키워드
1. 각 층을 모든 이전 층과 연결하여 학습 효율성을 극대화.
2. "Densely Connected Convolutional Networks" (2016)
3. Dense, feature reuse, model compactness
DenseNet
CNN이 점점 더 깊어짐에 따라 새로운 연구 문제가 등장하였다. 입력 또는 기울기가 여러 레이어을 통과함에 따라, 네트워크의 끝(또는 시작)에 도달할 때 사라지게 된다. ResNet에서 이를 초기 레이어에서 이후 레이어로 short connection를 생성하여 해결하고자 했다. 이를 통해 훨씬 더 깊고 정확하며 효율적으로 학습할 수 있게 되었다.
유사한 개념으로 각 레이어를 다른 "모든" 레이어에 연결하는 Dense Convolutional Network(DenseNet)를 활용할 수 있다. 각 레이어에 대해 모든 이전 레이어의 feature map이 입력으로 사용되며, 자체 feature map은 동일한 방식으로 후속 레이어의 입력으로 사용한다. 이를 통해 기울기 소멸 문제를 완화하고, 기능 전파를 강화, 기능 재사용을 장려, 파라미터 수를 크게 줄일 수 있다.
Dense Block
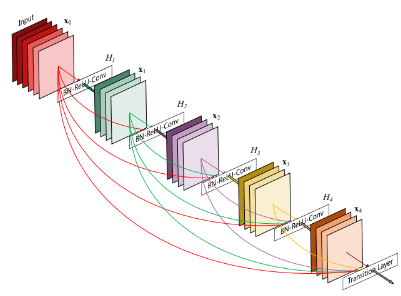
위 이미지와 같이 조밀한 연결 패턴으로 인해 DenseNet 이라고 명명한다. ResNet과 입력 구성에서 차이가 있다. ResNet은 입력이 합계를 통해 전달되며 feature 자체를 전달하지 않는다. 이는 정보 흐름을 방해하며, DenseNet은 이전의 모든 conv block의 feature map으로 구성된 입력을 사용한다. 이러한 효과는 중복된 feature map을 다시 학습할 필요가 없기 때문에 파라미터 수를 줄일 수 있다.
Model Compactness
DenseNet은 네트워크 전체에서 feature 재사용을 장려하고 compact한 모델이다.전통적인 Feed-forward 아키텍처는 레이어에서 레이어로 전달되는 알고리즘이다. 이 과정에서 상태를 변경해야하고, 동시에 정보를 보존하여 전달해야한다. ResNet은 이 정보 보존을 shortcut을 통해 명시적으로 표현한다.
DenseNet은 추가로 네트워크에 추가되는 정보와 보존되는 정보를 구분하여 명시적으로 표현한다. 이는 입력에 대해 일부 feature map만 추가하고, 나머지 feature map은 변경되지 않은 상태로 유지하여 구현한다. 이를 통해 굉장히 좁게 (필터 수를 적게) 네트워크을 설계할 수 있다. 결과적으로 네트워크 전체에 걸쳐 향상된 정보 흐름과 기울기를 통해 쉽게 훈련되도록 하며, 크기가 더 작은 데이터에 대한 overfit도 줄이는 것을 관찰된다.
Implicit Deep supervision
개별 레이어들은 손실 함수로의 더 짧은 연결을 통해 추가적인 supervision(지도)을 받는다. 즉, 동일한 손실 함수가 모든 레이어 간에 공유되어 역전파를 훨씬 덜 복잡하게 해준다.
Architecture

매우 깊거나 넓은 아키텍처에서 표현력을 끌어내는 대신, DenseNet은 feature 재사용을 통해 훈련하기 쉽고 매개변수 효율성이 높은 압축 모델을 생성한다. 서로 다른 레이어에서 학습된 feature map을 연결하면 후속 레이어의 입력의 다양성이 증가하고 효율성이 향상된다. 이는 NIN(Network in Network)구조로 볼 수 있으며, 동일한 NIN구조를 갖추고 있는 ResNet과 구분되는 주요 차이점이며, Inception 에 비해 DenseNet은 더 간단하고 효율적이다.
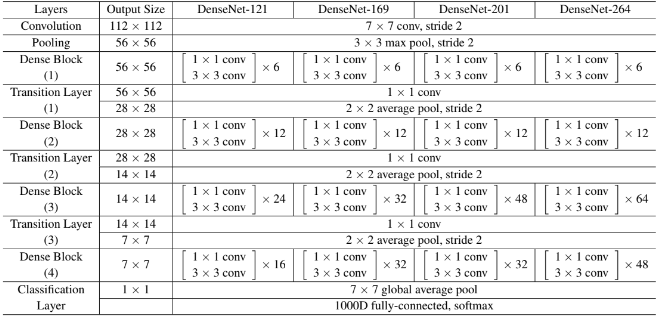
여러번 언급했듯 모든 레이어에서 모든 후속 레이어로 직접 연결을 구현한다. 모든 Conv는 BN - ReLU - Convolution으로 구성되어 있으며, Dense 블록 사이를 연결하는 conv와 pooling을 수행하는 전환(transition) 레이어로 구성되어 있다.
각 Dense block은 k(Growth rate)개의 feature map을 생성한다. 이를 통해 l 번째 레이어의 feature map 개수는 k0 +k ×(l−1) 로 계산되며, k는 Growth rate로 정의되며 하이퍼파라미터이다. 평가에 사용된 모든 네트워크의 Growth rate는 k = 32가 사용되었다.
계산 효율성을 향상시키기 위해 각 3×3 conv 전에 bottleneck으로 1×1 conv를 도입하였다. 즉, BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3) 의 순서로 네트워크가 구성되어있다. 그리고 전환 레이어에서 feature map의 수를 줄일 수 있다. θ 로 표현되며 compression이라 부른다. 0 < θ ≤ 1 범위를 가지며, θ 비율로 feature map이 줄어든다.
이에 따른 다양한 형태의 아키텍처를 설계할 수 있다. DenseNet-B는 1×1 컨볼루션이 4k개의 feature map을 생성하는 모델이며, DenseNet-C는 θ = 0.5로 설정되었고 DenseNet-BC는 모두 사용되는 경우이다.
결과

여러 데이터 세트에서 DenseNet의 효율성을 경험적으로 입증되었다. DenseNet은 ResNet보다 더 적은 수의 파라미터를 사용하면서 더 낮은 오류율을 달성하였으며, augmentation 없이 denseNet은 큰 차이로 더 나은 성능을 발휘했다. 또한 DenseNet-BC가 CIFAR 데이터셋에서는 일관되게 최고의 성능을 보인다. 다만 상대적으로 쉬운 SVHN에선 성능이 다소 떨어지며, 이는 매우 깊은 모델이 훈련 세트에 과적합될 수 있다는 점으로 설명할 수 있다.
Compression이나 bottleneck이 없어도 L(깊이)과 k(Growth rate)가 증가할수록 denseNet의 성능이 더 좋아지는 경향을 보인다. 이는 denseNet이 더 크고, 깊은 모델의 향상된 representatinon power을 활용할 수 있음을 시사한다. Compression이나 bottleneck을 갖춘 denseNet BC는 특히 파라미터를 효율적으로 활용.

Overfitting
효율적인 파라미터 사용의 긍정적인 효과는 overfitting에 덜 취약해진다는 점이다. Augmentatation이 없는 데이터 세트에서 DenseNe의 개선이 특히 두드러진다는 것을 관찰할 수 있다.

Feature reuse
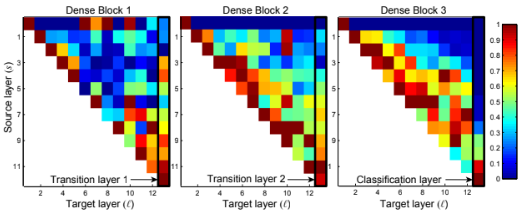
DenseNet은 모든 이전 레이어의 feature map에 액세스할 수 있도록 허용한다. 블록 내의 각 conv 레이어에 대해 이전 S 레이어와 연결에 할당된 가중치의 평균을 계산하였다. Block 별 검은색 직사각형으로 강조 표시된 영역은 두 개의 전환 레이어와 classifier에 해당한다.
모든 레이어는 동일한 블록 내 여러 입력에 가중치를 분산시키는 것을 알 수 있다. 이를 통해 초기 레이어에서 추출된 특징이 동일 dense block의 나중 레이어에서 직접 사용된다고 볼 수 있다. 유사하게 전환 레이어의 가중치는 dense block 내의 모든 레이어에 가중치를 분산한다. 다만 전환 레이어의 출력(삼각형의 맨 위 행)에 가장 낮은 가중치를 할당한다. 이는 전환 레이어는 중복된 feature를 출력한다고 유추할 수 있다.
최종 classifier 레이어는 최종 feature map에 집중된 것으로 보이며, 이는 후반에 더 높은 수준의 feature가 생성되었음을 시사한다.
Reference
논문 링크 : [1608.06993] Densely Connected Convolutional Networks (arxiv.org)
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] MobileNet (0) | 2024.08.08 |
|---|---|
| [Classification] SqueezeNet (0) | 2024.08.06 |
| [Classification] ResNet (0) | 2024.08.01 |
| [Classification] Batch Normalization (0) | 2024.07.27 |
| [Classification] GoogLeNet (0) | 2024.07.25 |