키워드
1. ASPP (Atrous Spatial Pyramid Pooling)를 사용하여 다중 스케일에서의 정보를 통합. 이전 DeepLab 모델을 개선.
2. "Rethinking Atrous Convolution for Semantic Image Segmentation"
3. DeepLabv3, atrous convolution, multi grid, ASPP
Semantic Segmentation 방법론
CNN을 segmentation에 적용하는 데 있어 두 가지 과제를 고려해야한다.

첫 번째는 pooling 혹은 stride로 인해 감소된 feature의 해상도로, 이를 통해 추상적인 특징을 학습할 수 있지만 상세한 공간 정보가 필요한 dense 예측 작업에는 방해가 된다. 이러한 문제를 극복하기 위해 atrous convolution을 사용한다. 이는 필터 가중치 사이에 간격을 삽입하는 것으로, 추가 파라미터를 학습할 필요 없이 CNN 내에서 feature response가 계산되는 해상도를 제어할 수 있다.

두 번째는 이미지에 다양한 크기의 물체가 존재한다는 것이다. 다양성을 고려하기 위한 기법에는 크게 4가지의 방법론이 존재한다.
- Image Pyramid : 동일한 이미지를 다양한 크기로 변경하여 입력으로 활용하는 것이다. 작은 크기의 입력은 장거리 context를 인코딩하고 큰 크기의 입력은 개체 세부 정보를 인코딩한다. 이러한 방식의 가장 큰 단점은 용량으로 인해 크고 깊은 모델에는 사용하기 어렵다는 점이다.
- Encoder-Decoder : 인코더 부분에서 multi-scale feature를 담도록 압축하고, 디코더 부분에서 이를 복구한다. 주로 deconvolution 레이어를 사용하여 저해상도 feature를 업샘플링한다. 대표적으로 SegNet, U-Net 등이 있다.
- Context module : 원래 네트워크 위에 추가 모듈을 활용하는 구조다. 이전 DeepLab의 CRF를 사용한 경우를 예시로 들 수 있다.
- Scene Pyramid Pooling : Feature map을 여러 filter 혹은 pooling을 통해 다양한 크기로 캡쳐하는 방식이다. PSPNet(Pyramid Scene Parsing Net) , LSTM을 기반으로 모델 등을 예시로 들 수 있다.
DeepLabv3
Context module과 Scene Pyramid Pooling을 기반으로, 필터의 시야를 효과적으로 확대할 수 있는 atrous convolution을 사용하였다. 구체적으로 다양한 rate와 batch normalization 레이어를 포함한 atrous convolution을 병렬로 배치하였다. 또한 rate가 극단적으로 커지는 경우 멀리 떨어진 정보를 캡쳐하지 못하여 3x3이 1x1 conv로 퇴화되는 문제가 있었다. 이를 image-level features를 도입하여 해결하였고, global context 인식 성능을 향상시켰다.
이러한 프레임워크는 모든 네트워크에 적용할 수 있다. 예시로 ResNet의 마지막 블록의 여러 복사본으로 복제한다. 이를 계단식(cascade)으로 정렬하고 여러 개의 atrous convolution이 병렬로 적용한다. 이를 ASPP 모듈이라 부른다.
Architecture
Atrous Convolution
Atrous convolution은 dense feature를 추출하는데 활용할 수 있다. “rate” r은 입력을 샘플링하는 보폭을 의미하며, 일반적인 convolution은 r이 1인 경우로 볼 수 있다. “rate”로 인해 생성된 빈 공간에는 0을 삽입하며, 입력을 atrous filter는 업샘플링 필터로 입력을 convolution 하는 것과 같다. 즉, rate를 변경하여 필터의 시야를 수정할 수 있으며, 이를 통해 response을 얼마나 dense하게 계산할지 명시적으로 제어할 수 있다.

"output_stride"는 초기 입력 이미지의 해상도와 최종 출력 해상도의 비율이다. (a) 이미지 classification 모델은 일반적으로 입력 이미지보다 256배 작아지며, 이 경우 output_stride는 256 이다. (b) 만약 dense 출력을 얻으려면, 먼저 특정 pooling 또는 conv 레이어의 stride의 다운샘플링 설정을 제거한다. 이후 해당 블록과 동일한 블록(예시에서는 block4)를 여러개 복제하고, 복제한 모든 conv 레이어를 atrous conv 레이어로 대체한다. 이를 통해 추가 파라미터를 학습할 필요 없이 더 dense한 feature를 추출한다 이 경우 output_stride는 16이 된다.

ResNet-50을 기반으로 각 output_stride에 따른 성능 차이 결과다. Atrous convolution이 전혀 없는 output_stride=256 에서는 성능이 매우 나쁘며, atrous convolution이 필수적이라고 판단할 수 있다. 다만 output_stride가 너무 작으면 메모리 문제가 있을 수 있기에, 적정 수준을 이용해야한다.
Multi Grid
기본적으로 block별로 서로 다른 rate를 사용하며, block4부터 block7까지의 rate 비율을 멀티 그리드라고 한다. 예를 들어 output_stride가 16이고 MultiGrid가 (1,2,4)이면, block4가 rate 2일때 나머지 세 개의 컨볼루션은 각각 2 * (1,2,4) = (2,4,8)의 rate를 가진다.

ResNet-50, ResNet-101에서 cascade 블록 수에 따른 성능 결과이다. 블록을 추가할수록 성능은 향상되지만 점점 포화되는 경향을 보인다. 또한 ResNet-50에 block7을 사용하면 성능이 약간 감소하지만, ResNet-101의 성능은 여전히 향상된다. 이를 바탕으로 ResNet-101에 다양한 MultiGrid를 테스트도 진행하였다. 단순히 두 배로 늘리는 것은 효과적이지 않으며, (1,2,1)에서 좋은 성능을 보인 것을 확인할 수 있다.
ASPP (Atrous Spatial Pyramid Pooling)
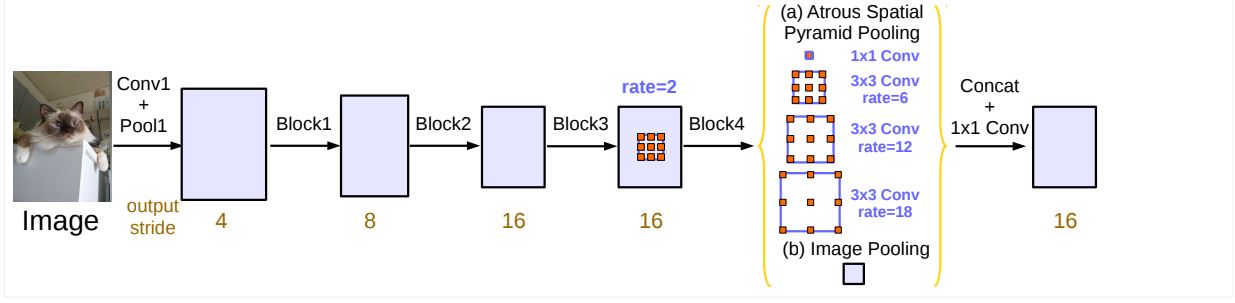
MultiGrid 이후 ASPP 모듈이 사용되며, 서로 다른 rate를 갖는 4개의 atrous convolution이 feature map에 적용된다. 이는 feature pyramid pooling에서 영감을 얻었으며, 이를 통해 feature에서 임의 크기의 영역을 정확하고 resampling한다. 여기에 추가되는 기능은 ASPP에선 batch normalization이 함께 사용된다.

그러나 rate가 커질수록 3×3 필터가 전체 이미지 context를 캡처하는 대신, 중앙 필터 가중치만 유효한 1×1 필터로 퇴화되는 것을 볼 수 있다. 이에 “image-level feature”를 활용하였다. 이는 모델의 마지막 feature map에 global average pooling을 적용하고, 이를 256개 필터가 있는 1×1 컨볼루션에 공급한다. 이후 원하는 해상도로 이중선형 보간을 통해 업샘플링한다.
최종적으로 ASPP는 (a) 하나의 1×1 컨볼루션과 rate = (6,12,18)을 사용하는 3개의 3×3 atrous conv 레이어와 (b) image-level feature로 구성된다. 이후 모든 분기가 concat되고 추가 1x1 conv를 통과한 뒤에, 최종 logit을 생성하는 1×1 conv 레이어로 결과를 출력한다.
학습의 관점에서 DeepLabv3에서는 이전 버전에 사용되었던 "폴리" 학습률 정책을 동일하게 사용하였다. 그리고 Groundtruth를 다운샘플링하면 미세한 주석이 제거되어 세부 정보가 역전파되지 않으므로, Groundtruth를 그대로 유지하고 대신 최종 로짓을 업샘플링하는 것이 중요하다.

ASPP 모듈과 “image-level feature”에 MultiGrid를 통합한 성능에 대한 결과다. MultiGrid에 대한 성능 평가를 진행한 경우와 달리 MultiGrid=(1,2,4) ASPP=(6,12,18)에서 가장 좋은 성능을 보였으며, “image-level feature”은 성능 향상에 도움을 주는 것을 알 수 있다.
결과

다른 모델과 비교하기 전 사용된 여러 기능에 대한 성능 비교 결과다. OS는 output_stride, MS는 테스트 중 multiscale 입력 사용. Flip은 좌우 반전 입력을 추가, COCO: MS-COCO에 대해 사전 훈련된 모델을 의미한다. 모든 기능들은 성능 향상에 기여하였다.

정성적 결과를 살펴보면 객체를 매우 잘 분할한 것을 알 수 있다. 이중 가장 아래 행은 일부 분할 실패 이미지로, (a) 소파와 의자, (b) 식탁과 의자, (c) 예상치 못한 형태의 사물에 대해 정확한 예측을 하지 못했다.

더욱 정확한 분할을 위해 bootstrapping 방법을 활용하였다. 하드 이미지에 대한 부트스트래핑에 의지하였으며, 훈련 세트에 하드 클래스(즉, 자전거, 의자, 테이블, 화분, 소파)가 포함된 이미지를 복제했다. 이러한 간단한 부트스트래핑 방법은 분할 성능을 향상시키는데 효과적이다.
Reference
논문 링크 : https://arxiv.org/abs/1706.05587
'딥러닝 > Segmentation' 카테고리의 다른 글
| [Segmentation] DeepLabv3+ (2) | 2024.11.07 |
|---|---|
| [Segmentation] Mask R-CNN (0) | 2024.11.07 |
| [Segmentation] DeepLab (2) | 2024.10.31 |
| [Segmentation] PSPNet (0) | 2024.10.26 |
| [Segmentation] U-Net (0) | 2024.10.24 |