스턴스가 모두 포함된 경우 모델은 평균 30개만 감지한다. 이는 이미지에 인스턴스가 50개만 포함된 경우보다 더 적은데, 이러한 현상은 훈련 분포와 거리가 멀기 때문에 발생한다고 예상된다.
Segmentation

Decoder 출력 위에 mask head를 추가하면 segmentation을 위한 모델로 자연스럽게 확장할 수 있다. Hungarian 매칭은 상자 사이의 거리를 사용하여 계산되므로 훈련이 가능하려면 box 정보가 필요하며, 각 box에 대한 바이너리 마스크를 예측하는 마스크 헤드를 추가한다. 이후 각 개체에 대한 transformer 디코더의 출력을 입력으로 사용하여 multi head를 계산하고 attention 점수를 생성한다. 이를 통해 최종 예측을 하고 해상도를 높이기 위해 FPN과 유사한 아키텍처가 사용된다. 마지막으로 각 픽셀의 마스크 점수에 대해 argmax를 사용하여 클래스를 결과 이미지에 할당한다. (Segmentation은 이후 기초 논문부터 리뷰 예정으로 메커니즘의 다소 오류가 있을 수 있다.)
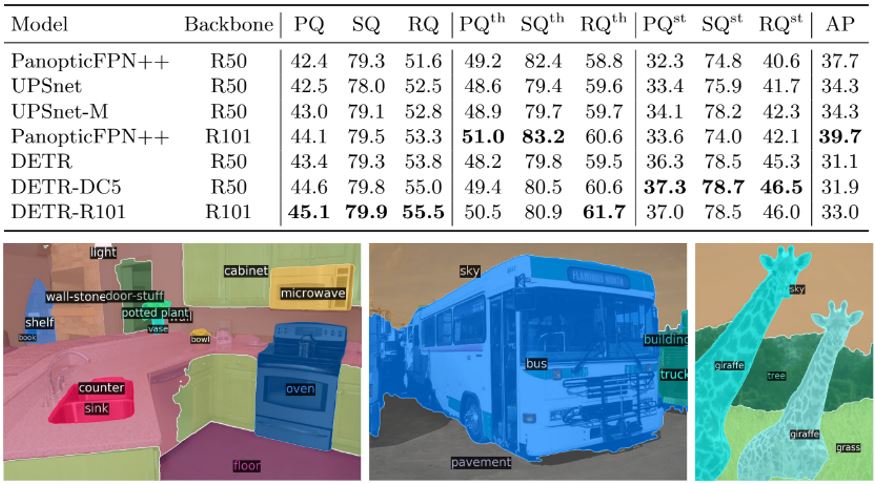
위 이미지와 같이 정성적 결과가 우수하며, PanopticFPN보다 우수한 정량적 결과도 얻었다. 또한 DETR이 특히 물건(stuff) 클래스에서 지배적이라는 것을 보여주며, 인코더 attention에 의해 전역 추론이 가능하여 이러한 결과를 얻었다고 예상된다. 다만 사물(things) 클래스의 경우 성능이 매우 부족한 것으로 판단된다.
Reference
논문 링크 : https://arxiv.org/abs/2005.12872
'딥러닝 > Object Detection' 카테고리의 다른 글
| [Object Detection] YOLOv4 (2) | 2024.10.05 |
|---|---|
| [Object Detection] EfficientDet (2) | 2024.10.03 |
| [Object Detection] YOLOv3 (1) | 2024.09.28 |
| [Object Detection] RetinaNet (0) | 2024.09.26 |
| [Object Detection] YOLOv2 (YOLO9000) (3) | 2024.09.21 |