
키워드
1. Faster R-CNN에 픽셀 단위 마스크 예측을 추가하여 인스턴스 세그멘테이션을 구현.
2. "Mask R-CNN"
3. Mask R-CNN, Instance Segmentation, RoIAlign
Instance Segmentation

Instance segmentation은 각 인스턴스를 정확하게 분할하는 동시에 이미지의 모든 개체를 올바르게 감지해야한다. 이미지에서 객체의 classification과 bounding box를 통한 localization은 물론, 각 픽셀 별로 semantic segmentation도 함께 병행되어야한다.
이를 수행했던 이전 모델들은 segment 후보를 제안하고 이후 Fast R-CNN으로 분류를 수행했다. 다만 이런 방법은 인식 속도가 느리고 정확도가 떨어진다. 개선된 방식으로 제안된 bounding box를 토대로 segment를 예측한 후, classification을 수행하는 복잡한 다단계 cascade가 사용되었다. Mask R-CNN은 이러한 방식을 기반으로, 각 단계가 병렬적으로 진행되는 더 간단하고 유연한 마스크 및 클래스 예측을 구현하였다..
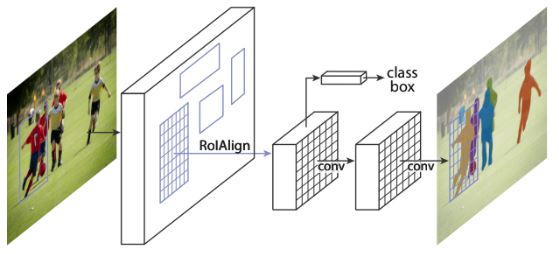
Mask R-CNN은 instance segmentation을 위해 Faster R-CNN에 기존 object detection 방식에 분기(branch)를 추가하여 확장한 모델이다. 이를 통해 이미지의 개체를 효율적으로 감지하는 동시에 각 인스턴스에 대해 고품질 분할 마스크를 생성할 수 있다. 또한 Mask R-CNN은 다른 작업으로 일반화하기도 쉽다.
마스크 분기는 각 RoI에 적용되는 작은 FCN으로, 픽셀 to 픽셀 방식으로 분할 마스크를 예측한다. 이러한 방식은 작은 계산량만 추가하므로 빠른 시스템과 신속한 실험이 가능하다. 이에 따라 정확한 RoI가 좋은 마스크 성능을 유도하게 되는데, Faster R-CNN은 양자화된 RoIPool 방식을 사용한다. 이를 해결하기 위해 RoIAlign 이라는 새로운 RoI 계산 알고리즘을 사용하였다.
또한 분할 마스크 예측에서 클래스 정보를 포함하는 방식은 성능 저하를 유발하였다. 이를 해결하기 위해 마스크 예측 시 해당 클래스가 아닌 다른 클래스의 정보는 아예 무시하는 방식으로 클래스 간 경쟁을 제거하였다. 이는 object detection과 segmentation의 역할을 분리하여 성능을 극대화 했다고 볼 수 있다.
Mask R-CNN
Mask R-CNN은 개념적으로 간단하다. Faster R-CNN에는 각 개체 후보에 대해 “클래스 레이블”과 “bounding box 오프셋”을 출력한다. 여기에 객체 마스크를 출력하는 세 번째 분기를 추가한 구조다. 이는 최근 대부분의 모델이 채택하고 있는 1-stage와 달리 2-stage 구조를 이룬다. 또한 Faster R-CNN 구조를 통해 상위 100개 detection box에서만 마스크를 계산하므로 Mask R-CNN은 Faster R-CNN 대비 20% 수준의 작은 연산량만 추가한다.
기반이 되는 Faster R-CNN의 출력은 짧은 벡터로 구성되어있다. 하지만 마스크 예측은 fully convolutional 레이어를 사용하여 픽셀 수준의 dense한 출력으로 구성되어 있으며, 이를 통해 픽셀 to 픽셀 매칭을 자연스럽게 처리한다. 구체적으로 object가 존재하는 각 RoI m x m 으로부터 m x m 마스크를 예측하여 공간 레이아웃을 유지하게 된다.
이러한 다른 segmentation 모델의 FCN 방식보다 더 적은 수의 파라미터를 필요로 하며, 동시에 더 좋은 정확도를 보인다. 하지만 픽셀 to 픽셀 대응을 명확하게 수행하기 위해선 매우 잘 정렬된 RoI 기능이 필요하다
RoIAlign
Faster R-CNN에서 사용된 RoIPool은 각 RoI에서 작은 feature map을 구하는 방식이다. 이는 각 RoI 먼저 양자화 한 뒤, 이후 여러 bin으로 세분화되어 box를 예측하는 방식이다. 다만 이러한 양자화는 RoI와 추출된 특징 사이에 잘못된 정렬을 초래하는데, 작은 misalign이 분류에는 영향을 미치지 않을 수 있지만 픽셀 단위의 마스크를 예측하는 데는 큰 악영향을 미친다.

이에 RoIAlign이라는 대안을 활용하였다. 이는 RoIPool의 양자화 방식을 사용하지 않고, 각 RoI bin의 샘플링된 4개의 위치에서 이중선형 보간법을 통해 정확한 값을 계산하고, max 혹은 avg로 값들을 집계한다. 위 이미지에서
점선은 feature map을 나타내고 실선은 RoI(2×2 bin으로 구성)를 나타내며, 점은 각 bin 별 4개 샘플링 지점을 의미한다. RoIAalign은 feature map에서 가까운 grid 포인트로부터 이중선형 보간을 통해 각 샘플링 포인트의 값을 계산한다.

여러 RoI 계산 방식에 대한 비교 결과다. RoIAlign은 RoIPool보다 성능이 뛰어나다는 것을 알 수 있으며, MAX/AVG 풀에 따른 차이는 없다. 또 다른 방식인 RoIWarp는 RoIPool과 같이 RoI를 양자화하는 방식으로, 입력과 여전히 misalign되는 RoI를 얻는다. 이에 RoIWarp는 RoIPool과 동등하고 RoIAlign보다 나쁜 것을 알 수 있다.
Architecture
여러 아키텍처로 Mask R-CNN을 인스턴스화 할 수 있으며, 크게 backbone과 head 영역으로 구분된다.
Backbone
Backbone은 ResNet과 ResNeXt의 레이어 깊이가 50, 101 인 아키텍처를 활용하였다. 또한 backbone의 feature를 효율적으로 활용하기 위해 FPN(Feature Pyramid Network)을 추가하였다. 이는 lateral connection이 있는 top-down 구조로, 단일 scale 입력에서 네트워크 내 feature pyramid를 구축하는 구조다. ResNet-FPN 백본을 사용하면 정확성과 속도 모두에서 뛰어난 결과를 보인다.
Head

Head는 2가지 방법으로 설계가 가능하다. 먼저 Faster R-CNN 박스에서 헤드를 확장하는 방식이다. 이는 ResNet의 5번째 블럭(res5)에 추가 분기를 추가하는 것으로 굉장히 계산 집약적이다. 다른 방법은 FPN의 출력을 이용해 추가 분기를 추가하는 것이다. FPN의 경우 res5가 포함되어 있으며, 더 적은 수의 필터를 사용하기 때문에 효율적인 head의 설계가 가능하다.
Nvidia Tesla M40 GPU에서 ResNet-101-FPN 모델은 이미지당 195ms로 실행되고, ResNet-101-C4는 400ms로 실행된다. 이는 C4 모델이 head가 더 무겁기 때문이며, 따라서 실제로는 C4 모델을 사용하지 않는 것이 유익할 수 있다.

각 Backbone과 Head의 조합에 대한 결과이다. 모든 프레임워크에서 더 심층적이거나 개선된 네트워크를 사용하는 것이 성능 측면에서 더 나은 결과를 보였다.
Loss function
각 RoI에 대한 손실은 L = Lcls + Lbox + Lmask 로 정의한다. Lcls와 Lbox는 Faster R-CNN과 동일하게 계산한다. Lmask는 픽셀 당 binary cross-entropy loss로 정의된다. 총 K개의 클래스와 m x m의 마스크가 있을때, 마스크 예측을 통해 m x m x K 의 출력이 생성된다. 각 픽셀은 시그모이드가 적용되며, 손실 계산시에는 GT 클래스 k에 해당하는 마스크의 예측만 활용한다.
이러한 방식은 FCN을 적용하는 다른 모델과 방식이 다르다. 일반적으로 semantic segmentation을 위해 softmax를 통한 multinomial cross-entropy를 사용한다. 이는 곧 GT 클래스 k 뿐만 아닌 모든 클래스의 경쟁을 통해 손실을 계산한다는 의미다. 하지만 Mask R-CNN은 시그모이드를 통한 다른 마스크 출력은 손실에 영향을 미치지 않는다. 즉, 클래스 간 경쟁 없이 모든 클래스에 대한 마스크를 생성한다.

이에 따른 sigmoid와 softmax 방식에 대한 비교 결과이다. 클래스에 대한 고려 없이 binary 마스크를 예측하는 것이 더 나은 성능을 보였으며, 이를 통해 모델을 더 쉽게 훈련할 수 있다. 또한 클래스의 구분 없이 mask를 예측하기 때문에 m x m x K 의 출력이 아닌, m x m x 1 의 출력도 고려해볼 수 있다. 실험 시 K의 출력은 30.3 AP, 1의 출력은 29.7 AP로 큰 수준의 차이를 보이지는 않았다. 이를 통해 분기를 통한 분업이 유효한 결과를 낸다는 점을 확인할 수 있다.
결과

우선 기존 Fast/Faster R-CNN의 하이퍼파라미터를 동일하게 설정하여 실험을 진행하였다. 이 수치들은 object detection을 위해 선정되었지만, 경험상 instance segmentation 시스템에서도 매우 뛰어난 성능을 보였다.

위 테이블은 Mask R-CNN과 다른 모델을 비교한 결과다. ResNet-101-FPN 백본을 갖춘 Mask R-CNN은 FCIS+++보다 성능이 뛰어나다. 정성적인 결과를 참고해도, Mask R-CNN이 FCIS+++와 달리 겹치는 인스턴스에 대해 정확하게 분할하고 있으며, instance segmentation의 근본적인 어려움을 겪고 있지 않음을 나타낸다.

인간의 자세를 추정하는 keypoint detection의 결과다. 키포인트의 위치를 원-핫 마스크로 모델링하고, Mask R-CNN를 통해 이를 예측하는 방식이다. 이를 통해 Mask R-CNN이 일반화가 잘 된다는 것을 알 수 있다.

Reference
논문 링크 : https://arxiv.org/abs/1703.06870
'딥러닝 > Segmentation' 카테고리의 다른 글
| [Segmentation] HRNet (0) | 2024.11.08 |
|---|---|
| [Segmentation] DeepLabv3+ (2) | 2024.11.07 |
| [Segmentation] DeepLabv3 (1) | 2024.11.02 |
| [Segmentation] DeepLab (2) | 2024.10.31 |
| [Segmentation] PSPNet (0) | 2024.10.26 |