키워드
1. 다양한 스케일의 피라미드 풀링 모듈을 사용하여 전역 문맥 정보를 통합. 다양한 스케일에서의 정확한 분할.
2. "Pyramid Scene Parsing Network"
3. Pyramid Scene Parsing Network, Pyramid Pooling Module
Pyramid Scene Parsing Network (PSPNet)

Segmentation은 이미지의 context와 레이블의 다양성간 관련성을 분석하는 관점에서 어려움이 많다. 많은 모델이 fully convolutional network(FCN)을 기반으로 설계되었다. 이는 CNN 기반으로 dynamic하게 개체를 이해하지만 글로벌 장면 카테고리 단서를 활용하는 적절한 전략이 부족하다. 예를 들어 “강” 위에는 “자동차” 보다는 “배”가 있다는 context를 이해하는 능력이 부족하다는 것을 의미한다.
이전의 다른 모델은 크게 두 방향으로 진행되었다. 먼저 다중 scale feature 앙상블을 활용하였다. 이를 통해 깊은 레이어의 의미론(semantic) 정보와 얕은 레이어의 위치(location) 정보를 함께 활용할 수 있다. 다른 방향은 구조를 통한 개선이다. Conditional random field(CRF)를 사용하거나, end-to-end 방식으로 네트워크를 개선하는 것이다. 이러한 두 방향 모두 성능을 향상하였으나, 아직 개선할 수 있는 추가적인 여지는 존재한다.
이에 pyramid pooling 모듈을 통해 서로 다른 sub-region의 context의 결합하여 global context를 활용하는 PSPNet를 설계하였다. 이는 복잡한 장면의 이해를 도우며, 로컬 및 글로벌 단서를 함께 사용하여 최종 예측을 더욱 신뢰할 수 있게 만든다. 또한 손실을 최적화하는 보조 손실 전략을 활용하였다.
Fully convolutional network의 문제점

우선 FCN의 문제점을 살펴보자. Context는 특히 복잡한 장면 이해를 위해 매우 중요한 정보다. 여러 클래스들은 같은 이미지에 존재하는 패턴이 존재한다. 예를 들어 비행기는 도로 위가 아닌 동안 활주로에 있거나 하늘을 날 가능성이 높다. 하지만 FCN은 외관을 토대로 노란색 박스 안의 보트를 '자동차'로 예측(1행)하였다. 상황에 맞는 정보를 수집하는 능력이 부족하면 분류 능력이 떨어진다.
또한 데이터세트에는 경계가 모호한 클래스 라벨 쌍이 있다. 예를 들어 “지구”, “산”, “언덕” 그리고 “벽”, “집”, “건물” “마천루”. 이러한 클래스들은 외형이 크게 다르지 않다. 심지어 사람도 17.60%의 오류를 보인다. 모델 역시 “마천루” 그리고 “건물”을 별도의 객체로 예측(2행)한다. 이러한 결과는 카테고리 간의 관계를 활용하여 전체 개체가 하나가 되도록 제외해야 한다.
마지막으로 이미지에는 임의 크기의 객체/물건이 포함된다. FCN은 개별 receptive field에 영향을 받아 불연속적인 예측이 발생한다. 베개는 시트와 모양이 비슷하여, gloabl scene을 간과하면 베개를 분석하지 못할 수 있다. 이에 매우 작거나 큰 개체의 성능을 향상시키려면 눈에 띄지 않는(inconspicuous) 객체가 포함된 다양한 sub-region에도 많은 주의를 기울여야 한다.
Architecture
Pyramid Pooling Module
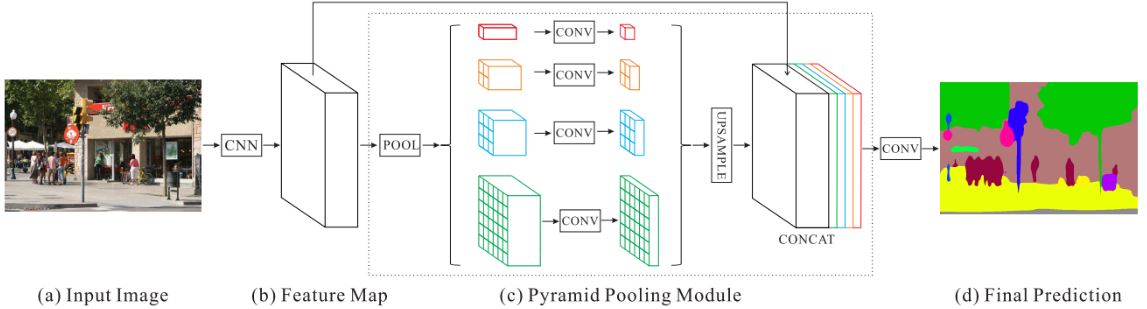
CNN에서 receptive field의 크기로 context 정보를 얼마나 많이 사용하는지 대략적으로 나타낼 수 있다. 다만 경험적으로 receptive field는 특히 상위 레이어에서 이론적인 receptive field보다 훨씬 작다. 이로 인해 많은 네트워크가 중요한 global scene을 충분히 통합하지 못한다.특히 이전 방식인 글로벌 avg pooling은 단일 벡터를 형성하면서 공간 관계가 손실되고 모호성이 발생한다.
Pyramid Pooling Module은 효과적인 global representation을 통해 문제를 해결했다. Receptive field를 융합하여 다양한 sub-region의 정보를 합쳤고 이를 통해 context 정보 손실을 최대한 줄였다. 이를 통해 다양한 정보를 포함하는 hierarchical한 구조를 설계하였고, 이 pyramid 구조는 네 가지 scale의 feature를 결합한다.
이렇게 다양한 크기의 feature map은 동일한 크기로 결합된다. 이를 위해 우선 차원을 줄이기 위해 1x1 conv 가 사용된다. 목표 채널 수가 N이라면, 1/N 수준으로 채널을 줄인다. 이후 업샘플링, 이중선형 보간을 통해 원하는 크기의 feature map을 구한 뒤, 한 번에 결합하게 된다. 이를 통해 다양한 sub-region을 추상화 할 수 있다.또한 초기 feature map도 함께 결합하여 최종 예측을 위한 feature map을 형성한다 이를 통해 기존 global pooling 보다 계산량은 크게 늘어나지 않으면서 다양한 정보를 수집할 수 있다.
Network
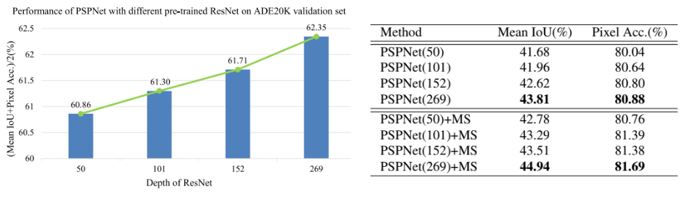
기본적으로 사전 훈련된 ResNet을 사용했다. 단순한 네트워크가 아닌 Dilated ResNet으로 feature map을 추출하였고 크기는 원본 이미지의 1/8 수준이다. 이후 pyramid pooling 모듈에 연결되어 최종 feature map을 구하며 conv 레이어를 통과하여 최종 예측을 수행한다. 추가로 ResNet을 통해 더 깊은 Neural Network의 성능이 크게 향상되었다. 이에 ResNet의 다양한 깊이에 대한 평가를 진행하였고, ResNet의 깊이를 50에서 269로 늘리면 “(mean IoU + Pixel ACC) / 2” 점수가 60.86에서 62.35로 향상된 것을 알 수 있다. 이를 통해 네트워크 깊이가 classification 뿐 아닌 segmentation 성능도 향상시킨다는 것을 알 수 있다.
Auxiliary loss

Deep ResNet는 skip connection을 통해 이전 레이어로부터 손실을 전달받아 학습한다. PSPNet은 이와 달리 추가 손실을 포함하는 supervision을 통해 추가 결과를 생성하고 최종 손실을 포함하여 나머지를 학습 방식으로 구현되었다. 이를 통해 최적화가 문제가 두 가지로 분해되며 각각은 해결하기가 더 간단하다.

다만 auxiliary loss는 주요한 손실이 아니기에 가중치를 통해 일정 비중으로 적용된다. 0과 1 사이의 일부 가중치를 평가한 결과이다. 가중치 0.4에서 최고의 성능을 발휘되며, 추가로 새로운 보조 손실을 통해 더 깊은 네트워크에서 더 좋은 성능을 얻을 것이라고 예상한다.
결과

우선 여러 PSPNet의 구조에 따른 결과이다. Baseline은 dilated ResNet50 기반 FCN이다. 'B1' 및 'B1236'은 pyramid pooling 모듈에서 사용된 feature map의 종류이며, 'MAX'와 'AVE'는 pooling 방식, 'DR'은 pooling 후에 차원 축소(dimension reduction)을 사용 했음을 의미한다. avg pooling 은 모든 조건에서 max pooling보다 더 잘 작동하며, 여러 feature map을 사용하는 것이 좋은 성능을 보인다는 것을 알 수 있다. 추가로 차원 축소를 통해 성능이 더욱 향상된다.
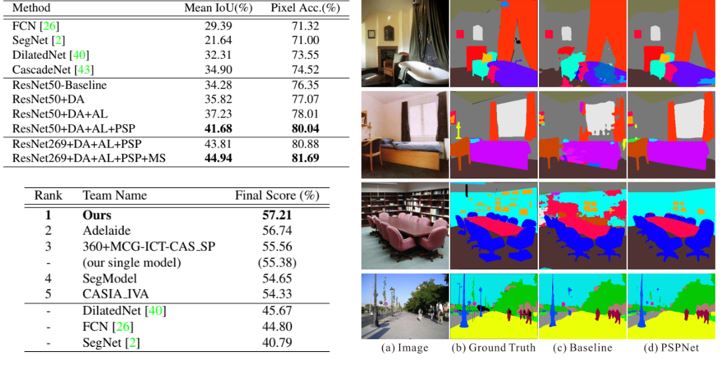
다른 모델과의 비교다. "ResNet269+DA+AL+PSP+MS"은 Data Augmentation(DA), Auxiliary Loss(AL), PSP, Multi-Scale(MS)의 조합이다. 단일 모델에서 55.38%의 최종 점수를 얻었으며, 이는 다른 모델의 앙상블보다 훨씬 높다.
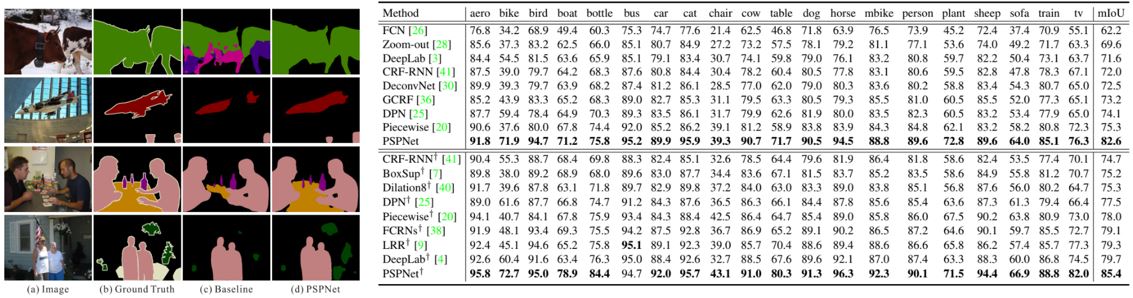
PASCAL VOC 데이터셋에서도 VOC 2012 데이터만으로 학습하먄 82.6%의 정확도, MS-COCO 데이터 세트로 사전 훈련되면 85.4% 정확도를 보였다. MS-COCO로 사전 훈련된 방법은 '†'로 표시되어 있다. 또한 20개 클래스 중 19개 클래스가 가장 높은 정확도를 보이며 뛰어난 성능을 보였다. 정성적으로 보아도 첫 번째 행의 "소"에 대해 baseline은 이를 "말"과 "개"로 처리하는 반면 PSPNet은 이러한 오류를 수정했다. "비행기"와 "테이블"에 대해 PSPNet은 누락된 영역을 더 정확히 예측 하였으며, "사람", "병" 및 "식물"등 이미지의 작은 크기 개체 클래스에서도 더 나은 성능을 보인다.
다만 PSPNet의 아키텍처가 아닌 ResNet의 적용으로 인해 성능이 향상되었다고 생각할 수 있다. 이는 동일하게 ResNet이 사용된 다른 모델(FCRN)보다 성능이 우수한 점을 통해 PSPNet의 영향을 설명할 수 있다.

Reference
논문 링크 : https://arxiv.org/abs/1612.01105
'딥러닝 > Segmentation' 카테고리의 다른 글
| [Segmentation] DeepLabv3 (1) | 2024.11.02 |
|---|---|
| [Segmentation] DeepLab (2) | 2024.10.31 |
| [Segmentation] U-Net (0) | 2024.10.24 |
| [Segmentation] SegNet (0) | 2024.10.19 |
| [Segmentation] FCN (0) | 2024.10.17 |