키워드
1. 다 중 크기의 필터를 결합한 Inception 모듈을 도입하여 효율성과 성능을 높힘.
2. "Going Deeper with Convolutions" (2015)
3. Inception module, 1x1 Convolution filter
네트워크 성능 향상 방법
Nerual Network의 성능을 향상시키는 가장 직접적인 첫번째 방법은 크기를 늘리는 것이다. 다만 컴퓨팅 리소스가 증가하게 된다. 다른 관점에서 Network 깊이 (Layer 수)뿐 아니라 너비(각 layer의 unit 수)도 늘릴 수도 있다. 두번째 방법은 대량의 훈련 데이터를 통한 성능 향상이다. 다만 라벨링을 위한 인적 비용이 많이 들게 된다. 그리고 훈련 데이터가 작은데 네트워크의 크기가 크다면, 일반적으로 파라미터 수가 많아지고 과적합되기 쉽다.
두 문제를 해결하는 근본적인 방법은 궁극적으로 convolution 내부에서도 fully connected 된 구조에서 sparsely connected 된 구조로 변경하는 것이다. 대부분의 현재 시스템은 Convolution을 통해 공간 영역을 sparsely 하게 활용한다. 다만 이전 레이어의 결과에 대해 fully connected 한 모음으로 구현한다. 이에, 이전 레이어에 대해 많은 수의 필터 및 더 큰 배치 크기를 통해 효율적이고 조밀한 계산을 수행한다.
Inception 모듈은 경험적으로 최적인 형태이다. 앞서 살펴봤듯 주요 아이디어는 convolutional network에서 최적의 로컬 sparse 구조를 근사화하고, 쉽게 사용할 수 있는 구성 요소를 사용하는 것이다.
Inception
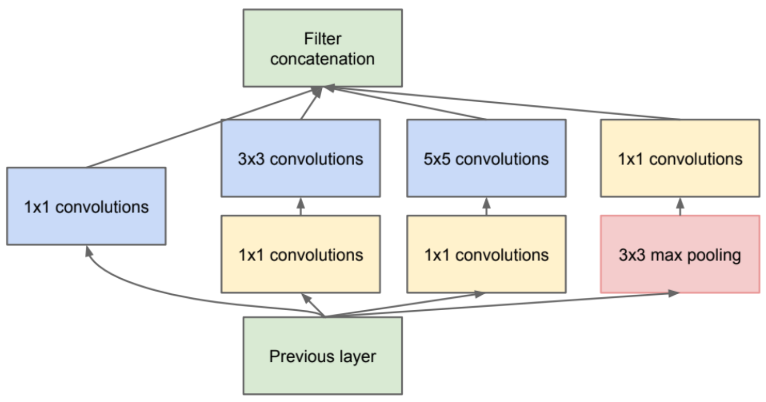
Inception의 filter 크기는 1×1, 3×3 및 5×5로 제한되지만 이 결정은 필요성보다는 편의성에 더 기초한다. 다음 단계의 입력(Inception 모듈의 출력)은 연결된 모든 필터 결과의 조합되며, 계산 요구 사항이 너무 많이 증가하는 모든 곳 (3x3, 5x5)에 차원 축소를 적용한다.
낮은 차원의 임베딩에도 상대적으로 큰 이미지 패치에 대한 많은 정보가 포함되어있다. 다만 압축된 정보는 모델링하기가 더 어려움이 있다. 이에 신호를 한꺼번에 집계해야 할 때만 신호를 압축한다. 1×1 컨볼루션은 비용이 많이 드는 3×3 및 5×5 convolution 이전에 감소를 계산하는 데 사용한다.
Inception 모델과 유사하게 동일한 이미지에서 다양한 이미지 처리를 위해 Gabor 필터를 사용하는 경우도 있다. 그러나 Inception의 차이는 고정된 filter 사용이 아닌 모든 filter가 학습 가능하다는 점이다. 그리고 신경망의 표현력(representational power)를 높이기 위해 1×1 convolutional layer + ReLU를 단독으로 사용하며, 주로 계산 병목 현상을 제거하기 위한 차원 축소로 사용한다.
Architecture (GoogLeNet)

GoogLeNet은 Inception 구조를 활용한 22 층의 architecture이며, Network-in-Network 구조로 볼 수 있다. 주요 특징은 컴퓨팅 리소스의 활용도가 향상된다는 것이며, GoogLeNet은 AlexNet 등의 우승 아키텍처보다 12배 더 적은 파라미터를 사용한다. 즉, 계산 복잡성을 통제할 수 없이 증가시키지 않고도 각 단계의 장치 수를 크게 늘릴 수 있다는 장점이 있다.
Softmax를 classifier로 사용하며, Average pooling와 이후 추가 FC 레이어를 사용하면서 다른 데이터셋에 맞게 네트워크를 쉽게 조정하고 미세 조정할 수 있다. 또한 FC 레이어를 average pooling으로 전환하면 Top-1 정확도가 약 0.6% 향상된다.
네트워크의 깊이가 상대적으로 깊기 때문에 경사도를 모든 레이어에 효과적으로 전파하는 능력이 중요하다. 이에 중간 레이어에 보조 classifier를 추가함하여 보조적인 기울기를 추가하였으며, 추가적인 regularization을 제공할 것으로 기대하였다. 다만 해당 손실은 할인 가중치가 적용되며, 테스트 시엔 이러한 보조 네트워크는 삭제된다.

Training
모델 중 일부는 주로 작은 이미지에 대해 훈련되었고, 다른 모델은 더 큰 이미지에 대해 훈련되었다. 이미지를 256, 288, 320, 352로 크기 조정 후 기준에 따라 추가 이미지 생성했다. 최종적으론 개별 이미지 별 4×3×6×2 = 144개의 추가 이미지가 생성된다.
추가로 크기는 유지 색상을 변형하는 photometric 왜곡을 사용하였으며, 과적합을 어느 정도 방지하는 데 유용하다. 하지만 충분히 많은 훈련 세트가 존재하면 이러한 augmentation은 필요하지 않을 수 있다.
결과
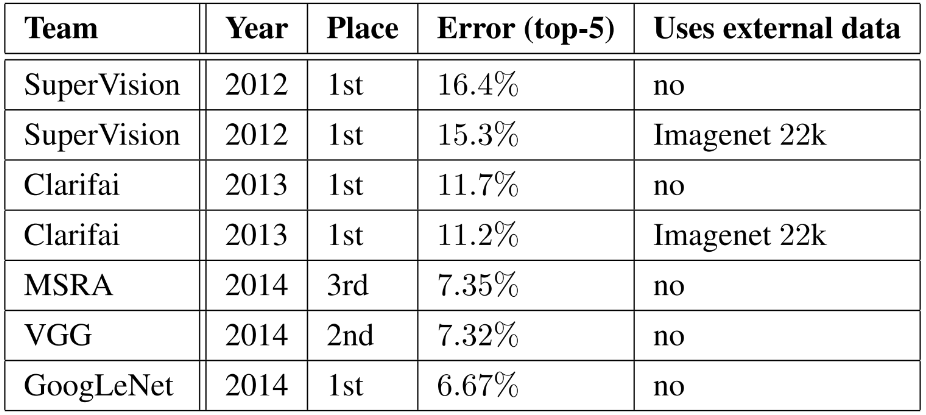
동일한 GoogLeNet 모델의 7개 버전(더 넓은 버전 1개 포함)을 독립적으로 훈련하고 앙상블 예측을 수행했다. 이를 통해 6.67%의 Top-5 오류율를 획득했다.
Localization
Inception 모듈을 통한 6개의 ConvNet 앙상블 모델의 결과이다. Object detection은 이후 다른 카테코기로 다양한 논문을 다룰 예정이다.

Reference
논문 링크 : [1409.4842] Going Deeper with Convolutions (arxiv.org)
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] ResNet (0) | 2024.08.01 |
|---|---|
| [Classification] Batch Normalization (0) | 2024.07.27 |
| [Classification] VGGNet (2) | 2024.07.20 |
| [Classification] ZFNet (1) | 2024.07.18 |
| [Classification] AlexNet (0) | 2024.07.13 |