키워드
- 작은 필터 크기를 사용하여 매우 깊은 네트워크를 설계함으로써 성능을 개선.
- "Very Deep Convolutional Networks for Large-Scale Image Recognition" (2014)
- 3x3 filter, scale jittering
VGGNet
VGGNet을 통해 classification에서 convolutional network의 깊이가 정확도에 미치는 영향을 검증하였다. 매우 작은 3×3 convolution filter를 사용하는 아키텍처이며, 기존 여러 모델 대비 하이퍼파리미터를 수정하고 더 많은 레이어을 추가하여 네트워크의 깊이를 꾸준히 증가시켰다. 이렇게 깊이를 16 ~19 레이어 까지 깊게 구성하여 대한 상당한 개선을 달성하였으며, 상대적으로 단순한 파이프라인을 가지고 있다.
Architecture

224 × 224 RGB 이미지를 입력으로 사용한다. Raw의 유일한 전처리는 RGB 값의 평균을 각 픽셀에서 빼는 것이다. 그리고 매우 작은 receptive field를 가지는 3 × 3 필터를 사용하며, 5개의 max pooling 레이어는 2×2 픽셀 창에서 스트라이드 2로 수행한다. 이는AlexNet과 다르게 중첩 되지 않는다. 또한 LRN(Local Response Normalization)를 사용하지 않았는데, 이는 메모리 소비 및 계산 시간을 증가 시킨다.

첫 레이어에서 상대적으로 큰 receptive field를 사용하는 대신, 매우 작은 3×3 receptive field + ReLU 레이어를 3개 결합했다. 이러한 레이어는 7×7 layer와 유사한 receptive field를 가진다고 볼 수 있으며, 또한 파라미터 수를 줄이기 때문에 효과적이다. 위 표 중 C architecture는 1x1 convolution 을 통해 receptive field에 영향을 주지 않고 결정 함수의 비선형성을 증가시킨다. 이는 똑같은 차원 공간에 대한 선형 투영이지만, ReLU에 의해 추가적인 비선형성을 확보할 수 있다. FC 레이어에 대해서 Dropout 활용하였다.
Training
네트워크 가중치의 초기화는 중요하다. 우선 훈련이 가능할 수 있는 수준 정도의 깊이가 얕은 네트워크(위 표 중 A)를 구성한다. A에 대해서 먼저 훈련을 진행한 후, A에서 훈련된 파라미터를 이후 깊이가 깊은 네트워크의 가중치로 초기화한다.
Augmentation
기본적으로 훈련 세트에 좌우 반전 및 랜덤 RGB 변경을 활용했다. 그리고 이미지를 최소 크기(224) 보다 큰 다양한 크기를 훈련 세트로 사용하였다. 이런 다양한 크기의 학습 이미지는 두가지 방법으로 훈련할 수 있다. 첫 번째 방법은 S = 256의 입력 크기에서 훈련 후 S = 384에서 추가 훈련하는 것이며, 두 번째 방법은 처음부터 가변적인 크기의 입력으로 훈련하는 것이다. 이는 단일 모델이 다양한 스케일에 걸쳐 인식하도록 훈련되는 scale jittering에 의한 augmentation으로 볼 수도 있다. 하지만 입력 이미지 크기에 따라 채널 수는 클래스 수와 동일하나, 클래스 score의 resolution이 달라지게 된다. 이런 문제는 고정된 크기를 얻기 위해 클래스 별 score는 평균을 활용했다. 테스트 시엔 원본 이미지와 반전된 이미지의 softmax의 평균을 계산하여 이미지의 최종 점수를 얻었다.
결과
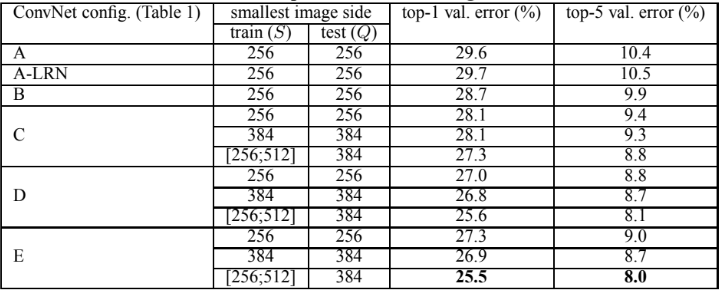
AlexNet에서 사용된 LRN의 사용에 따른 성능 향상은 없다(A vs A-LRN). 그리고 ConvNet 깊이가 증가함 (A -> B -> C -> D -> E)에 따라 오류가 감소했다. 추가적으로 훈련 시 scale jittering의 활용 (C,D,E 내 train 차이)은 훨씬 더 나은 결과를 보였다.
Localization
단순 Classification이 아닌 Object detection의 결과다. Bounding Box 예측은 GT 와 IoU(합집합 비율에 대한 교집합 비율)가 0.5보다 크면 올바른 것으로 간주한다. Pretrained ConvNet을 사용했으며, 이러한 방식은 다른 데이터 세트에 잘 일반화된다. 마지막 FC 레이어(1000D ILSVRC Classifiier)를 제거하고 SVM 분류기와 결합하여 훈련하였으며, 이 과정에서 사전 훈련된 ConvNet 가중치는 고정된 상태로 유지한다. 아래와 같이 결과는 준수했음을 알 수 있다. Object detection은 이후 다른 카테코기로 다양한 논문을 다룰 예정이다.

Reference
논문 링크 : [1409.1556] Very Deep Convolutional Networks for Large-Scale Image Recognition (arxiv.org)
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] Batch Normalization (0) | 2024.07.27 |
|---|---|
| [Classification] GoogLeNet (0) | 2024.07.25 |
| [Classification] ZFNet (1) | 2024.07.18 |
| [Classification] AlexNet (0) | 2024.07.13 |
| [Classification] LeNet (0) | 2024.07.11 |