키워드
1. AlexNet의 개선된 버전으로, CNN의 내부 작동을 시각화하여 성능을 향상.
2. "ZFNet: Visualizing and Understanding Convolutional Networks"
3. Deconvnet, Visualization, Occlusion, Correspondence
ZFNet
ConvNet은 AlexNet 이후로 관심이 늘어나며 크게 발전해왔다. 발전할 수 있었던 배경에는 다양한 이유가 있다. 먼저 수백만 개의 레이블이 지정된 훨씬 더 큰 데이터셋의 형성되었다. 그리고 매우 큰 모델의 훈련을 실용적으로 만드는 강력한 GPU가 개발되었으며, Dropout과 같은 더 나은 모델 regularization 전략이 새롭게 제안되었다.
이와 같은 발전해가고 있는 환경에서, AlexNet과 동일한 아키텍처를 기반으로 한 ZFNet을 고안하였다. 새로운 시각화 기술을 통해효과적인 디버깅을 수행하였으며, 각 레이어를 조정하며 효과적으로 성능을 향상 시켰다. 이는 ConvNet이 무작위적이고 해석 불가능한 패턴이 아니란것을 보임.
Architecture
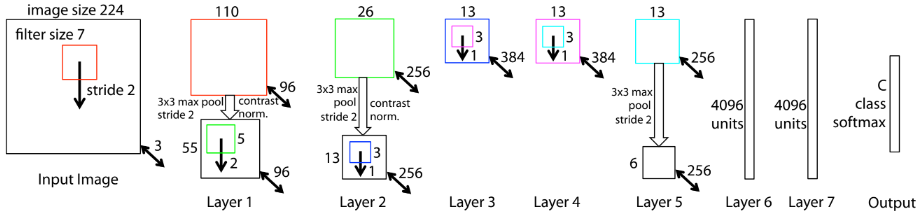
먼저 첫 번째 레이어(c)는 매우 높은 주파수와 낮은 주파수 정보가 혼합되어 있으며 중간 주파수는 거의 커버하지 않는다. AlexNet에서는 두 번째 레이어에서 첫 번째 레이어 Conv에 사용된 큰 stride 4로 인해 aliasing(d)이 발생한다. 이에 ZFNet에서는 첫 번째 레이어 필터 크기를 11x11에서 7x7로 줄이고 stride 4가 아닌 2로 변경하였다. 또한 RBF -> Softmax로 최종 output을 변경하였고, Softmax를 또 다른 데이터셋에 fine-tuning 해도 성능이 우수함을 보였다. 마지막으로 GPU는 2개가 아닌 단일 GPU 사용했다.

Visualization
DeconvNet을 이용한 시각화
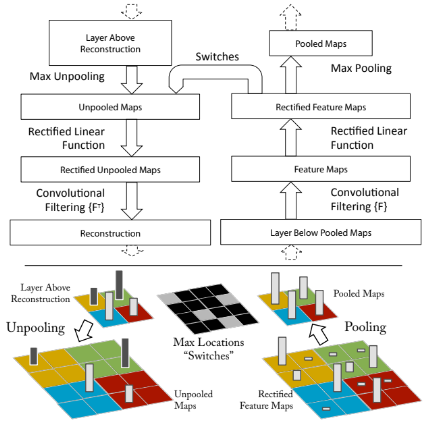
입력(이미지)은 모델의 모든 레이어 별 각각의 feature map에 영향을 준다. 이에 Feature를 활용하여 훈련 중에 모델의 학습을 관찰하고 잠재적인 문제를 진단할 수 있다. Convnet을 검사하기 위해 그림과 같이 deconvnet이 각 레이어에 연결된다. 이를 초기 입력 픽셀 공간에 도달할 때까지 반복한다. Deconvnet의 구조는 아래 3개 레이어로 구성되어있다.
- Unpooling : 최대값 위치를 기록하여 역으로 계산.
- ReLU: ReLU로 인해 feature map은 항상 양수. Deconvent에도 똑같이 ReLU를 통과시켜 양수만 유지.
- Deconv Filter: Deconvnet은 동일한 필터의 전치된 버전을 사용.
Feature 시각화

훈련이 완료된 후 모델의 feature를 시각화하였다. 추가로 시각화와 함께 해당 원본 이미지도 표시했다. 각각을 원본 이미지까지 투영하면, 클래스가 다르나 서로 비슷한 구조면 feature가 비슷해 보이는 것을 알 수 있다. 이는 변형에 대해 invariance(불변성)이 좋다는 것을 보여준다. 즉, 각 클래스의 판별 기준에만 초점을 두고 변형에는 크게 영향을 받지 않는 다는 것을 알 수 있다.
Feature의 발전 과정 시각화

훈련 동안 진행 상황을 시각화하였다. 모델의 하위 레이어>(input에 가까운 layer)는 몇 에포크 내에 수렴되는 것을 볼 수 있다. 그러나 상위 레이어(input에 먼 layer)는 상당한 수의 에포크(40-50) 후에 수렴된다. 즉, 상위 레이어가 완전히 수렴될 때까지 모델을 훈련시켜야 한다.
Feature invariance (불변성)
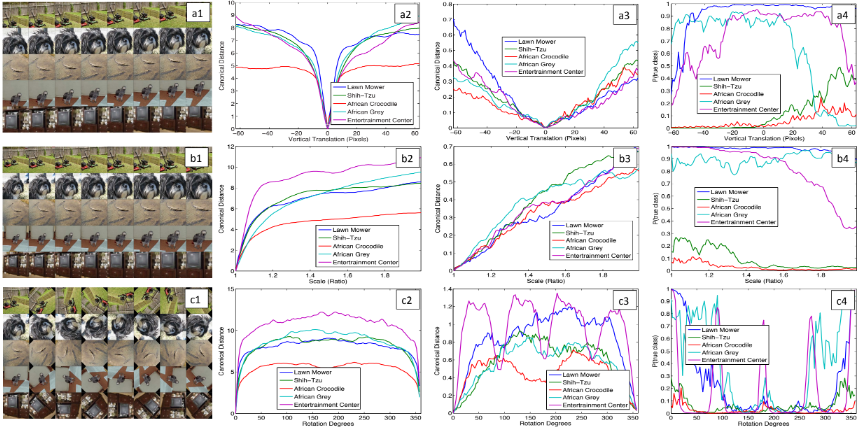
다양한 각도로 이동, 회전 및 크기 조정에 따른, 모델의 상단 및 하단 레이어에서 feature vector의 변화다. 작은 변환은 모델의 첫 번째 레이어에서는 드라마틱한 효과를 가진다. 반대로 최상위 기능 레이어에서는 영향이 적고, 변환 및 크기 조정에 준선형(quasi-linear)인 특징을 보인다. 이를 통해 네트워크는 변환 및 스케일링에 안정적이라고 판단할 수 있다.
Occlusion (가리기) sensitivity

이미지에서 개체의 위치를 실제로 식별하는지, 아니면 단지 주변 상황을 사용하는지 모호할 수 있다. 이에 여러 부분을 회색 사각형으로 순서대로 가리고 이에 따른 output을 모니터링했다. 시각화에 나타나는 이미지 영역을 가리면 feature map에서 activity가 크게 감소한다. Occlusion실험을 통해 모델이 분류를 위해 훈련되는 동안, 이미지의 로컬 구조에 매우 민감하며 단지 광범위한 장면 context만 사용하는 것이 아니라는 점을 입증하였다.
Correspondence(대응) 분석

모델은 서로 다른 이미지의 특정 부분 사이의 correspondence(대응)을 확인하는 메커니즘이 없다. 즉, 서로 다른 개의 종을 구별하기 위해서 눈을 비교하거나 코를 비교하는 메커니즘이 없이 그저 암시적으로 이를 계산한다. 이에 따라 개의 정면 이미지 5개를 무작위로 선정하고, 각 이미지에서 얼굴의 동일한 부분을 마스크 처리했다. 이후 원본 이미지와 가려진 이미지에 대한 임의 layer의 feature vector의 차이를 확인하여 모든 이미지 쌍 사이에서 이 차이에 대한 일관성을 측정했다.
그 결과 동일한 영역을 가렸을 경우 값이 더 낮게 나왔다. 즉, 값이 낮을수록 마스킹 작업으로 인한 변경의 일관성이 높아짐을 의미하다. 따라서 서로 다른 이미지의 동일한 개체 부분 간의 일치가 더 긴밀하다고 볼 수 있다.
결과
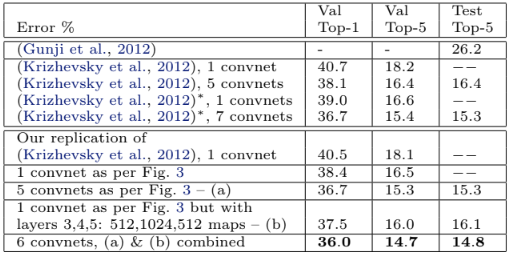
ImageNet 2012 에서 14.8%의 test 오류율을 보였다. 서로 다른 깊이의 모델 테스트 결과를 바탕으로 깊이가 좋은 성능을 얻는 데 중요하다는 것을 확인했다. 또한 중간 Conv 레이어의 크기를 늘리면 성능이 향상되나, 동시에 완전히 FC 레이어를 늘리면 Overfit이 발생한다. 이를 통해 Conv Layer는 불변성이 뛰어나기에 일반화 관점에서 효과가 뛰어나다고 볼 수 있다. 마지막으로 Softmax는 상대적으로 적은 수의 매개변수가 포함되어 있으므로, 크기가 작은 새로운 데이터셋에서 빠르게 학습하며 또한 좋은 성능을 보인다.
Reference
논문 링크 : [1311.2901] Visualizing and Understanding Convolutional Networks (arxiv.org)
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] GoogLeNet (0) | 2024.07.25 |
|---|---|
| [Classification] VGGNet (2) | 2024.07.20 |
| [Classification] AlexNet (0) | 2024.07.13 |
| [Classification] LeNet (0) | 2024.07.11 |
| [Classification] Classification 발전 과정 (0) | 2024.07.06 |