키워드
1. 변환 집계를 통해 잔차 네트워크의 성능을 향상.
2. "ResNeXt: Aggregated Residual Transformations for Deep Neural Networks" (2017)
3. ResNeXt, ResNet, Network in Neuron, Cardinality,
Network Engineering
Filter 크기, stride 등등 하이퍼파라미터의 수가 증가함에 따라 아키텍처 설계가 점점 더 어려워지고 있다. 특히 레이어가 많은 경우에 두드러지며, 이에 "Feature engineering"에서 "Network Engineering"으로 전환이 이루어지고 있다.
이에 관련하여 이미지 분류를 위한 간단하고 고도로 모듈화된 ResNeXt 아키텍처가 고안되었다. 매우 깊은 네트워크를 구축하는 간단하면서도 효과적인 전략을 갖추고 있으며, 단순한 설계로 인해 설정해야하는 하이퍼 매개변수를 최소한으로 줄인 homogeneous(동일한 구조의) multi-branch 아키텍처로 소개된다.
"Cardinality"(transformation 집합의 크기)라고 하는 새로운 차원을 사용하였으며, 경험적으로 cardinality를 높이면 정확도를 향상시킬 수 있음을 확인하였다. 또한카디널리티를 늘리는 것이 더 깊거나 넓어지는 것보다 더 효과적이다.
Network in Neuron
네트워크는 크게 두 가지 방향으로 발전해왔다.
- 더욱 깊은 네트워크 : VGGNet, ResNet 등으로 대표되며 동일한 모양의 레이어 혹은 빌딩 블록을 깊게 쌓는 방식이며, 깊이를 통해 representation power을 증가시켰다.
- 더욱 넓은 네트워크 : Inception 등으로 대표되며 “분할-변환-병합” 을 통해 블록을 형성하며, 낮은 이론적 복잡성으로도 강력한 정확도를 달성하였다.
Inception과 같은 형태의 모듈 블럭은 계산 복잡성은 낮으나 복잡하고 다양한 요소를 설정해야한다. Filter 수와 크기는 각 개별 conv에 맞게 조정되고 모듈의 하이퍼파라미터도 사용자가 정의한다. 섬세하게 조합하면 뛰어난 신경망 설계할 수 있으나 일반적으로 새로운 데이터셋에 맞게 조정하는 명확한 방법은 없다.

ResNeXt는 VGG/ResNet의 레이어 반복 구조를 채택하는 동시에, Inception의 “분할-변환-병합” 구조를 쉽고 확장 가능한 방식으로 응용하는 간단한 아키텍처이다.
Inception-ResNet 모듈과 유사해보일 수 있다. 다만 모든 경로가 동일한 topology를 공유하므로 조합해야할 요소를 줄였다는 점에서 Inception 모듈과 다르다. 또한 cardinality라는 새로운 하이퍼파라미터를 통해 width와 depth의 차원 외에도 구체적이고 측정 가능한 새로운 차원을 활용한다.
뉴런의 재해석
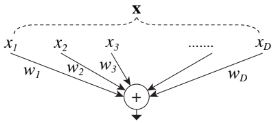
FC 레이어와 Conv 레이어에 의해 수행되는 기본 변환은 내적이다. D 채널의 입력 벡터와 가중치의 내적은 아래 식으로 표현 할 수 있다. 위 그림은 내적을 “분할-변환-병합” 구조로 재구성한 모식도이다.

이를 바탕으로 “변환”(w)을 다른 방식으로 대체하는 것을 고려하였다. 깊이의 차원을 증가시키는 "Network-in-Network"와 대조적으로, 뉴런을 분할하여 새로운 차원을 따라 확장하는 "Network-in-Neuron" 구조를 선택하였다.
C (Cardinality)

Cardinality는 입력 차원 D와 유사한 위치에 있지만 C는 D와 같을 필요는 없으며 임의의 숫자이다. T라는 “변환”을 정의하고 이는 bottleneck 구조를 띄고 있다. 모듈은 T가 D개로 이루어져 있으며, 모든 “변환” T는 동일한 topology를 공유한다. 즉, Cardinality는 모듈 내 T의 개수이며, width, depth 차원보다 효과적으로 동작하는 새로운 차원으로 해석 할 수 있다.
“분할”은 입력 채널을 그룹으로 나눌 때 grouped convolution 레이어에 의해 수행된다. 성능 평가에 사용된 모듈은 입력 채널과 출력 채널이 4차원인 32개의 컨볼루션 그룹을 형성하며, Grouped conv 레이어는 이를 레이어의 출력으로 연결시켜준다. 추가로 깊이가 3 이상인 경우에만 topology를 생성할 수 있다.

Architecture

ResNeXt는 Residual block의 stack 구조다. 블록은 동일한 topology를 가지며 VGG/ResNet에서 영감을 받은 두 가지 간단한 규칙으로 설계되었다. 이 두 가지 규칙은 일부 핵심 요소(하이퍼파라미터)에만 집중할 수 있게 해준다.
- 동일한 크기의 공간 맵을 생성하는 경우 블록은 동일한 하이퍼파라미터(Dk or filter 수 등등)을 공유한다.
- Feature map이 2배로 down sampling될 때마다 Depth는 2배로 곱해진다.
추가로 down sampling은 각 단계 별 첫 번째 블록의 3×3 레이어에서 stride-2 를 통해 수행된다. 또한 conv 레이어 직후에 batch normalization 과 ReLU가 함께 수행된다.
Capacity

파라미터와 연산 수는 모델의 capacity을 나타낸다고 볼 수 있다. 다양한 Cardinality를 평가할 때 capacity의 왜곡을 피하기 위해 다른 하이퍼파라미터의 수정은 최소화할 필요가 있다.
C 와 함께 조정해야하는 하이퍼파리미터는 bottlleneck 레이어의 Depth인 d 로, C 가 작을 때 d도 작으면 블록의 입력이 출력으로부터 격리되어 버린다. 이 외의 다른 레이의 depth나 입출력의 크기 등은 변경되지 않았다. 이에 따른 파라미터 수는 아래와 같다.

결과

평가는 기본적으로 동일한 층의 ResNet과 ResNeXt를 비교한다. ResNeXt는 ResNet보다 훈련 오류가 훨씬 낮으며 이는 더 강력한 표현력 덕분이라고 판단된다. 또한 ResNet-101의 경우에도 유사한 경향이 관찰된다. 또한 아키텍처의 depth를 유지하면서 C 가 1에서 32로 증가하면 오류율이 계속 감소하는 것을 관찰할 수 있다.
Cardinality vs Deeper/Wider
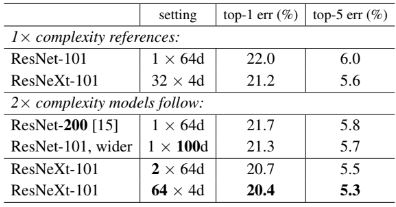
차원 별 성능을 비교하기 위해 세 가지 모델의 성능을 비교한다.
- 200개 레이어까지 더 깊어진 모델.
- Bottleneck 레이어의 depth를 늘린 모델.
- C 를 두 배로 늘린 모델.
32×4d ResNet-101 모델이 더 깊은 ResNet-200 및 더 넓은 ResNet 101보다 성능이 더 우수하다는 것을 관찰할 수 있다. 이는 cardinarlity가 depth와 width의 차원보다 더 효과적인 차원이라는 것을 의미한다..
Residual

ResNeXt 과 ResNet에서 skip connection을 제거하면 두 아키텍처 모두 오류가 증가한다. 이는 skip connection이 존재에 따라 두 모델의 성능 차이가 변하지 않고, 꾸준히 ResNeXt의 성능이 좋다는 점을 시사한다.
표 5. 다양한 모델과의 비교. 동일한 성능에도 하이퍼파라미터가 적다는 장점이 존재.
추가 실험

다양한 모델과 ResNeXt의 비교. 동일한 성능에도 하이퍼파라미터가 적다는 장점이 존재한다.

- 큰 데이터셋 : 5K ImageNet에서 더 좋은 성능 개선이 보이며 더 어려운 classification이라는 점을 고려할 때 유망한 결과로 볼 수 있다.
- 작은 데이터셋 : CIFAR-10에서도 동일하게 C 를 늘리는 것이 width를 넓히는 것보다 효과적임을 확인할 수 있다.
- Object Detection : Faster R-CNN에 ResNet/ResNeXt를 base network로 사용하여 평가를 진행했으며 ImageNet-1K에서 pretrained 한 파라미터를 사용하여 평가를 진행하였다. 여전히 ResNeXt의 성능이 더 좋았으며, MasK R-CNN 에 사용하면 SOTA를 달성하였다는 결과도 존재한다.
Reference
논문 링크 : https://arxiv.org/abs/1611.05431
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] Train-test resolution discrepancy (0) | 2024.08.22 |
|---|---|
| [Classification] EfficientNet (0) | 2024.08.17 |
| [Classification] Xception (0) | 2024.08.10 |
| [Classification] MobileNet (0) | 2024.08.08 |
| [Classification] SqueezeNet (0) | 2024.08.06 |