
키워드
1. 인코더-디코더 구조를 통해 경계 정보와 세부 사항을 보존. Atrous Separable Convolution을 사용하여 효율성 증가.
2. "Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation"
3. DeepLabv3+, encoder-decoder, astrous separable convolution,
DeepLabv3+

Semantic segmentation을 위해 feature pyramid pooling module 또는 encoder-decoder 구조가 많이 사용된다. 전자를 활용한 네트워크는 여러 receptive field를 가지는 필터 또는 pooling 작업을 사용하여 multi scale 정보를 인코딩하여 풍부한 상황 정보를 캡처한다. 후자를 활용한 네트워크는 공간 정보를 점진적으로 복구하여 더 선명한 객체 경계를 예측한다.
DeepLabv3+는 두 가지 방법의 장점을 결합한 구조를 사용하였다. 이는 ASPP를 통해 풍부한 상황 정보를 인코딩한 DeepLabv3에 디코더 모듈을 추가하여 객체 경계를 따라 분할 결과를 구체화한 방식이다. 또한 최근 classification에서 뛰어난 성능을 보인 Xception 모델을 활용하였으며, Xception의 주요 기능인 depthwise separable convolution과 atrous convolution을 혼합하여 더 빠르고 강력한 성능을 얻었다. Depthwise separable convolution은 유사한 성능을 유지하면서 계산량과 파라미터 수를 줄이는 기술이다.
기존 DeepLabv3의 서로 다른 rate의 여러 병렬 atrous convolution으로 이루어진 Atrous Spatial Pyramid Pooling 모듈은 마지막 feature map에 풍부한 의미 정보가 인코딩되어 있다. 하지만 backbone의 다운샘플링 작업으로 인해 객체 경계와 관련된 세부 정보가 누락되어 있었다. Segmentation을 위한 dense feature map 추출은 atrous convolution으로 어느 정도 가능하였으나, GPU 메모리로 인해 더욱 조밀한 밀도에는 한계가 있었고 이를 디코더 구조로 보완한 것이다. 또한 atrous convolution을 통해 가능한 리소스 수준에 따라 인코더 feature의 dense를 제어할 수 있다.
Architecture
Atrous Convolution
Atrous convolution이란 CNN에서 계산된 feature에서 multi scale 정보를 캡처하기 위해 명시적으로 해상도를 제어하고 필터의 시야를 조정할 수 있는 convolution 방법이다. “rate” r은 입력를 샘플링하는 간격이며, 일반적인 convolutiond은 𝑟=1인 경우로 볼 수 있다.
Depthwise separable convolution

Depthwise separable convolution은 일반적인 convolution을 depthwise convolution과 pointwise convolution으로 분해하여, 계산 복잡성을 대폭 줄인 convolution 방법이다. Depthwise convolution은 각 입력 채널에 대해 독립적으로 convolution을 수행하고, pointwise convolution은 depthwise convolution의 출력을 결합하는 데 사용된다. Atrous separable convolution도 이와 유사하게 동작하며 동일한 효과를 보인다.

Encoder
인코더는 기존 DeepLabv3가 사용된다. 마지막 한 블록의 stride를 제거하고 atrous convolution을 적용하여 dense한 feature를 추출한다. 이후 다양한 rate의 atrous convolution과 image-level feature으로 구성된 ASPP 모듈을 통해 최종 출력을 구한다. 이전 DeepLabv3는 이 출력을 업샘플링하여 최종 결과를 출력했다면, DeepLabv3+는 이 출력을 인코더의 출력으로 활용한다. 이에 따라 인코더를 통해 256개 채널과 풍부한 의미 정보가 포함된 출력을 얻는다. 또한 환경에 따라 atrous convolution을 조정하여 임의의 해상도로 특징을 추출할 수 있다.
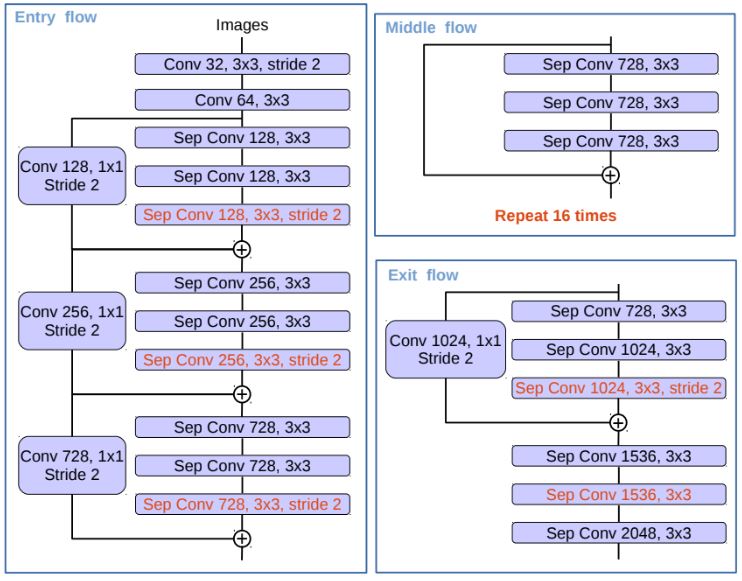
DeepLabv3는 ResNet을 기반으로 설계되었다. Xception은 ResNet대비 빠른 계산과 메모리 효율성을 바탕으로 뛰어난 성능을 보인다. 비교 결과는 바로 아래의 표이다. 이를 근거로 하여 DeepLabv3+는 Xception을 바탕으로 인코더를 설계하였다. Xception 대비 주요 변경은 모든 max pooling을 stride 2를 사용하는 atrous separable convolution으로 대체한 것이다. 또한 Batch normalization 및 ReLU activation을 MobileNet 설계와 유사하게 각 3×3 depthwise convolution 후에 추가한 것이다.

ResNet-101과 수정된 Xception의 ImageNet에서 classification 결과다. 이는 pre-trained 파라미터를 얻기 위한 모델이며, 동일한 훈련 protocol로 학습되었다. Xception의 성능이 더 뛰어나다는 것을 알 수 있다.
Decoder
DeepLabv3의 output_stride는 16으로 이는 입력 대비 출력의 해상도가 16배 줄었다는 것을 의미한다. 이 출력을 단순 이중선형 보간을 통해 업샘플링하여 분할을 예측한다. 하지만 이런 단순한 디코더 모듈은 세부 정보까지 성공적으로 복구하지 못할 수 있다.
이에 DeepLabv3+는 인코더(backbone)의 중간 feature를 활용한다. 먼저 인코더의 출력을 4배로 업샘플링한 다음, 인코더 중간의 동일한 해상도를 가진 feature를 결합한다. 이 과정에서 인코더의 feature는 채널이 많기 때문에 1 x 1 convolution을 통과한 뒤 결합된다. 그렇지 않으면 인코더의 출력보다 인코더 중간 feature의 중요성이 더 부각된다. 이후 3×3 convolution을 통과시킨 후, 4배의 업샘플링을 통해 최종 출력을 구한다. 이러한 구조의 디코더는 여러 design choice가 존재하며 아래와 같다.
- 인코더 중간 feature에 적용되는 1×1 conv의 채널 수.
- 결합 후 사용되는 3×3 conv 하이퍼파라미터.
- 인코더의 어떤 feature를 결합할지 선택하는 문제.

1 x1 conv의 채널을 48 또는 32 수준에서 뛰어난 성능을 보임을 알 수 있다.이에 적절한 채널 감소를 위해 [1×1,48]을 후속 평가에 사용했다. 또한 256개 채널의 3 x 3 conv 레이어 2개를 사용하는 것이 가장 효과적이었으며, 필터 수를 256에서 128로 줄이거나 kernel 크기를 3×3에서 1×1로 변경하면 성능이 저하되었다. 마지막으로 Conv2와 Conv3 feature map을 모두 활용한 모델을 평가했으며, 이는 U-Net/SegNet 설계와 유사하다. 이를 통해 유의미한 개선을 얻지 못했고, 이에 간단하면서도 효과적인 디코더 모듈을 활용하였다.
결과

ResNet-101과 Xception 각각 정확도와 속도 측면에서 모델 변형을 비교한 자료다. 기본적으로 Xception을 사용한 경우 동일한 모델 구조에서 더 좋은 성능을 보였다. 또한 두 backbone 모두 디코더를 추가함으로써 성능이 개선되었다. 그리고 더 작은 추론 output_stride를 사용하는 경우, 성능이 개선되지만 연상량이 매우 늘어나 환경에 따라 적절한 선택이 필요하다. 이 외에 MS는 multi scale, Flip은 테스트시 좌우 반전 이미지 추가 활용, SC는 depthwise separable convolution의 활용 여부, MS는 MS-COCO에서 사전 학습, JFT는 JFT-300M에서 사전 학습을 의미한다.
이 중 디코더를 사용하면 평가 시 output_stride를 8로 사용하는 효과가 줄어들며, depthwise separable convolution을 사용하는 경우(SC) Multiply-Adds 측면에서 계산 복잡성은 33%에서 41%로 크게 감소하는 동시에 유사한 mIOU 성능을 보이는 효과는 주목할만 하다.

DeepLabv3+는 JFT 데이터셋에서 사전 훈련 없이 87.8%을 달성했다. 정성적인 결과도 후처리 없이 객체를 매우 잘 분할한 것을 알 수 있다. 가장 마지막 줄은 예측에 실패한 모델인데 이는 DeepLabv3에서 실패한 경우와 여전히 비슷한 경우를 예측하지 못하는 것을 알 수 있다.

트라이맵 실험을 통해 분할 정확도를 평가하였다. 이는 객체 경계 근처에서 디코더 모듈의 정확도를 정량화하는 방식이다. 객체 경계 주변에 형태학적(morphological) 확장을 통해 'void' 라벨을 생성하고, 확장된 밴드(트라이맵) 내에 있는 픽셀에 대한 평균 IOU를 계산한다. Backbone에 상관없이 디코더를 사용하는 경우 성능이 향상되며, 확장된 밴드가 좁을 때 개선 효과가 더욱 두드러진다. 이미지는 디코더를 사용한 효과를 시각화한 것이다.
Reference
논문 링크 : https://arxiv.org/abs/1802.02611
'딥러닝 > Segmentation' 카테고리의 다른 글
| [Segmentation] PointRend (0) | 2024.11.09 |
|---|---|
| [Segmentation] HRNet (0) | 2024.11.08 |
| [Segmentation] Mask R-CNN (0) | 2024.11.07 |
| [Segmentation] DeepLabv3 (1) | 2024.11.02 |
| [Segmentation] DeepLab (2) | 2024.10.31 |