키워드
1. CNN 알고리즘의 시작이라고 볼 수 있으며, 손글씨 숫자를 효과적으로 분류함.
2. "GradientBased Learning Applied to Document Recognition" (1998)
3. Gradient-based learning, Backpropagation, Receptive field, Shared weights, sub sampling
LeNet
"Gradient-Based Learning Applied to Document Recognition" 이라는 논문 제목으로, 문서 인식을 위한 기울기 기반 학습을 소개했다. Backpropagation 알고리즘으로 학습된 다층 신경망이 그 중 가장 뛰어난 성능을 보인다는 것을 확인하였다.GTN (Graph Transformer Networks)라고 불리는 학습 패러다임으로 이를 구현하였으며. 특징을 직접 추출하는 경험적인(heuristics) 전통적인 방식과 달리 자동으로 학습하며 더 나은 성능을 보였다. 전통적인 방식은 쉽게 분리가 가능한 저 차원 공간에 한정되어 사용된다.

새로운 방식이 가능하게 된 이유는 첫째, 빠른 산술 장치를 갖춘 저렴한 기계의 가용성. 둘째, 대규모 데이터베이스의 가용성. 셋째, 고차원 데이터를 처리할 수 있는 기계 학습 기술의 가용성 때문이다.
데이터로부터의 학습 (Learning from Data)
"수치적(numerical)" 혹은 경사 기반 학습 방식을 통해 기계 학습이 이루어지며, 기계는 함수를 계산하게된다. 각 입력은 파라미터를 통해 출력이 계산되며, 최종적으로 계산된 출력은 인식된 클래스로 해석된다. 실제 라벨과 계산된 점수나 확률의 불일치를 손실 함수로 측정하며, 손실 함수의 평균이 최소화 되는 값을 찾는다. 가장 중요한 최종 지표는 훈련에 사용되지 않은 새로운 테스트 세트의 오류율이다. Regularization 함수 또한 손실 함수에 추가되며, 이는 파라미터 공간의 크기를 제한하며 trade off인 훈련 에러와 훈련-테스트 에러간 간격을 적절히 최적화한다.
경사 기반 학습 (Gradient-Based Learning)
이산 구조(discrete structure)보다 연속체 구조를 최소화하는 것이 쉬우며 이를 활용한 방식이다. 파라미터가 손실 함수에 미치는 영향을 추정하여 손실 함수를 최소화시키는 방향으로 파라미터를 수정한다.

On-line update 라고도 알려진 Stochastic gradient 알고리즘은, 근사화된 기울기를 사용하는 것으로 단일 샘플을 기반으로 업데이트된다. 이 과정을 통해 파라미터는 평균 궤적을 중심으로 변동을 보이지만, 결과적으론 빠르게 수렴이 가능하다.
기울기 역전파 (Gradient Back-propagation)
역전파의 기본 아이디어는 출력에서 입력으로의 전파를 통해 기울기를 효율적으로 계산할 수 있다는 것이다. 이전까지는 기울기를 사용하지 않고, 중간 레이어에 "가상 목표 (virtual targets)" 또는 교란 인수를 사용했다. 다만 local minima가 문제가 되지 않는 다는 것은 원인을 정확히 알 수 없다. 이는 네트워크가 작업에 비해 매우 큰 경우, "추가 차원"을 통해 local에 빠지는 위험이 줄어들 것으로 추측된다.
필기 인식 시스템
Convolutional Network라고 불리는 NN은 픽셀 이미지에서 특징을 학습하도록 설계되어 있다. 다만 개별 문자 인식이 아닌 단어 혹은 문장 인식에 있어서 어려움이 있다. HOS (Heuristic oversegmentation)를 통해 이를 수행 가능하며, 이는 휴리스틱 이미지 처리 기술을 사용하여 문자 간 잠재적인 컷을 다수 생성한 다음, 인식기가 각 후보 캐릭터에 대해 부여한 점수를 기반으로 최상의 컷 조합을 선택한다. 다만 HOS의 정확도가 NN의 성능에 영향을 미치며 잘못 분류된 글자를 구분해낼 수 없다. 이에 가장 좋은 방법은 학습을 위한 dataset에 사람이 직접 레이블을 지정하는 것이다.
전역 훈련 가능 시스템
이상적으로는 시스템의 모든 파라미터에 대해 전역손실 함수의 적절한 최소값을 찾고자 한다. 성능을 측정하는 손실 함수를 시스템의 조정 가능한 파라미터와 관련하여 미분 가능하게 만들 수 있다면 경사 기반 학습을 사용하여 최소값을 찾을 수 있다. 이에 전체 시스템은 미분 가능한 feed-forward 네트워크로 구축된다. 이를 통해 거의 모든 곳에서 연속이고 미분 가능하다.
이 경우 마지막 모듈을 제외한 모든 모듈의 출력은 외부에서 관찰 불가능하기 때문에 hidden-layer라고 불린다. NN은 고정된 크기의 벡터를 사용하고 모듈은 행렬 곱셈과 각 요소별 시그모이드 함수가 포함된 레이어로 구성된다. 복잡한 인식 시스템의 상태 정보는 숫자 정보가 첨부된 그래프로 가장 잘 표현된다. 또한 GT라고 하는 각 모듈은 하나 이상의 그래프를 입력으로 사용하고 그래프를 출력을 생성하며, 그렇기에 GTN이라고 명명한다.
문자 인식을 위한 CNN
네트워크 방식은 일정한 크기의 원본 이미지를 그대로 입력으로 활용 가능하다. 다만 Fully-connected layer의 경우 문제가 발생할 수 있다. 첫째, 일반적으로 이미지는 수백 개의 변수(픽셀)로 구성.있다 이에 단일 FC layer에만 수만개의 가중치가 포함되어, 시스템 용량을 증가 시킨다. 이를 학습하기 위해선 이에 비례하는 양의 학습 데이터가 필요하다. 둘째, FC layer는 입력의 토폴로지가 완전히 무시하게 된다. 이는, 이미지가 임의의 순서로 표시되어, 변수간 공간적 상관 관계를 반영하지 않는다는 뜻이다.
Convolutional Networks
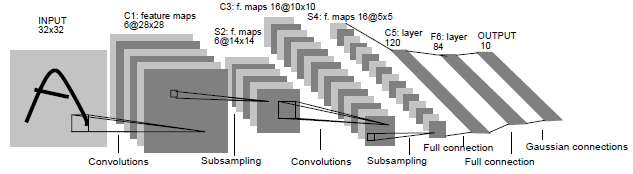
CNN은 "Receptive fields", ''shared weights", "spartial or temporal sub sampling"이라는 세가지 아이디어가 결합된다. LeNet-5에서 레이어의 각 유닛은 작은 유닛 영역으로 부터 입력을 받는다. (Receptive field) 이미지의 한 부분에 유용한 기본 특징 탐지기는 이미지 전체에 걸쳐 유용할 가능성이 높다. 이에 서로다른 receptive field에서 동일한 가중치 벡터로 강제한다. (shared weights) 한 가중치 벡터로 계산된 출력의 집합을 특징 맵 (feature map)이라고 하며, 레이어는 가중치 벡터별로 서로 다른 특징 맵으로 구성된다. Kernel은 사용되는 연결 가중치 집합이다. 이미지의 위치 정보가 학습되는 것을 방지하는 방법은 특징 맵의 해상도를 줄이는 것이다. Sub sampling을 통해 이동 혹은 왜곡으로 인한 출력 변화의 민감도를 낮춤으로서 구현 가능하다. (Spartial or temporal sub sampling) Convolution과 Sub sampling이 번갈아 가며 수행되면서 크기는 줄고 특징 맵의 수는 늘어나는 "bi-pyramid"를 생성한다. 역전파 과정에서 CNN은 자체적으로 특징 추출기를 학습한다고 볼 수 있으며, 가중치를 공유함으로써 FC보다 파라미터 수("용량")를 대폭 줄인다.
최종 출력 및 손실 함수

각 클래스마다 하나의 Euclidean Radial Basis Function(RBF) 유닛 집합으로 최종 출력이 구성된다. RBF는 입력 벡터와 파라미터 벡터 사이의 거리를 계산하며, 입력이 파라미터 벡터에서 멀어질 수록 RBF 출력이 커진다. 손실 함수는 입력이 주어지면 원하는 클래스에 해당하는 RBF와 파라미터 벡터에 최대한 가깝게 NN을 설계한다.

이러한 네트워크를 훈련하기 위한 가장 간단한 손실 함수는 MLE (Maximum Likelihood Estimation criterion)이다. 이는 MSE (Minimum Mean Squared Error)와 동일하다. RBF 파라미터 벡터가 만약 가변적이라면 모든 파라미터가 동일해지기 때문에 고정시킬 필요가 있다.

Result
Modified NIST set을 구성하여 학습 및 검증에 활용한다. 총 6만장 수준의 이미지로 구성되며. 입력의 크기는 32 x 32이다. 20번 반복을 통해 학습을 했고, 이 과정에서 learning rate를 감소 시켰다.

테스트 오류율은 훈련세트를 약 10회 통과한 후 0.95%로 안정화되었다. Overfit이 발생하면 훈련 오류는 시간이 지남에 따라 계속 감소하지만 테스트 오류는 최소값을 거쳐 특정 반복 횟수 후에 증가하기 시작한다. 다만 학습률이 상대적으로 크게 유지되어 해당 현상이 보이진 않는다. 즉, 가중치가 진동하게 되며, 평균은 더 낮게 유지되고 마치 regularization과 유사한 효과를 보인다.

Classifier 간 비교

Baseline로 지정한 Nearest Neighbor Classifier 의 오류율은 5%이며, k=3 인경우 2.4%의 오류을을 보인다. 여러 FC Layer로 구성된 네트워크와 LeNet(CNN)에서도 다양한 개수의 layer로 실험이 진행했으며, 가장 효과가 좋은 걸로 기록된 Boosted LeNet-4는 세 개의 LeNet-4가 결합된 형태. 0.7%의 오류율을 보인다. 비교한 여러 classifier들의 연산량 또한 성능대비 굉장히 적은 것으로 확인된다.

CNN은 또한 기하학적 왜곡과 관련된 불변성 또는 견고성 문제에 대한 부분적인 답을 제공한다. 2배 정도 의 스케일 변화, 문자 높이의 ± 절반 정도의 수직 이동 변화, ±30도 정도의 회전까지 정확한 인식이 이루어진다.

Multi-module systems 와 Graph Transformer Networks
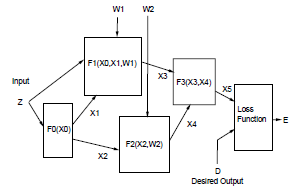
훈련 가능한 다중 모듈 시스템의 예시다. 각 모듈이 구현하는 기능과 모듈 간 상호 연결 그래프로 정의한다. 더 크고 복잡하지만 훈련가능 한 모델이 있어야 더욱 어려운 문제를 해결할 수 있다. 이러한 다중 모듈에서 입력을 그래프로 받고 출력또한 그래프로 내보내는 모듈을 Graph Transformer라고 한다.

입력 그래프의 수치 데이터와 함수 파라미터로부터 출력 그래프의 수치 데이터를 생성하는 미분 함수를 사용한다면 기울기 기반 학습을 적용할 수 있다.
Heuristic Over-Segmentation
대부분의 인식기는 한 번에 하나의 문자만 처리할 수 있으므로 먼저 문자열을 개별 문자 이미지로 분할해야한다. 그러나 자연스럽게 작성된 문자 시퀀스를 올바른 형식의 문자로 확실하게 분할하는 기술은 거의 불가능하다.
Segmentation Graph

고전적인 방법인 HOS의 아이디어는 경험적인 이미지 처리 기술을 사용하여 단어나 문자열의 후보 컷을 찾은 다음, 인식기를 사용하여 생성된 분할의 점수를 매기는 것이다. 분할이 생성되면 각강르 분할 그래프로 표현한다.
Recognition Transformer and Viterbi Transformer

GTN은 2개의 Graph Transfomer로 구성된다. Recognition Transformer는 모든 분할에 대해 가능한 모든 해석을 포함한다. Viterbi Transformer는 모든 해석 중 최상의 해석을 추출하며, Viterbi 페널티는 해석 그래프에 의해 정의된 순서와 동일하게 계산한다. 이 중 페널티가 가장 작은 경로를 Viterbi 경로라고 부른다. Viterbi 경로에 해당하는 구분자로 최종 문자 인식을 수행한다
Graph Transformer Networks
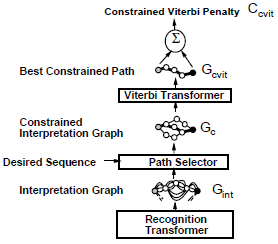
Segmentaion 를 통한 분할 없이 문자열 수준에서 시스템을 훈련하는 방법을 제안한다. 목표는 페널티가 가장 낮은 경로가 가능한 한 올바른 레이블 순서와 연결하는 것이다. Recognition과 Viterbi 사이에 Path selector가 삽입되며, Path selector는 모든 경로 중 일부의 올바른 경로만 필터링하는 역할을 한다. 나머지 요소들은 HOS와 유사하며, 이러한 형태는 치명적인 결함이 있다. 이는 인식기가 시그모이드 출력 단위를 갖는 단순한 NN인 경우, 인식기가 입력을 무시하고 출력을 모든 항목에 대해 작은 값을 갖는 상수 벡터로 설정할 때 손실 함수의 최소값이 달성하는 것이다. 이는 RBF 파라미터로 어느 정도 해결이 가능하나 완벽하게 방지하지는 못한다.
Discriminative Viterbi Training
기존의 올바른 해석의 페널티를 최소화할 뿐만 아니라, 위험할 정도로 낮은 페널티가 있는 잘못된 경로에 대해 페널티를 어떻게든 높이는 것이 방향으로 재구성하였다. Path selector로 제한된 경로의 페널티와 Recognition graph의 비터비 경로의 페널티 간의 차이를 손실 함수로 사용한다. 이 손실 함수는 인식기가 잘못 인식된 객체의 페널티를 증가시키도록 하기 때문에 결함을 방지한다. 다만 클래스 사이에 마진이 없어, 제한된 Viterbi 경로의 페널티가 전체 Viterbi 경로의 페널티와 같아지면 기울기는 0이 된다. 이는 잘못된 경로가 좋은 경로와 가까울때 발생할 수 있다.

Space Displacement Neural Network (SDNN)
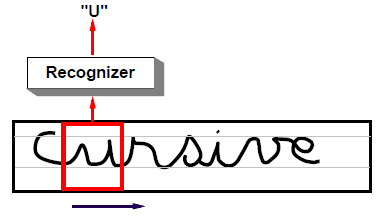
가능한 모든 위치를 스윕하며 글자를 인식하는 전통적인 접근은 비용이 굉장히 비싼 문제가 있다. 또한 인식기가 문자의 중심에 있을 때 옆의 다른 문자가 인식기의 시야에 나타나 인식을 방해할 수 있다. 문자열 내의 개별 문자는 크기와 기준선 위치가 매우 다양할 수 있어 인식기는 변화와 크기 변화에 매우 강력해야한다. SDNN은 CNN 구조를 통해 이러한 문제를 해결하고자 한다.

두 개의 입력 그래프가 있는 새로운 유형의 GT를 사용하여 구현된다. 첫번째 입력은 SDNN에 의해 생성된 벡터로 여러 호가 있는 선형 그래프이며, 두번째 입력은 클래스 레이블 별 입력과 출력간의 관계를 인코딩한 문법 변환기이다. 새로운 GT는모든 경로에 해당하는 모든 시퀀스를 가져와 문법 변환기와 매칭. 각 레이블의 출력을포함하는 그래프를 생성한다.

SDNN은 Classification 만이 아닌 Object Detection에 사용될 수 있음을 시사한다. 이미지 내에서 감지할 객체의 크기를 알 수 없기 때문에 이미지는 여러 해상도로 네트워크에 표시되며 각 해상도의 결과가 결합되어 활용된다.
추가 활용 방안
필기체와 같은 정형화되지 않은 글씨도 적절한 전처리와 함께 인식할 수 있다. 예를 들어 수많은 수표에 기재된 금액을 자동으로 읽는 시스템, 더 나아가 음성 인식 분야도 Graph composition 알고리즘을 통한 변환기(Transduction)으로 구현 가능하다.
결론
특징 추출은 전통적으로 고정된 변환이며 일반적으로 전문가의 사전 지식에서 파생되었다. CNN에 그래디언트 기반 학습을 적용하면 예제에서부터 적절한특징을 학습할 수 있다. 대규모 시스템에서 학습을 위한 일반적인 구성 원리로서 기울기 기반 최소화 방법의 유용성과 관련성을 확립하였고, SDNN 접근 방식은 CNN의 견고성과 효율성을 활용할 수 있다.
Reference
논문 링크 : http://vision.stanford.edu/cs598_spring07/papers/Lecun98.pdf
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] GoogLeNet (0) | 2024.07.25 |
|---|---|
| [Classification] VGGNet (2) | 2024.07.20 |
| [Classification] ZFNet (1) | 2024.07.18 |
| [Classification] AlexNet (0) | 2024.07.13 |
| [Classification] Classification 발전 과정 (0) | 2024.07.06 |