키워드
1. YOLO의 정확도와 속도를 개선. COCO 데이터셋과 합성된 데이터를 사용하여 9000개의 객체 클래스를 인식.
2. "YOLO9000: Better, Faster, Stronger"
3. YOLOv2, YOLO9000, WordTree, Darknet
YOLOv2 (YOLO9000)
Object detection을 위한 데이터셋은 classificaion을 위한 데이터셋에 비해 상대적으로 제한적이다. Classification 데이터셋에는 수만 또는 수십만 개의 카테고리가 포함된 수백만 개의 이미지가 있으며 detection에도 classification 수준으로 확장 될 필요가 있다. 이를 이미 보유하고 있는 대량의 classification 데이터를 활용하여 detection 시스템의 범위를 확장하는 접근을 시도하였고, 언어 데이터베이스인 WordTree를 응용하여 서로 다른 데이터셋을 결합할 수 있는 방법을 개발했다.
이를 통해 9000개 이상의 클래스를 감지할 수 있는 YOLO9000을 소개한다. 기존 YOLO에서 확인된 여러 문제에 대해 다양한 개선 사항이 반영된 모델이며, 감지 및 분류를 한번에 학습하는 방법을 활용했다. 개선된 버전을 YOLOv2로 부른다. COCO 데이터셋과 ImageNet 데이터셋에서 YOLO9000을 동시에 학습했으며, 레이블이 지정된 detection 데이터가 없는 객체 클래스에 대해서도 detection이 가능해졌다.
YOLO는 상당한 수의 localization 오류를 유발했다. 또한 다른 region proposal 방식에 비해 recall이 상대적으로 낮았다. 이를 해결하기 위해 classification 성능은 유지하면 localization을 향상시키는데 초점이 맞춰져 있다. 또한 네트워크를 더 깊게 구성하거나, 앙상블을 활용하면 성능이 향상된다. 하지만 real-time 관점 속도의 큰 저하가 있으며, 네트워크를 단순화하면서 더 빠르게 학습시키고자 하였다.
더 정확하게

Batch normalization
BN은 다른 형태의 regularization에 대한 필요성을 제거하는 동시에 수렴 속도를 크게 향상시켰다. YOLOv2에도 BN을 추가함으로써 mAP가 2% 이상 향상되었으며, overfitting 이슈가 줄어들어 dropout을 제거하였다.
고해상도 classifier
SOTA를 달성한 모든 모델은 ImageNet에서 pre-trained classifier를 사용했다. 다만 대부분의 모델이 256 혹은 더 작은 입력 이미지를 사용했다. YOLOv2는 작은 객체의 detection을 위해 기존 YOLO의 해상도 224에서 해상도를 448로 2배로 늘렸고, 이에 ImagneNet에서 224 해상도로 먼저 pretrain 한 뒤에, 해상도를 높혀 fine-tuning을 진행하였다.
Anchor box
YOLO는 Conv로 추출된 feature map에 FC 레이어를 사용하여 bounding box의 좌표를 직접 예측한다. 다른 방식으로는 Faster R-CNN에서 RPN(Region Proposal Network)을 통해 conv 레이어만 사용하여 feature map의 모든 위치에서 앵커 박스로 오프셋과 신뢰도를 예측한다. Feature에서 좌표 직접 찾는 대신 주어진 상자를 기준으로 오프셋을 예측하면 문제가 단순화되고 네트워크가 학습하기가 더 쉬워진다.
이에 FC 레이어를 제거하고 앵커 상자를 사용하여 box를 예측하도록 변경하였다. 전체 conv 네트워크에서 416x416의 입력 이미지를 13x13의 feature map으로 down sampling 한다. 해당 feature map의 강 위치 별로 앵커 박스를 활용하여 탐지를 수행하게 된다. 앵커 박스가 없는 방식에 비해 정확도는 69.5 에서 69.2 mAP로 약간 감소하게 되지만, 81%에서 88%로 recall이 크게 상승한다.
Dimension cluster

앵커 박스를 사용할 때 일반적으로 박스의 크기를 직접 선택하게 된다. 이에 대해 가장 이상적인 박스의 크기를 설정하면 네트워크는 학습을 더욱 빠르고 효율적으로 진행하게 된다. 따라서 단순히 임의의 크기를 설정하는 것이 아닌, 훈련 세트에서 k-means clustering을 통해 자동으로 좋은 박스를 찾는다. 다만 단순히 유클리드 거리로 k-means를 사용하면 큰 상자가 작은 상자보다 더 많은 손실을 유도하는 현상이 있고, 상자 크기와 관계없이 IoU 점수로 거리를 측정하는 방식을 사용했다.

위 그래프와 같이 k = 5에서 모델 복잡성과 높은 재현율 사이의 좋은 균형을 보였다. 또한 직접 선택한 앵커 박스와 달리 짧고 넓은 상자보다 크고 얇은 상자는 더 많았다. 아래 표와 같이 이를 바탕으로 두 방식의 성능을 비교하면, k=5에서 k-means 방식이 성능이 우수하긴 하나 큰 차이를 보이지 않았지만, k가 늘어남에 따라 성능 차이가 증폭되었다. 즉, k-means 방식이 학습을 더 쉽게 배울 수 있음을 나타낸다.

좌표 예측 방식
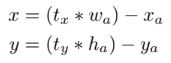
앵커 박스를 사용할 때 또 다른 문제는 모델의 불안정성으로 특히 초기 epoch 중에 발생한다. Region proposal 기반 네트워크에서는 네트워크가 tx, ty, 중심 좌표 (x,y)를 예측한다. 만약 tx가 1이면 앵커의 너비만큼 상자를 오른쪽으로 이동하고, -1이면 같은 거리만큼 왼쪽으로 이동한다. 다만 tx가 제한이 없으므로 상자를 예측한 위치에 관계없이 모든 앵커 상자가 이미지의 임의의 지점으로 이동이 가능하며, 랜덤 초기화를 사용하면 모델이 합리적인 오프셋을 예측하기 위해 안정화되는 데 오랜 시간이 걸린다.
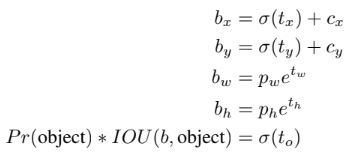
이에 최종적으로 오프셋을 예측하는 대신 기존 YOLO의 접근 방식처럼 셀의 위치를 기준으로 위치 좌표를 예측하는 방식이 사용되었다. 또한 그 크기를 sigmoid를 통해 0과 1 사이로 제한하였다. 네트워크는 feature map의 각 셀에서 5개의 bounding box 를 예측한다. 각 box에 대해 tx,ty,tw,th,to 5개의 좌표를 예측하며, cx,cy는 셀의 이미지 왼쪽 상단으로부터 좌표, pw, ph는 bounding box의 초기 너비,높이 와 같다. 이를 통해 위 식과 같이 예측을 한다. 이를 통해 위치 예측을 제한하기 때문에 학습이 더 쉬워 네트워크가 더욱 안정적이게 된다. 이미지는 상단 차원 축소의 첫번째를 참고하면 이해가 쉽다.
세분화된 feature
다른 네트워크는 여러 해상도의 feature map을 통해 다양한 크기의 객체를 인식하는 방식을 구현하였다. YOLOv2는 기본적으로 사용하는 13x13 feature map에 이전 레이어의 feature map을 가져오는 passthrough 레이어를 추가하여 동일한 기능을 구현하였다. Pass 레이어는 ResNet의 ID 매핑과 유사하게 고해상도 기능과 저해상도 기능을 연결하는 방식이나, 다른 채널로 stacking 하는 방식을 사용했다. 확장된 feature map을 통해 세분화된 feature에 액세스할 수 있게 되었다.
다중 해상도 훈련
입력 이미지 크기를 고정하는 대신 특정 epoch마다 해상도를 변경하여 학습하였다. 새로운 이미지 크기는 무작위로 선택되었으며, 모델이 32배만큼 다운샘플링하므로 {320, 352, ..., 608}의 32의 배수 중에서 선정한다. 이를 통해 네트워크가 다양한 입력 크기에 대해 잘 예측하는 방법을 배우도록 하며, 서로 다른 해상도에서도 detection을 수행 할 수 있도록 해준다.
또한 더 작은 크기에서 더 빠르게 실행되므로 YOLOv2는 속도와 정확성을 모두 향상시키는 효과도 유도할 수 있다.

더 빠르게

대부분의 detection 네트워크는 VGG-16을 base 네트워크로 사용한다. 다만 VGG-16은 강력하고 정확한 분류 네트워크이지만 불필요할 정도로 복잡하다. 이에 YOLOv2는 GoogLeNet 아키텍처를 참고하여 Darknet-19 네트워크를 사용했다. VGG 모델과 유사하게 주로 3x3 conv을 사용하며 pooling마다 필터와 채널 수를 두 배로 늘린다. 그리고 NIN 구조에 아이디어를 얻어 1x1 conv 를 3x3 conv 사이에 추가하여 feature를 압축하며, 이를 통해 훈련을 안정화하고 수렴 속도를 높혔다. Batch normalization 도 함께 사용되었으며, Darknet-19라고 불리는 최종 모델에는 19개의 conv 레이어와 5개의 max pooling 레이어로 이루어져있다.
앞서 설명했듯이 classification 을 위해 Darknet에서 224x224 해상도에서 pre-train을 진행한 후 더 큰 448x448 해상도에서 fine tuning을 한다. 이후 detection을 위해 네트워크를 수정하게 된다. 마지막 conv 레이어를 제거하고 3개의 3x3x1024와 1x1x(탐지 필요한 클래스 수)의 conv 레이어 조합을 추가한다. VOC의 경우 5개의 좌표와 20개의 클래스를 예측하는 5개의 상자가 있기 때문에 125개의 필터를 사용한다. 마지막 3개의 passthrough 레이어를 추가한다.
더 강력하게
Detection 데이터셋의 이미지를 사용하여 bounding box coord 예측, 객체성 및 classification하는 방법을 학습하며, 클래스 라벨만 있는 Classification 데이터셋을 사용하여 감지할 수 있는 카테고리 수를 확장하는 메커니즘을 활용하였다. 이를 위해 훈련 중에 각 데이터셋을 혼합하였으며, detection 샘플은 전체 YOLOv2 전체 손실 함수를 기반으로 역전파하고, classification 샘플은 아키텍처의 특정 classification 부분에서만 손실을 역전파하였다.
두 데이터셋의 차이는 detection 데이터셋은 "개" 또는 "보트"와 같은 일반적인 개체와 일반 레이블으로 구성되어있는 반면, ImageNet에는 "노퍽 테리어", "요크셔 테리어", "베들링턴 테리어" 등 세분화된 레이블로 구성되어있는 점이었다. 이러한 레이블을 병합하는 일관된 방법이 필요하였다.
일반적인 classification에 대한 가능한 모든 카테고리에 걸쳐 softmax 레이어를 사용하여 확률 분포를 계산한다. 이 접근법은 데이터셋을 결합하는 경우 “개”와 “개 품종”을 연관성이 없는 레이블로 간주하게 되는 것처럼 범용적인 모든 구조를 무시하게된다. 따라서 multi-label 모델을 사용하여 상호 배제를 가정하지 않고 데이터셋을 결합하는 방식을 사용했다.
Hierarchical classification
레이블의 개념을 구조화하고 개념이 어떻게 관련되는지를 설명하기 위해 언어 데이터베이스인 WordNet을 활용하였다. 다만 WordNet은 언어가 복잡하기 때문에 계층적인 트리가 아닌 방향성 그래프로 구성되어있다. 예를 들어 WordNet에서 "개"는 "송곳니"의 범주와 "가축 동물"의 범주에 둘 다 synset(정보 검색을 위해 의미적으로 동일한 것으로 간주되는 데이터 요소 그룹)에 해당한다. 이러한 방향성을 ImageNet에서 트리 구조로 문제를 단순화하였다.
트리를 구축할때 가능한 한 적게 성장시키는 경로를 추가했다. 즉, node에 대한 두 개의 경로가 있고 하나의 경로가 세 개의 branch를 추가하고 다른 경로는 하나의 branch만 추가하는 경우 더 짧은 경로를 선택하는 방식이다. 특정 synset이 주어지면 해당 synset의 각 하위 확률에 대해 조건부 확률을 예측하며, 특정 노드에 대한 절대 확률은 트리를 통해 루트 노드까지의 경로를 따라가며 조건부 확률을 곱하여 얻을 수 있다. 마지막 루트 노드는 “물리적 개체(physical object)”로 해당 확률은 Pr(물리적 개체)는 1이다.

이 접근 방식을 검증하기 위해 우리는 1000 클래스 ImageNet을 사용하여 구축된 WordTree에서 Darknet-19 모델을 훈련하였다. 또한 classifier의 크기를 1000에서 1369로 확장하였는데, 이는 특정 레이블("노퍽 테리어")의 조건부 확률을 계산하기 위해 상위 레이블("개" 및 "포유류") 등의 노드가 필요하였고, 상위 노드의 모든 synset에 대해 softmax를 계산하기 위해 총 1369개의 벡터를 사용하게 되었다. 이를 통해 새롭거나 알 수 없는 개체 범주에서는 성능이 저하되었으나, 어떤 종류의 개인지 확실하지 않은 경우에도 여전히 높은 신뢰도로 "개"를 예측하였고, “개”의 하위어들 사이에 신뢰도가 분산되는 현상을 확인했다.
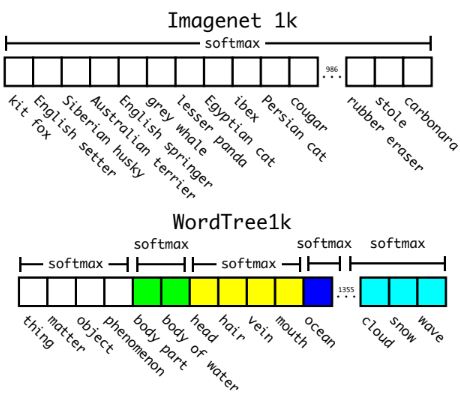
이 공식은 detection에도 효과적이다. Detector는 bounding box와 tree를 예측하게되는데, 어떤 임계값에 도달할 때까지 모든 분할에서 가장 높은 신뢰도 경로를 선택하여 트리를 아래로 탐색하고 해당 개체 클래스를 예측한다. 또한 WordNet은 매우 다양하므로 대부분의 데이터셋에 이 기술을 사용 가능하다.
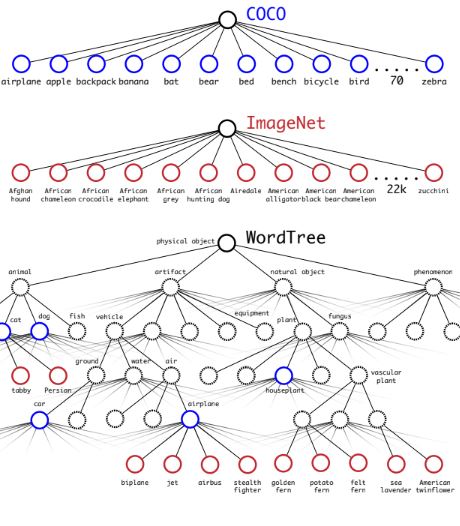
Joint classification and detection (YOLO9000)
COCO 데이터셋과 ImageNet 상위 9000개 클래스를 사용하여 결합된 데이터셋을 형성하였다. ImageNet은 훨씬 더 크기 때문에 COCO를 오버샘플링하여 ImageNet이 4:1이 되도록 균형을 맞추었다. 학습 중 레이블이 "개"인 경우 해당 정보가 없기 때문에 "저먼 셰퍼드" 대 "골든 리트리버" 트리의 아래쪽 예측에 오류를 할당하였고, 0.3 IOU 이상에서만 detection에 대한 학습을 진행하였다.

YOLO9000은 레이블이 지정된 detection 데이터를 본 적이 없는 156개 객체 클래스에서 16.0mAP의 성능을 보이며 9000개의 다른 개체 범주를 모두 실시간으로 동시에 감지하는 모습을 보였다. 다만 ImageNet classification task에서 새로운 동물 종을 잘 분류하지만 의복 및 장비와 같은 분류는 어려움을 보였는데, 이는 COCO에서 모든 동물로부터 detection 예측이 잘 일반화되어 있지만, 모든 유형의 의류에 대한 bounding box 라벨이 없고 “사람”으로 통일되어 있기 때문이다.

Reference
논문 링크 : https://arxiv.org/abs/1612.08242
'딥러닝 > Object Detection' 카테고리의 다른 글
| [Object Detection] YOLOv3 (1) | 2024.09.28 |
|---|---|
| [Object Detection] RetinaNet (0) | 2024.09.26 |
| [Object Detection] SSD (0) | 2024.09.19 |
| [Object Detection] YOLO (0) | 2024.09.14 |
| [Object detection] Faster R-CNN (0) | 2024.09.12 |