키워드
1. >AlexNet과 유사한 성능을 유지하면서도 파라미터 수를 크게 줄임.
2. "SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size" (2016)
3. Squeeze, Expand, Fire module, Squeeze ratio, pct3x3
효율적인 CNN 설계
CNN에 대한 최근 연구는 주로 정확도 향상에 중점을 둔다. 하지만 아키텍처가 깊고 넓어지면서 동일한 정확도로 더 작은 CNN 아키텍처를 필요로 한다. 아래는 작은 아키텍처의 장점이다. 이를 바탕으로 SqueezeNet이라는 작은 CNN 아키텍처를 고안하였다.
- 분산 훈련 중 서버 간 통신이 덜 필요하다. 더 빠르게 훈련 할 수 있게 된다.
- 자율주행차로 새 모델을 업데이트 하는데 더 작은 대역폭만 필요하다. 자율주행을 위해 주기적으로 자사 서버에 있는 신모델을 고객 차량에 복사(OTA(Over-The-Air) 업데이트)한다. AlexNet을 사용하려면 서버에서 자동차까지 240MB 필요하며, 크기가 작아지면 자주 업데이트하는 것이 더 가능하다.
- 메모리가 제한된 FPGA 및 기타 하드웨어에 배포하는 것이 가능해진다.
Fire module

SqueezeNet의 NiN 구조인 Fire module은 세 가지 주요 특징으로 이루어진다.
- 3x3 filter를 1x1 filter로 교체했다. 이를 통행 파라미터가 9배 줄어든다
- 3x3 filter의 입력 채널 수를 줄였다. 3x3 필터 수를 줄이는 것뿐만 아니라 3x3 필터에 대한 입력 채널 수를 줄이는 것도 파라미터를 줄이는 방법이다.
- Conv 레이어가 큰 map을 갖도록 네트워크 후반부에 down sampling을 수행했다. 이를 통해 동일한 조건에서 더 높은 정확도를 유도할 수 있다.
(1)과 (2)는 정확성을 유지하면서 파라미터 수를 줄이는 방법, (3)은 제한된 파라미터에서 정확도를 극대화하는 방법이다. 이를 바탕으로 설계된 Fire 모듈 압착(squeeze) 레이어과 확장(expand) 레이어로 이루어져 있다. 압착 레이어은 1x1 conv 레이어로만 이루어져 있으며, 확장 모듈은 1x1 및 3x3 conv가 혼합되어 있다.
SqueezeNet Architecture

SqueezeNet은 8개의 Fire 모듈로 이루어져 있다. 처음부터 끝까지 fire 모듈당 filter 수를 점차적으로 늘리며, 9번째 fire 모듈 이후에 50% 비율의 dropout이 적용된다. 다른 아키텍처와 큰 차이점은 FC 레이어가 없다는 점이다. 또한 Deep compression 논문에서 제시된 sparsity와 quantization이 적용되었다.
Neural Network Design Space Exploration
Design Space Exploration(DSE)는 주로 더 높은 정확도를 제공하는 NN 아키텍처를 찾기 위한 작업이다. 다만 SqueezeNet의 DSE는 높은 정확도 보단, 모델 크기와 정확도에 어떻게 영향을 미치는지 조사하였다. 이를 통해 CNN 아키텍처 선택이 모델 크기와 정확도에 미치는 영향을 이해하고자 하였다. 아래와 같이 2가지로 모델을 구분하여 분석할 수 있다.
- Microarchitecture : 효과적인 아키텍처 구성을 위해 사용되는 빌딩 블록 또는 모듈을 의미. (Inception, fire module)
- Macroarchitecture : 여러 모듈로 구성된 시스템 수준의 End-to-End Architecure를 의미. (GoogLeNet, SqueezeNet)
SqueezeNet Microarchitecture
Microarchitecture인 fire 모듈은 5개의 하이퍼파라미터가 존재한다. 실험 결과에서는 base = 128, incre = 128, freq = 2, pct3x3 = 0.5, SR = 0.125를 사용했다.
- base : CNN의 첫 번째 Fire 모듈에 있는 확장 필터 수.
- incr : Filter 개수 증가 기준.
- freq : 모듈별 filter 개수 증가 비율.
- pct3x3 : 모든 fire 모듈에서 공유되는 3x3 filter 수의 비율.
- SR (Squeeze ratio) : Fire 모듈 내 압착 레이어의 필터 수와 확장 레이어의 필터 수 사이의 비율.

SR을 0.125 이상으로 높이면 정확도가 증가하나 용량이 함께 증가하며, 0.75 수준에서 saturation 된다. 그리고 pct3x3을 0.01에서 0.99까지 변경하여, 1x1 및 3x3 filter의 비율이 모델 크기와 정확도에 어떤 영향을 미치는지 확인하였다. 0.5에서 85.6% 정확도로 saturation 되며, 비율을 더 늘리면 모델 크기가 더 커지지만 정확도는 향상되지 않는다.
SqueezeNet Macroarchitecture
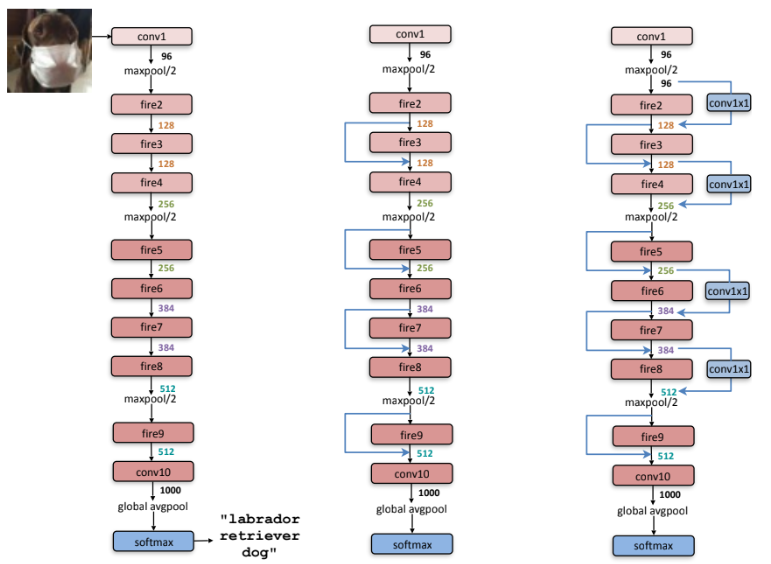
ResNet의 아이디어를 사용한 세 가지 아키텍처를 비교했다. 입력 채널 수와 출력 채널 수가 동일한 간단한 경우는 절반 밖에 없으며, 가운데가 이를 구현한 예시다. 동일 하지 않는 경우 오른쪽과 같이 복잡한 연결을 사용해야 한다. 이는 필요한 출력 채널 수와 동일하게 설정된 1x1 conv 레이어를 포함하는 shortcut으로 정의된다. 따라서 1x1 conv로 인해 모델에 파라미터를 추가하게 된다.
이러한 shortcut은 압착 레이어로 인해 발생하는 bottleneck 현상을 완화하는 데 도움을 준다. 압착 비율(SR)에 따른 심각한 차원 감소로 인해 제한된 양의 정보만 압착 레이어를 통과한다. 하지만 Shortcut을 추가함으로써 압착 레이어 주위로 정보가 흐를 수 있는 통로를 확보하게 된다고 볼 수 있다.

결과

모델의 목표는 AlexNet 모델을 압축하는 것이며, State-of-the-art를 갱신하는 것이 목표가 아니다. SqueezeNet은 AlexNet에 비해 모델 크기가 50배 감소하는 동시에 AlexNet와 동등 혹은 뛰어난 성능을 보인다. AlexNet과 동일한 정확도를 갖춘 모델은 용량이 0.66MB 수준으로, 압축되지 않은 32비트 값을 사용하더라도 SqueezeNet은 모델 크기는 1.4배 더 작아진다. 이를 통해 작은 모델에 비트가 큰 부동 소수점의 표현력은 효율이 매우 떨어진다는 것을 확인할 수 있다.
Reference
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] Xception (0) | 2024.08.10 |
|---|---|
| [Classification] MobileNet (0) | 2024.08.08 |
| [Classification] DenseNet (0) | 2024.08.03 |
| [Classification] ResNet (0) | 2024.08.01 |
| [Classification] Batch Normalization (0) | 2024.07.27 |