키워드
1. 잔차 연결을 도입하여 매우 깊은 네트워크를 효과적으로 학습.
2. "Deep Residual Learning for Image Recognition" (2015)
3. Residual, shortcut connection
ResNet
Deep Network는 다양한 수준의 featrue와 classifer를 end-to-end Multi layer 방식으로 통합한다. 그리고 feature의 "수준"은 쌓인 레이어 수(깊이)에 따라 풍부해진다. 즉, 표현력이 증가한다고 표현할 수 있는데 표현의 깊이는 많은 시각적 인식 작업에서 가장 중요하다.
하지만 더 많은 레이어를 쌓는 것이 목표나, 기울기 소멸/폭발이라는 문제 존재한다. 이에 오히려 네트워크가 깊을수록 학습 오류가 높아져 테스트 오류가 발생한다. Normalized 된 initalization 혹은 nomralizaion layer를 통해 일부 해결했으나 여전히 깊이의 한계가 있다. 이에 Deep Residual Learning 프레임워크를 도입하여 성능 저하 문제를 해결하였다. 레이어 입력을 참조하여 residual function를 학습하도록 레이어를 재구성하였다.

Residual Learning

기존 레이어는 입력과 출력이 직접적으로 매핑된다. 이와 달리 잔차(Residual) 레이어는 입력과 출력간 잔차가 매핑된다. 이러한 비선형 레이어 stack을 통해 잔차를 0으로 만드는 것이 학습 관점에서 더 쉬울 것이다.
F(x) +x는"shortcut connections"이 있는 feed-forward 신경망에 의해 구현된다. 기본적으로 x와 F의 차원은 동일해야하며, F(x) +x 연산 후 두 번째 activation 연산 수행한다. Shortcut은 추가 파라미터나 계산 복잡성을 유발하지 않는다. 이를 활용한 극도로 깊은 residual 네트워크는 최적화하기 쉽지만, 같은 수준의 깊이로 구현된 "일반" 네트워크(단순히 레이어를 쌓는 것)는 깊이가 증가할 때 더 높은 훈련 오류를 보인다. 이를 통해 residual 네트워크는 깊이가 크게 증가하여도 쉽게 정확도 향상을 보이며, 이전 네트워크보다 훨씬 더 나은 결과를 생성한다.

Shortcut connections는 매우 유연하게 변형이 가능하며, 기본적으로 2개 또는 3개의 레이어가 사이의 shortcut이 테스트에 사용되었다. 다만 필요에 따라 더 많은 레이어도 가능하다.
Local Response

이런 구조는 더 깊은 모델의 훈련 오류가 더 얕은 모델보다 큰 현상에서 아이디어를 얻었다. 성능 저하 문제는 여러 비선형 레이어에 의해 identity 매핑을 근사화하는 어려움으로부터 발생했다. 하지만 Residual을 사용하면, 여러 비선형 레이어의 가중치를 0으로 학습하여 identity 매핑에 근접한다.
위 그림은 레이어 별 response의 표준편차(std)를 보여준다. Plain의 response는 BN 이후, activation 이전의 3×3 레이어의 출력이다. ResNet의 경우 이 분석은 잔차 함수의 response다. ResNet이 일반 네트워크보다 일반적으로 더 작은 response 을 가지는 것을 볼 수 있으며, 더 깊어질수록 크기가 더 작아진다. 이 실험을 통해 residual이 일반적으로 작은 response를 가지며, 잔차 함수가 일반적으로 비잔차 함수보다 가중치가 0에 더 가까울 수 있다는 것을 확인할 수 있다.
Architecture

비교를 위한 base network는 VGGNet을 기반으로 34개 레이어로 구성된 Network 설계했다. 동일한 feature map 크기면 동일한 수의 filter, 절반으로 줄어들면 filter 수를 2배로 설계되었다.

다만 이러한 연결은 크기가 동일해야한다. 왼쪽 식은 실선 연결의 수식이며, Shortcut connections 중 입력과 출력이 동일한 단순 합 연산을 의미한다. 오른쪽 식은 점선 연결의수식이며, 차원이 동일하지 않다면 projection(투영) shortcut 방식으로 차원을 증가시켜 연결 구현한다. 그리고 각 conv 직후와 activation 직전에 Batch normalization을 추가한다.

Projection Shortcut
차원이 동일하지 않은 경우를 처리하기 위한 project shortcut 구현 방법이다. A 방식은 zero-padding으로 추가 파라미터 없다. B 방식은 부족한 차원에 대해서만 가중치 Ws를 활용한 projection 수행한다. C 모든 shortcut에 대해 Ws를 활용하여 projection 수행한다. 옵션 간 차이가 있으나 이는 성능에 큰 차이를 보이지 않는다. 따라서 모델 크기를 줄이기 위해 옵션 C는 사용하지 않았따

Bottleneck
과도한 학습 시간을 방지하고자 bottleneck 구조로 빌딩 블록을 수정한다. 3x3 conv 레이어 2개 대신 1×1, 3×3, 1×1 conv 3개의 레이어로 수정되었다. 이러한 방식으로 50-layer ResNet은 34-layer net의 각 2-layer 블록을 이 3-layer 병목 블록으로 대체하여 생성되었다. 그리고 더 많은 3층 블록을 사용하여 101층 및 152층 ResNet을 구성한다.
결과
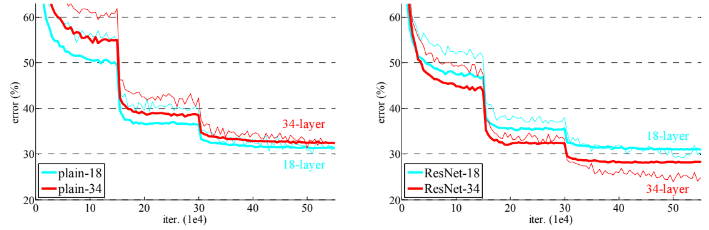
먼저 18층과 34층의 일반 네트워크를 평가했으며, 더 깊은 34층 네트워크가 더 얕은 18층 네트워크보다 오류가 더 높다. 이후 18층과 34층 ResNets를 평가했으며, Residual learning으로 반대 결과가 확인되었다. 성능 저하 문제가 잘 해결되었으며 깊이에 따라 정확도가 향상된다. 또한, 18층 일반/ResNet가 둘 다 비교적 정확하지만, ResNet이 더 빠르게 수렴한다. 동일한 34층 간 비교에서는 ResNet의 성능이 좋다.

깊이가 증가가 정확도가 크게 기여한다. 심지어 단일 모델가 다른 모델의 앙상블 결과보다 성능이 뛰어났다. 10개 클래스의 50k 훈련 이미지로 구성된 상대적으로 작은 CIFAR-10 데이터셋에서도 동일한 결과 확인되었다.

일반 네트워크은 깊이가 증가할수록 훈련 오류가 더 높아진다. ResNet은 유사하게 최적화 어려움을 극복하고 깊이가 증가할 때 정확도가 향상된다. 다만 1202 레이어 네트워크의 테스트 결과는 110 레이어 네트워크보다 나쁘다. 이는 과적합 때문이라고 예상되며, 1202 레이어 네트워크는 이 작은 데이터세트에 비해 불필요하게 큰 것이 원인으로 판단된다.
Reference
논문 링크 : [1512.03385] Deep Residual Learning for Image Recognition (arxiv.org)
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] SqueezeNet (0) | 2024.08.06 |
|---|---|
| [Classification] DenseNet (0) | 2024.08.03 |
| [Classification] Batch Normalization (0) | 2024.07.27 |
| [Classification] GoogLeNet (0) | 2024.07.25 |
| [Classification] VGGNet (2) | 2024.07.20 |