
키워드
1. 네트워크 내에서 높은 해상도를 유지하여 더 정교한 세그멘테이션 결과를 제공.
2. "Deep High-Resolution Representation Learning for Visual Recognition"
3. HRNet, Parallel multi-resolution convolution, Multi-resolution fusion
HRNet

Segmentation을 위한 기존 모델들은 저해상도의 feature를 통한 고해상도의 표현을 복구하는 방식을 많이 채택하였다. 위 이미지와 같이 feature map의 크기를 점차적으로 줄이고, 고해상도에서 저해상도까지 convolution을 직렬로 연결하여 저해상도 feature를 추출했다. 고해상도의 복구에는 모델 별로 다양한 프로세스를 활용하였다.
특히 다양한 크기의 객체를 분할하기 위한 multi scale fusion과 관련된 기술이 많이 사용되었다. 이를 위해 FPN(Feature Pyramid Network)가 모델 안에 많이사용되었다. 그리고 DeepLabV3에서는 Atrous Spatial Pyramid Pooling으로 feature를 결합하였고, U-Net은 skip connection을 통해 다운샘플링 프로세스의 feature를 업샘플링 프로세스의 feature와 결합하였다.
HRNet(High-Resolution Network)은 이전 모델과 크게 다른 구조를 사용한다. 저해상도로 feature 크기를 줄이는 것이 아닌 전체 프로세스에서 고해상도 표현을 끝까지 유지한다. 또한 고해상도 convolution stream에서 시작하여 점차적으로 저해상도 convolution stream을 하나씩 추가하고 생성된 모든 다중 해상도 stream을 병렬로 연결하며, 각 stream의 정보를 반복적으로 교환하여 다중 해상도 결합을 수행한다. 이는 의미적(semantically)으로 강력할 뿐만 아니라 공간적(spatially)으로도 정확하다.
Architecture

기본적으로 원본 이미지는 stem에 입력되며 stride 2의 3x3 conv를 통과하여 해상도가 1/4로 줄어든다. 줄어든 이미지가 body에 활용되며, 위 그림에서는 stem에 대한 정보는 존재하지 않고 body에 대한 모식도이다.
Parallel multi-resolution convolution
처음에는 고해상도 convolution stream부터 시작하여 저해상도 stream을 하나씩 추가하여 새로운 단계를 형성한다. 이렇게 생성된 multi-resolution stream을 병렬로 구성된다. 새로 만들어지는 병렬 stream의 해상도는 이전 단계의 해상도보다 낮은 해상도로 구성된다.
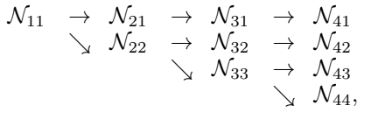
𝒩𝑠𝑟는 𝑠번째 단계의 하위 stream이고 𝑟는 해상도 지수이다. 첫 번째 stream의 해상도 지수는 1 이고, 𝑠번째 stream의 해상도는 첫 번째 stream 해상도에 1 / 2^(r-1) 을 곱한 값이다.
Parallel multi-resolution convolution은 group convolution 과 그 형태가 유사하다. Group convolution과 같이 입력 채널을 여러 하위 집합으로 나누고, 각 집합에 대해 개별적으로 convolution을 수행하는 방식이다. Parallel multi-resolution convolution 또한 입력이 여러 집합으로 나뉘어져 있다고 볼 수 있으며, group convolution 과 다른 점은 각 집합의 해상도가 동일하지 않고 서로 다르다는 점이다.
Structure
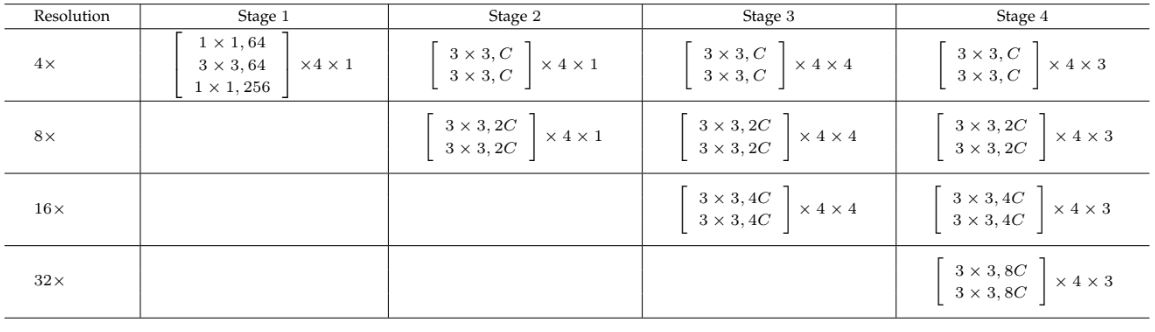
Body는 4개의 병렬 convolution stream이 있는 4개의 stage로 구성된다. 각 stream의 해상도는 1/4, 1/8, 1/16, 1/32이다. 가장 고해상도 stream의 첫 번째 stage는 각 unit이 채널 수가 64인 bottleneck 구조로 구성되며, 그 다음에는 채널 수가 𝐶인 3×3 convolution으로 구성된다. 다른 stream은 bottleneck 구조가 없으며 채널 수는 𝐶, 2𝐶, 4𝐶, 8𝐶이다.
1, 2, 3, 4단계에는 각각 1, 1, 4, 3개의 모듈화된 블록으로 구성되어있다. 각 모듈화된 블록은 4개의 residual unit으로 구성되어 있으며, 각 유닛에는 각 해상도에 대한 2개의 3×3 conv 레이어가 있다. 그리고 각 convolution 뒤에는 batch normalization과 ReLU가 뒤따른다.

각 해상도의 표현이 성능에 미치는 영향을 시각화한 결과다. Human pose estimate의 결과이며 총 4개의 response가 존재하나 가장 낮은 해상도는 점수가 너무 낮아 제외되었다. 이를 통해 고해상도의 정보가 키포인트 예측 성능에 큰 영향을 미친다는 것을 알 수 있다. W32, W48은 채널 수의 차이다.
기본적인 구조는 저해상도 stream은 점진적으로 추가되나 처음부터 4개의 모든 stream을 고려해볼 수 있다. 다만 성능이 오히려 낮게 확인되었는데, 이는 저해상도 stream의 초기 representation에는 유용한 정보가 매우 적기 때문이다.또 다른 간단한 변형으로는 저해상도 병렬 stream 없이 유사한 파라미터 수와 GFLOP를 가지는 단일 고해상도 stream을 고려해 볼 수 있지만, 이 또한 훨씬 낮은 성능을 보였다.
Multi-resolution Fusion

Fusion 모듈의 목표는 multi-resolution의 정보를 교환하는 것이다. 이는 4개의 residual unit 마다 반복된다. 예시로, r이 (1,2,3)인 세 개의 stream으로 구성된 fusion 모듈의 경우 서로 다른 해상도를 맞춰줘야 한다. 해상도를 감소시켜야하는 경우 stride가 2인 3×3 conv를 통해 다운샘플링을 하고, 해상도를 증가시켜야하는 경우 이중선형 보간을 통한 업샘플링과 채널 수를 맞추기 위한 1×1 conv를 통해 업샘플링을 수행한다. 또한 이 예시의 경우 r =4 인 추가 stream이 생성되며 이는 r = 1,2,3의 모든 정보를 활용한다.
일반적인 convolution의 multi-branch full-connection 형태와 유사하다. 이는 입력과 출력 채널을 각각 여러 하위 집합으로 나누고, 집합들은 완전 연결 방식으로 일반적인 convolution을 통해 연결된다. 즉, 각 출력 채널의 하위 집합은 convolution을 통과한 입력 채널의 모든 하위 집합의 합이다. Multi-resolution fusion의 다른 점은 해상도 변경을 처리해야 한다는 점이다.

반복되는 fusion의 효과를 분석한 결과다. (a)는 최종 출력을 위한 fusion을 제외한 모든 fusion을 제거한 방법이다. (b)는 stage 긴에만 fusion이 존재하는 경우, (c)는 stage 간, stage 내에 모두 fusion이 존재하는 경우다. 이를 통해 fusion이 많을 수록 더 나은 성능으로 연결되는 것을 알 수 있다.
이 외에도 또 다른 design choice가 존재하나 성능 개선에 기여하지 못한 아이템도 존재한다. 먼저 stride convolution을 이중선형 다운샘플로 대체하는 것이다. 이 아이템이 반영되지 못한 이유는 다운샘플링은 representatino의 볼륨 크기를 줄이는 방식인데, stride convolution이 bi-linear 방식보다 더 나은 볼륨 크기 감소 방법을 학습하기 때문이다. 다른 아이템은 곱셈 연산을 사용하여 합 연산을 대체하는 것이다. 이는 곱셈이 훈련 난이도를 증가시켜 오히려 모델 성능에 악영향을 끼친다.
Representation Head

세 가지 종류의 representation head가 있다. HRNetV1은 고해상도 convolution stream에서 계산된 고해상도 표현만 출력으로 사용한다. 이는 Human pose estimation에서 활용한다. HRNetV2는 모든 stream의 표현을 결합한다. 이중선형 업샘플링을 통해 저해상도의 크기를 조정하고 4개의 representation을 연결한 다음 1×1 컨볼루션을 수행하여 4개의 표현을 혼합한다. 이를 통해 semantic segmentation에 활용한다. HRNetV2의 고해상도 표현 출력에서 여러 수준으로 다운샘플링하여 HRNetV2p라는 multi-level 표현을 구성하고 이를 Faster R-CNN, Cascade R-CNN와 같은 프레임워크에 적용한다. 이를 통해 객체 검출을 향상시키고 특히 작은 물체에 대한 개선을 얻는다.

Head에 따른 각 모델의 비교 결과다. Human pose estimation의 성능은 비슷하나, segmentation과 detection은 HRNetV2가 HRNetV1보다 대체로 뛰어난 성능을 보인다. HRNetV1에 1x1 conv를 추가하여 고해상도 표현의 차원을 HRNetV2의 차원과 맞춘 HRNetV1h는 약간의 개선만 보인다. 이를 통해 HRNetV2의 저해상도 stream의 표현을 집계하는 것이 성능 개선에 필수적임을 의미한다.
결과
Human Pose Estimate

HRNetV1을 통한 정성적, 정량적 결과다. 이전 SOTA를 달성한 SimpleBaseline보다 HRNetV1-W32는 좋은 성능을 보였다. 특히 유사한 모델 크기, GFLOP를 갖는 backbone을 ResNet-50 사용하는 모델보다 3.0 포인트 수준의 성능 차이를 보였다. 이 외에도 pre-trained 모델을 사용하거나, 채널을 늘려 capacity를 증가시켜도 성능이 개선된다. 이를 통해 다른 기존 접근 방식보다 성능이 뛰어나며, 모델 크기와 계산 복잡성(GFLOP) 측면에서도 더욱 효율적이라는 사실을 알 수 있다.
Semantic Segmenatation

HRNetV2에 대한 여러 데이터셋에서의 결과이다.Cityscapes 데이터셋에서 HRNetV2-W48가 우수한 성능을 발휘하였으며, PASCAL-context 데이터셋은 59개 클래스와 60개 클래스(59개 클래스 + 배경)에 대한 mean IoU의 두 가지 종류가 있으며, 두 종류 모두 HRNetV2-W48가 여전히 뛰어난 성능을 보였다. 마지막 LIP 데이터셋 또한HRNetV2-W48의 더 적은 파라미터와 더 가벼운 계산량으로 최고의 성능을 발휘하였다.
Object Detection

HRNetV2p에 대한 결과다. 왼쪽은 앵커 기반의 object detection 프레임워크에서 평가한 결과이며, 오른쪽은 instance segmentation 기능까지 갖춘 프레임워크에서 평가한 결과이다. 비슷한 모델 크기와 복잡성을 갖춘 모델을 비교하면 HRNetV2p가 전반적으로 성능이 우수하다. 다만 learning schedule이 x1인 일부 경우에서 성능이 떨어지는데, 이는 학습 횟수가 부족했다고 판단할 수 있다. 즉, HRNet은 추가 학습을 통해 더욱 많은 성능 개선을 얻을 수 있다고 판단할 수 있다.

위에서 살펴본 세 가지 애플리케이션 모두에 대한 HRNet의 메모리 비용및 소요 시간 비교 자료다. Detection의 훈련 메모리 비용이 조금 더 크다는 점을 제외하면 대부분 이전과 비슷한 수준을 보인다. 또한 Segmentation 분야에서 HRnet의 추론 시간은 훨씬 짧다는 것을 알 수 있다.
Reference
논문 링크 : https://arxiv.org/abs/1908.07919
'딥러닝 > Segmentation' 카테고리의 다른 글
| [Segmentation] PointRend (0) | 2024.11.09 |
|---|---|
| [Segmentation] DeepLabv3+ (2) | 2024.11.07 |
| [Segmentation] Mask R-CNN (0) | 2024.11.07 |
| [Segmentation] DeepLabv3 (1) | 2024.11.02 |
| [Segmentation] DeepLab (2) | 2024.10.31 |