
키워드
1. Atrous Convolution을 도입하여 해상도를 유지하면서도 수용 영역을 확장. CRF를 사용하여 분할 결과를 정교화.
2. "DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs"
3. DeepLab, Atrous convolutional, ASPP, Fully connected CRF
DeepLab
CNN을 활용한 image classification 그리고 object detection은 끊임없이 발전하고 있으며, 이는 CNN의 invariant한 특성을 바탕으로 추상적인 데이터 표현을 학습 할 수 있기 때문이다. 하지만 semantic segmentation 분야와 같이 dense한 예측은 오히려 방해가 된다. DeepLab은 이러한 CNN의 부족한 부분을 보완하였으며, 뛰어난 속도, 정확성을 달성하였다.

CNN 모델의 활용에 있어 첫 번째 문제는 pooling 혹은 stride를 통해 해상도가 크게 감소된 feature를 얻게 된다는 것이다. 이전 모델들은 deconvolution 레이어를 통해 거친(coarse) 출력을 미세한(fine) 출력으로 복원하여 구체화하였다. DeepLab은 업샘플링된 필터를 사용한 컨볼루션, 즉 'atrous convolution'을 통해 dense 예측을 수행하였다. 이는 기존 업샘플링 필터에 구멍(프랑스어로 'trous')을 삽입하는 방식으로, 비어있는 영역은 이중선형 보간으로 채우게 된다. 이를 통해 파라미터나 계산량을 늘리지 않고 더 넓은 영역을 관찰하게 되어 효과적으로 시야를 확대할 수 있다. Atrous convolution는 dilated convolution라고 불린다
두 번째 문제는 다양한 크기의 사물을 인식하는 방식이다. 일반적인 방법은 다양한 크기로 조정된 동일한 이미지의 feature 또는 score map을 집계한다. 이러한 방식은 많은 계산 비용을 요구하며, 최근 모델들은 spatial pyramid pooling 방식으로 여러 feature 레이어를 리샘플링하여 효율적으로 처리한다. 이는 원본 단일 이미지를 여러 필터로 조사하는 것으로, DeepLab은 이를 기반으로 하여 atrous convolution을 사용하여 더욱 효율적으로 매핑을 한다. 이를 Atrous spatial pyramid pooling (ASPP)라고 한다.
마지막은 object centeric classifier의 transformation-invariant한 특성이다. 이는 분류에는 좋은 효과를 보이지만, localization 관점에서는 큰 단점으로 작용한다. DeepLab은 fully-connected CRF(Conditional Random Field)를 사용하여 fine detail까지 캡쳐하여 모델의 능력을 향상시켰다. CRF는 multi-way classifier를 통해 계산된 클래스 점수를 혼합하기 위해 segmentation에서 널리 사용되는 기법이다. 이를 CNN 기반 픽셀 수준의 classifier와 결합하면 매우 뛰어난 성능을 보인다.
다만 CNN과 CRF의 조합은 이전에도 종종 사용되던 방식이다. 하지만 기존에는 로컬로만 연결된 CRF가 주로 활용되었다. DeepLab의 fully connected CRF는 Gaussian CRF potential을 통해 long-range dependence를 활용하는 동시에 빠른 속도를 가능하게 하였다. 마지막으로 ResNet과 같은 더욱 뛰어난 CNN을 활용함아셔 성능을 더욱 끌어올렸다.
Architecture

Atrous Convolution
일반적인 CNN에서 최종 출력은 원본 이미지 대비 해상도가 크게 감소된다. 이전 모델은 deconvolutional 레이어를 통해 dense feature를 추출하였으나, 이는 추가 메모리와 시간이 필요하다. Atrous convolution은 dense feature 추출 및 시야 확대를 위해 최적화된 방식으로 단순한 해상도 향상을 넘어 더 큰 context의 통합을 가능하게 한다. 이를 통해 레이어에서 원하는 해상도의 응답을 계산할 수 있으며, 이후 학습에도 원활하게 통합된다. 하이퍼파라미터 “rate” r은 샘플링하는 간격(stride)를 의미한다.
Atrous convolution을 사용하면 “rate”를 통해 시야를 임의로 확대할 수도 있다. CNN은 일반적으로 3x3의 작은 conv kernel을 활용한다. 이 작은 kernel의 연속된 값 사이에 0을 삽입하여 크기를 효과적으로 확대할 수 있다. 이를 통해 계산량을 늘리지 않고 시야를 제어하는 효율적인 메커니즘을 구현할 수 있으며, 정확한 localization(작은 시야)과 context 이해(큰 시야) 간의 최상의 균형을 제공한다.

위 그림은 알고리즘의 간단한 2D 예시이다. 첫 번째 행은 해상도를 2배로 줄이는 다운샘플링 작업을 먼저 수행한 뒤, 이후 업샘플링을 통해 원본 이미지와 동일한 크기의 faeture를 얻었다. 이러한 방식은 원본 이미지 좌표 중 1/4에서만 응답을 얻을 수 있다.
대신, 원본 필터에서 rate를 2로 설정하고 빈 공간은 0으로 채운 ‘with hold’' 필터로 이미지를 convolution하면 모든 이미지 픽셀에서 응답을 계산할 수 있다. 0이 아닌 필터 값만 고려하면 되므로 파라미터 수와 위치당 작업 수는 모두 일정하게 유지되며, 이를 통해 해상도를 쉽고 명시적으로 제어할 수 있다.
다만 이 접근 방식을 네트워크 전체에 적용하면 원래 이미지 해상도에서 특징 응답을 계산할 수 있지만 결국 비용이 너무 많이 들게 된다. 이에 이중선형 보간을 사용하여 효율성/정확도 균형을 잘 맞추는 하이브리드 접근 방식을 채택하였다. 최종적으로 deconvolution 방식과 달리 추가 파라미터를 학습할 필요없이 dense feature를 추출하므로 실제로 더 빠른 CNN 교육이 가능하다.
Atrous Spatial Pyramid Pooling

ASPP는 rate가 다른 여러 atrous conv 레이어를 병렬로 배치한 구조다. 이를 통해 객체 규모를 명시적으로 설명하고, 크고 작은 객체를 모두 성공적으로 처리할 수 있게 된다. 초기 접근 방식은 표준적인 multiscale 처리 방식으로, 다양한 크기의 입력 이미지를 통해 atrous conv 레이어로 계산한다. 이후 원본 이미지 해상도로 매핑되어 결합된 뒤 클래스를 예측하는데 활용된다. 이는 성능을 크게 향상시키지만 모든 크기를 활용하기에 추가적인 연산 비용이 발생한다.
또다른 접근 방식은 R-CNN의 feature pyramid 방법에서 영감을 받아, feature를 resampling하여 임의 규모의 영역을 정확하고 효율적으로 분류하는 방식이다. 이를 응용하여 서로 다른 여러 개의 병렬 atrous conv 레이어를 사용하는 방식의 구현하였다. 각 샘플링 rate에 대해 추출된 데이터는 이후 결합되어 최종 결과를 생성한다.

다양한 ASPP 방식을 실험한 결과다. 기본적으로 ASPP는 fc6-fc7-fc8이 사용되며, 모두 3x3 커널이지만 다른 rate로 다양한 크기의 물체를 포착한다. LargeFOV 모델은 단일 분기가 있는 모델, ASPP-S은 4개의 branch와 더 작은 rate(r = {2, 4, 8, 12})를 활용한 모델, ASPP-L도 4개의 branch와 더 큰 rate(r = {6, 12, 18, 24})를 활용한 모델이다. CRF 이후 LargeFOV와 ASPP-S의 성능은 비슷하지만, ASPP-L은 CRF 전후 모두 성능이 개선되었다.
Fully connected CRF

CNN의 스코어 맵은 물체의 존재 여부와 대략적인 위치를 예측할 수 있지만 실제로 경계를 파악할 수는 없다. 이를 위해 CNN의 인식 능력과 fully connected CRF의 localization을 결합하였다. 다만 기존 CRF와 세부 사항은 다소 다르다. 전통적으로 CRF는 잡음이 있는 분할 맵을 매끄럽게 만드는 데 사용되었다. 이웃 노드를 결합하여 공간적으로 근접한 픽셀에 동일한 레이블 할당하는 방식으로, 이러한 단거리 CRF의 주요 기능은 hand-engineered feature을 기반으로 구축된 약한 classifier의 잘못된 예측을 보정하는데 활용된다.
하지만 CNN을 활용한 segmentation은 위 그림처럼 score map이 일반적으로 매우 매끄럽고 동질적인 결과를 생성한다. 이러한 결과에서는 단거리 CRF를 사용하는 것이 도움이 되지 않는다. 해결해야하는 문제는 상세한 로컬 구조를 더 매끄럽게 하기보다는 복구하는 것이다. 이를 위해서 fully connected CRF를 활용해야한다.

모델은 에너지 함수를 사용한다. x는 픽셀에 할당된 레이블을 의미하며, 단항(Unary) poteintal θi는 음의 log-probability로 P(xi)는 픽셀이 CNN을 통해 계산된 해당 레이블에 대한 확률이다. Pairwise potential은 완전 연결 그래프(Fully-Connected Graph)를 통해 모든 쌍의 픽셀 (i, j)를 연결하여 효율적인 추론이 가능하게 한다. 이에 대한 식은 다음과 같다.

μ(xi,xj)는 xi와 xj가 서로 다르면 1, 같으면 0으로 고유한 레이블이 있는 노드만 패널티를 받는다는 것을 의미한다. 나머지 표현식은 서로 다른 feature space의 두 개의 가우시안 커널을 사용한다. 첫 번째 '양방향' 커널은 두 픽셀 위치와 RGB 색상에 따라 달라지며, 유사한 색상과 위치를 가진 픽셀이 유사한 레이블을 갖도록 유도한다. 두 번째 커널은 픽셀 위치에 따라서만 달라지며, 공간적 근접성만 고려한다.
여러 변형 모델의 성능 비교

다른 모델과의 비교 전 다양한 필드를 사용하는 DeepLab의 여러 변형 모델에 대한 실험 결과이다. 첫 행은 VGG-16의 원본의 결과이다. 이와 비교하여 마지막 3x3 kernel 크기에 rate 12를 사용하는 DeepLab-CRF LargeFOV는 VGG-16 성능과 동등하나 더 빠르고 파라미터가 훨씬 적다. 또한 CRF는 모든 모델의 성능을 크게 향상시키며 평균 IOU가 3~5% 증가한다.
훈련
기본적으로 pretrain된 VGG-16 또는 ResNet-101 네트워크를 활용하였다. 이후 fine-tuning을 통해 segmentation에 활용하였으며, 훈련 시 모든 위치와 레이블은 전체 손실 함수에서 동일한 가중치가 적용되었다. 그리고 CRF 하이퍼파라미터를 설정할 땐, CNN의 레이블 관련 항은 고정되어 있다고 가정하고 설정하여 CNN 및 CRF 훈련 단계를 분리하였다.
Learning rate policy

학습률에 위 식을 추가적으로 곱한 "poly" learning rate 방식이 "step" learing rate보다 더 효과적임을 확인하였다. 또한 배치 크기를 고정하고 훈련 반복을 10K로 늘리면 성능이 향상되었다. 하지만 더 많은 훈련 반복으로 인해 총 훈련 시간이 늘어나기 때문에, 이를 보완하고자 배치 크기를 10으로 줄여 학습해본 결과 비슷한 성능이 여전히 유지되는 것이 확인되었다.
결과

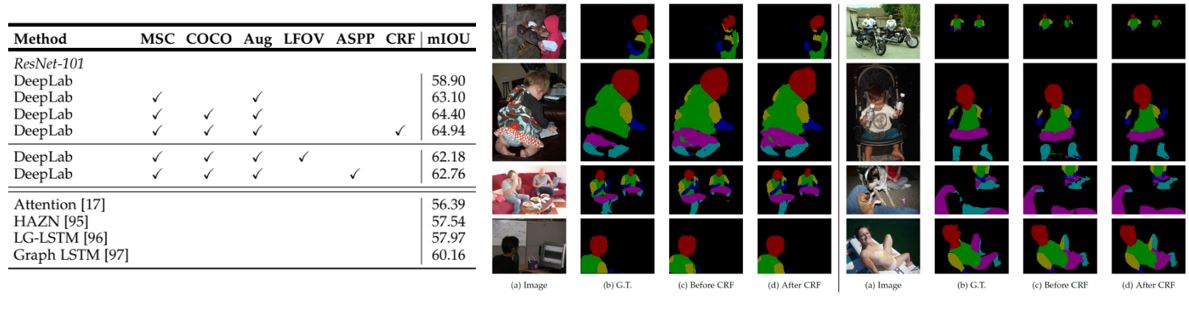
다른 모델과 비교하기 전 DeepLab에 적용된 여러 기술에 대한 성능 개선 결과다. MSC는 multi-scale 입력으로 동일 이미지를 여러 해상도로 추론하는 방식이다. COCO는 MS-COCO에 대해 사전 훈련된 파라미터이며, Aug는 학습 중 이미지의 크기를 무작위(0.5~1.5)로 조정한 augmentation의 활용 여부다. 이후 LargeFOV 및 ASPP에서 비교하였으며, 최종적으로 CRF로 후처리를 하였다.

PASCAL VOC 데이터셋에서 확인한 결과다. ResNet-101을 활용하여 최고의 성능을 달성하였다. CRF 이전부터 DeepLab에서 얻은 시각화 결과가 뛰어나다는 것을 알 수 있으며, CRF를 추가로 False Positive를 제거하고 객체 경계를 구체화하여 성능을 더욱 향상시켰다. 추가적으로 ResNet-101을 기반으로 한 DeepLab이 더 나은 결과를 제공한다는 것을 관찰할 수 있다. 시각화된 결과에서 볼 수 있듯이 VGG-16을 사용하는 것보다 객체 경계를 더욱 구체화하며, CRF 이전 ResNet-101이 거의 CRF 이후 VGG-16 수준의 객체 경계 정확도를 보였다.

이미지 전체에 라벨링이 되어있는 PASCAL-Context 데이터셋의 결과다. SOTA보다 더 나은 성능을 보였으며, CRF 이전의 DeepLab에서 이미 대부분의 객체/물체를 높은 정확도로 예측했다. CRF를 사용하여 고립된 FP를 추가로 제거하고 객체/물건 경계 예측이 향상되었다.


모델의 예측 실패 장면이다. 자전거 그리고 의자 등 물체의 섬세한 경계를 포착하지 못한 것을 볼 수 있다. Unary 항의 신뢰도가 충분하지 않기 때문에 CRF로 복구할 수도 없으며, 인코더-디코더 구조의 디코더 경로에서 고해상도 feature map을 활용하면 문제가 완화될 수 있을 거라 예상된다.
Reference
논문 링크 : https://arxiv.org/abs/1606.00915
'딥러닝 > Segmentation' 카테고리의 다른 글
| [Segmentation] Mask R-CNN (0) | 2024.11.07 |
|---|---|
| [Segmentation] DeepLabv3 (1) | 2024.11.02 |
| [Segmentation] PSPNet (0) | 2024.10.26 |
| [Segmentation] U-Net (0) | 2024.10.24 |
| [Segmentation] SegNet (0) | 2024.10.19 |