키워드
1. 전통적인 완전 연결 층을 제거하고, 전적으로 합성곱 신경망(CNN)만을 사용하여 픽셀 단위의 분할을 가능하게 함.
2. "Fully Convolutional Networks for Semantic Segmentation"
3. Fully Convolutional Network, Deconvolutional, skip architecture, patchwise training
Fully Convolutional Network

CNN은 image classification에서 object detection으로 발전이 이루어졌으며, detection과 같은 대략적인 추론에서 미세한 추론으로 자연스럽게 넘어가게된다. 이는 모든 픽셀에서 예측을 수행하는 것이며 이러한 접근 방식을 semantic segmentation 라고 한다. 이 또한 동일하게 ConvNet을 사용한다.
이를 구현한 방식은 "Fully Convolutional" 네트워크를 구축하는 것이다. 기존 classification 네트워크에 FCN을 구현하면 입력으로부터 dense한 출력을 계산할 수 있다. 추가로 정확하고 상세한 분할을 생성하기 위해 깊고 거친 레이어의 의미(semantic) 정보와 얕고 미세한 레이어의 모양(appearance) 정보를 결합하는 새로운 “skip” 아키텍처를 정의한다. 이를 통해 pixel-to-pixel, end-to-end 방식으로 학습과 추론 모두 전체 이미지에서 한 번에 수행 가능하다. 이러한 방식은 superpixels, proposal, 후처리 와 같은 복잡한 기능이 필요하지 않다. 단순히 classification task에서 pre-train하고, 이후 FCN에 대해 fine-tuning 하는 것만으로 dense 예측이 가능하다.
Upsampling
Shift-and-stitch
Input shifting과 output interlacing은 OverFeat에 의해 도입된 interpolation 없이 거친 출력에서 dense 예측을 생성하는 트릭이다. ConvNet으로 shift-and-stitch와 동일한 출력을 생성할 수 있다. s의 출력의 stride, f의 가중치를 갖는 레이어를 가정하자. 입력 stride를 1로 설정하면 출력이 s배 만큼 업샘플링된다. 이는 shift-and-stitch의 방식과 같지만, 기존 필터를 업샘플링된 출력과 convolution하면 동일한 결과가 생성되지 않는다. 그 이유는 기존 필터는 업샘플링된 입력의 일부 부분만 볼 수 있기 때문이다. 때문에 트릭을 재현하려면 필터를 아래와 같이 확대하여 희박화(rarefy)해야 한다. 즉, 비어있는 부분을 0으로 채운다는 의미이다. 이후 전체 출력을 재현하려면 모든 subsampling이 제거될 때까지 이 필터를 레이어 별로 반복해야 한다.

이를 개선하기 위해 단순히 네트워크 내에서 서브샘플링을 줄이는 것은 trade-off가 존재한다. 더 미세한 정보를 볼 수 있지만 receptive field가 더 작고 계산하는 데 더 오랜 시간이 걸리게 된다. Shift-and-Stitch 트릭은 이러한 trade-off의 적절한 절충안이다. 즉, 필터의 receptive field 크기를 줄이지 않고 출력이 더 dense하게 만들어지지만, 필터는 원래 설계보다 더 세부적인 정보를 활용하지 못한다..
Interpolation
거친 출력을 조밀한 픽셀에 연결하는 또 다른 방법은 interpolation이다. 예를 들어 간단한 이중선형 보간법은 각 출력을 셀의 가장 가까운 4개의 입력으로부터 데이터를 가져와 선형 맵을 통해 계산한다.
Deconvolution
어떤 의미에서 f가 적분된다면 deconvolution을 통한 업샘플링을 생각해볼 수 있다.다만 이러한 방식은 convolution을 반대로 수행하기 때문에 구현하기가 쉽지 않지 않다. 따라서 픽셀 단위 손실의 backprop하여 end-to-end 학습을 수행한다. 이러한 레이어의 deconvolution 필터는 고정 될 필요가 없고 학습할 수 있으며, activation 함수의 스택으로 구성된 비선형 업샘플링도 학습될 수 있습니다.이러한 업샘플링이 dense 예측을 학습하는데 가장 빠르고 효과적이다.
Architecture

일반적인 classification 모델은 고정된 크기의 입력을 받아 마지막 FC 레이어를 통해 공간 특성이 없는 출력을 생성한다. 그러나 이러한 FC 레이어는 전체 입력 영역을 포괄하는 kernel이 있는 convolution으로 볼 수도 있다. 이러한 변환을 통해 모든 크기의 입력을 받아들일 수 있고 classification 맵을 출력하는 fully convolution network로 캐스팅된다. 이러한 방식은 입력을 여러 patch 나누어 얻은 map과 동일한 결과이지만, 겹치는 영역에 대한 계산이 줄어들어 속도적인 측면에서 장점이 있다.
이에 따라 segmentation과 같이 밀도가 높은 문제에 활용할 수 있다. 또한 모든 출력에 Ground Truth가 있으므로 forward 및 backward 모두 간단하며 계산측면에서 효율적인 convolution의 장점도 활용할 수 있다. 하지만 classification 네트워크에서 필터를 작게 유지하고 계산량을 합리적으로 유지하기 위해 수행된 subsampling에 의해 출력이 거칠어진다. 이러한 거친 네트워크를 보완할 수 있는 구조가 추가적으로 필요하다.
Classifier to dense prediction
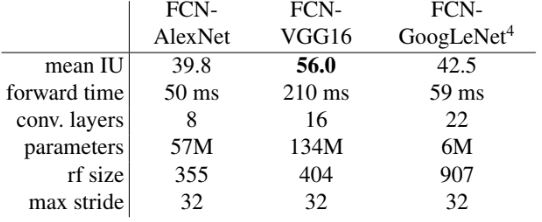
검증된 Classifier를 변형한 모델의 결과이다. 마지막 classifier 레이어를 제거하고 FC 레이어를 1 x 1 conv 레이어로 변경한다. 이후 PASCAL 데이터셋에 맞춰 1 x 1 conv 에 21 depth를 갖는 conv 레이어를 추가하고 업샘플링을 위한 deconvolution을 추가한다. 이렇게 새롭게 설계된 모델은 classification task에서 pre-train 한 뒤, fine-tuning을 통해 segmentation에 맞도록 학습한다. VGGNet이 SOTA 수준의 성능을 보였으며, GoogLeNet은 유사한 classification 정확도에도 불구하고 segmentation에서 결과는 차이를 보였다. 이후 앞서 언급했듯이 거친 특성을 보완하기 위한 추가 구조를 추가한다.
Skip architecture
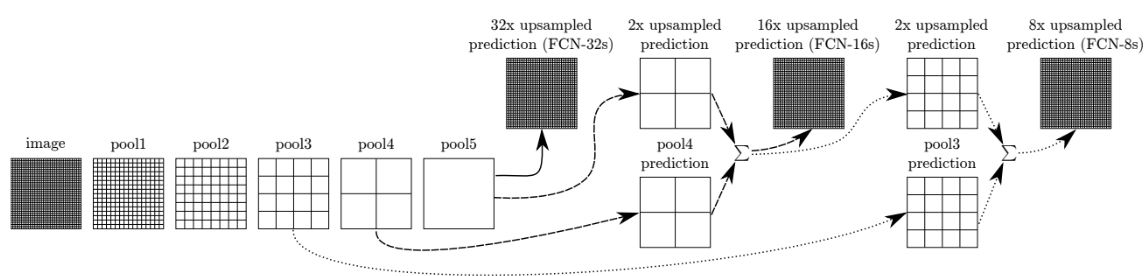
DAG(방향 비순환 그래프)의 형태로 레이어의 feature를 결합하고, 출력의 spatial precision을 개선하는 새로운 FCN 네트워크를 설계하였다. 이는 최종 예측 레이어에 하위 레이어와 결합하는 링크를 추가한 형태로, 미세한(fine) 레이어와 거친(coarse) 레이어를 결합하여 모델이 전체 구조를 고려하는 로컬 예측을 수행할 수 있도록 한다. 이러한 nonlinear local feature hierarchy 구조를 deep jet라고 부른다.

마지막 레이어만 미세 조정되는 FCN-32s-fixed을 제외하고 end-to-end로 학습한 결과이다. FCN-8에서 미세한 mean IU의 개선이 있으나 출력의 부드러움과 디테일이 개선된 것을 볼 수 있다. 다만 이후 추가적인 결합에서는 결과가 모두 감소하여 추가적인 레이어는 구현하지 않았다.
Patchwise training
FCN으로 구성된 손실 함수와 관련하여, 만약 손실이 공간에 대한 합인 경우 전체 기울기는 각 공간의 기울기에 대한 합이 된다. 따라서 전체 이미지에 대해 역전파 하는 것은, 최종 레이어 개별 receptive field를 미니 배치처럼 역전파 하는 것과 동일하다. 이에 receptive field가 상당히 겹치는 경우 feed-forward와 backprop에서 패치 별로 독립적으로 계산하는 것보다 전체 이미지에 대해 레이어별로 계산할 때 훨씬 더 효율적일 수 있다. 즉, 일부 receptive field 만 샘플링하여 나머지 patch의 기울기만 계산하는 patchwise 훈련보다, fully-convolutional 훈련이 속도가 더 빠르다.
또한 patchwise 학습의 샘플링을 통해 클래스 불균형을 수정하고 밀집된 패치의 공간적 상관성을 완화할 수 있다. 이러한 장점은 fully-convolutional 훈련에서도 loss에 가중치를 부여하고 loss sampling을 통해 동일하게 구현가능하다.

Patchwise 훈련에 대한 결과이다. 전체 이미지를 크고 겹쳐진 격자로 구성하고 1-p의 확률로 일부 패치를 제외한 후 학습하였다. 이러한 형태의 거부(rejection) 샘플링은 눈에 띄는 효과를 보이지 않았으며, 오히려 동일한 크기의 배치를 구성하기 위해 여러 이미지를 필요로 하며 시간이 더욱 오래걸리는 부효과를 확인하였다.
결과

FCN-8와 다른 모델을 비교한 결과이다. 최고의 성능은 물론 추론 시간 또한 매우 단축되었다. 정성적인 기준으로도 아래 이미지에서 미세 구조(첫 번째 행), 밀접한 개체를 분리(두 번째 행), occlusion에 대한 견고성(세 번째 행)을 확인 할 수 있다. 네 번째 행은 보트에 있는 구명조끼를 사람으로 간주 실패 사례이다.

Reference
논문 링크 : https://arxiv.org/abs/1411.4038
'딥러닝 > Segmentation' 카테고리의 다른 글
| [Segmentation] DeepLab (2) | 2024.10.31 |
|---|---|
| [Segmentation] PSPNet (0) | 2024.10.26 |
| [Segmentation] U-Net (0) | 2024.10.24 |
| [Segmentation] SegNet (0) | 2024.10.19 |
| [Segmentation] Segmentation 발전 과정 (1) | 2024.10.12 |