키워드
1. 학습 속도를 증가시키고 안정성을 개선.
2. "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift" (2015)
3. Batch Normalization, Internal covariate shift
NN의 입력 분포 특성
Neural Network는 레이어의 파라미터가 업데이트됨에 따라 다음 레이어의 입력 분포가 변경되며, 파라미터의 작은 변화는 네트워크가 깊어질수록 증폭된다. 입력 분포의 변화는 레이어가 새로운 분포에 지속적으로 적응해야 하기 때문에 문제가 된다. 이는 낮은 learning rate을 사용하게끔 강제하고 신중한 가중치 초기화를 요구하며 훈련 속도를 늦춘다.
Sigmoid activation이 있는 레이어를 고려해보자. 훈련시 입력 분포가 더 안정적으로 유지되도록 보장할 수 있다면, 포화 영역에 갇힐 가능성이 줄어들고 훈련이 가속화된다. 즉, Batch Normalization을 아키텍처의 일부로 사용하면 이러한 문제가 보완되는 것을 의미한다. 단지 activation을 normalize하는 것만으로 훈련 전반에 걸쳐 actiavtion의 안정적인 분포를 달성 수 있다. 또한 원본 모델 보다 14배 더 적은 훈련 step으로 동일한 정확도를 달성한다.
Internal covariate shift
Internal Covariate Shift 란 훈련 중 네트워크 파라미터 업데이트로 인한 activation 분포의 변화로 정의한다. 입력이 whitening되면 네트워크 훈련이 더 빠르게 수렴된다. 각 레이어는 이전 레이어에서 생성된 입력을 사용하므로, 각 레이어의 입력에 대해 whitening를 구현하는 것이 좋다. 이를 위해 네트워크를 직접 수정하거나, activation 에 파라미터를 추가하여 whitening 수행을 고려할 수 있다.
예를 들어, bias b를 추가하여 b는 훈련 세트의 activation 평균을 빼 정규화되도록 학습한다. 하지만 이 경우 b의 업데이트와 이에 따른 normalization의 변경이 합쳐지면서, 레이어의 출력이 변경되지 않았으며 결과적으로 손실도 발생하지 않는다. 훈련이 계속됨에 따라 b는 손실이 고정된 상태로 무한정 증가하여 activation이 커지며, 최종적으로 모델이 폭발하게 된다.
이에 모든 파라미터 값에 대해 항상 원하는 분포로 활성화를 생성하는 방법을 활용하고자 한다. Normalization을 주어진 학습 예제 x뿐만 아니라 모든 예제 x을 활용한 방식이다. 전체 훈련 데이터의 통계를 기준으로 훈련 예제의 활성화를 정규화하여 네트워크의 정보를 보존한다.
Batch Normalization
모든 레이어의 whitening은 비용이 많이 들고 레이어 별 차별화가 불가능하다. 이에 두가지 방법을 고려할 수 있다. 첫 번째는 레이어 개별로 평균을 0으로 하고 분산을 1로 만들어지도록 독립적으로 normalize하는 방식이다. 다만 단순히 레이어의 각 입력을 normalize하면 레이어가 표현할 수 있는 내용이 변경된다. 이에 삽입된 변환이 항등 변환을 나타낼 수 있는지 확인해야한다. 각 활성화 x(k)에 대해 정규화에 사용되는 파라미터 쌍 γ(k), β(k)를 도입하여, 원래 모델 파라미터와 함께 학습되어 네트워크의 표현력을 복원한다. (γ(k) =Var[x(k)], β(k) = E[x(k)])
두 번째는 미니 배치 방식을 활용하여 각 활성화의 평균과 분산에 대한 추정치를 생성한다. SGD는 훈련 데이터 세트의 손실을 최소화하기 위해 파라미터를 최적화한다. 각 훈련 단계에서 크기 m의 mini-batch x1...m를 활용하며, mini-batch의 근사값을 최적화에 사용한다. 이는 전체 훈련 세트에 대한 기울기의 추정치이며, 배치 크기가 증가함에 따라 품질이 향상된다.

Batch Normalization을 activation 직전 추가하여 activation의 입력을 조작한다. 정규화된 x(k)의 결합 분포는 훈련 과정에서 변경될 수 있지만, 정규화된 입력의 도입으로 내부 공변량 이동이 적어져 하위 네트워크의 훈련이 가속화된다. 이 변환을 통해 역전파시 BN의 파라미터에 대한 기울기도 함께 계산되어야 한다. 즉, BN은 normalize된 activation을 네트워크에 도입하는 미분 가능한 layer다.
Architecture

x = Wu+ b를 정규화하며 activation 앞에 BN을 추가한다. (W : 가중치, u : 입력, b : bias, g : activation) Wu + b는 대칭적이고 비희소적인(nonsparse) 분포, 즉 "가우스 분포"를 가질 가능성이 높다. 이를 normalize하면 안정적인 분포로 activation이 생성될 가능성이 높다.
Wu+b를 normalize 하기 때문에 bias b는 효과 줄어들 수 있다. 즉, z = g(Wu + b)는 z = g(BN(Wu))로 대체할 수 있다. 그리고 Dropout은 일반적으로 과도한 피팅을 줄이기 위해 사용되는 반면, BN이 적용된 네트워크에서는 제거되거나 강도가 감소될 수 있다.
Training
BN은 효율적인 훈련을 가능하게 하지만 테스트 중에는 필요하지도 바람직하지도 않다.
NN은 학습률이 너무 높으면 기울기가 폭발 혹은 사라지거나, local minimum 값이 좋지 않다. Normalize는 이러한 문제를 해결하는 데 도움이 된다. 즉, 훈련이 비선형성의 포화 상태에 갇히는 것을 방지한다. 일반적으로 파라미터의 규모가 커지는 경우, 역전파 중에 기울기가 발생하여 모델 폭발하게 된다. Batch normalization을 사용하면 역전파시 파라미터 크기에 영향을 받지 않으며, 기울기 크기를 유지할 수 있다.
하지만 단순히 네트워크에 BN을 추가하는 것만으로는 장점을 최대한 활용할 수 없으며, 아래와 같은 추가 조치가 함께 사용되어야 한다.
- Learning rate을 높인다. 부작용 없이 큰 learning rate로 학습 속도를 높일 수 있으며 learing rate 감소도 가속화한다.
- Dropout을 제거한다. Batch Normalization으로 동일한 효과를 얻을 수 있다.
- L2 가중치 regularization을 줄인다.
- LRN 제거한다.
- 동일한 예가 항상 미니 배치에 함께 표시되는 것을 방지한다.
- Augmentation을 줄인다. 더 빠르게 학습하며 각 예제를 더 적은 횟수로 관찰하여, "실제" 이미지에 집중하게 한다.
결과
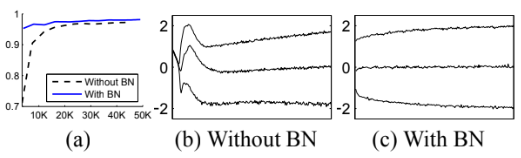
Base Network와 Batch Normalization이 적용된 Network 간의 비교 결과다. Batch Normalization이 적용된 네트워크는 테스트 정확도가 더 높다. 그리고 Base Network의 분포는 시간이 지남에 따라 평균과 분산 모두 크게 변하므로 후속 레이어의 훈련이 복잡하지만, BN이 적용된 네트워크의 분포는 훈련이 진행됨에 따라 훨씬 더 안정적이므로 훈련에 도움이 된다.

BN-Baseline 은 non-linearity 이전에 전부 BN을 적용한 Inception 모델이다. Learning rate을 더 높이면(BN-x30) 모델이 처음에는 다소 느리게 학습되지만 최종 정확도는 더 높아진다. 또한 gradient vanshing 때문에 학습이 어려운 sigmoid가 activation으로 활용되어도, BN을 통해 학습이 가능하다.

앙상블에는 6개의 BN-x30 네트워크를 사용하였으며, 4.9%의 Top-5 오류율을 보인다.
Reference
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] DenseNet (0) | 2024.08.03 |
|---|---|
| [Classification] ResNet (0) | 2024.08.01 |
| [Classification] GoogLeNet (0) | 2024.07.25 |
| [Classification] VGGNet (2) | 2024.07.20 |
| [Classification] ZFNet (1) | 2024.07.18 |