키워드
1. 훈련과 테스트 단계에서 이미지 해상도가 다른 경우의 문제를 해결하는 방법을 제안.
2. "Fixing the train-test resolution discrepancy" (2019)*
3. Augmentation. resolution, Frechect distribution
시작하기 앞서 필자는 "discrepancy"를 정합성, "apparent object size"를 "절대 객체 크기" 라는 용어로 해석하였다. 정확한 한글 해석이 존재하지 않는 단어인듯 하며 어울리는 단어도 마땅히 생각나지 않는다. 영어 그 자체로 표현하는 것이 좋지만 이해하는 과정에서 한글이 함께 병행되는 것인 개인적으로 편하여 활용하였으니 참고 바란다.
Data Augmentation
Data Augmentation은 classification을 위한 신경망 훈련의 핵심 중 하나이다. 일반적인 augmentation에는 random-size crop, 좌우 반전 color jitter 등이 있으며, 테스트 시에도 데이터 augmentation을 결합하면 정확도가 향상되는 효과도 있다. 즉, 모델 일반화를 개선하고 과적합을 줄이기 위해 주로 사용되며, 이 중 많이 활용되는 random-size crop에 대해 추가로 알아보자.
Random-size crop은 한 이미지에서 임의의 좌표가 있는 직사각형으로 여러 이미지를 추출하는 것이다. 학습 이미지 추출시에는 분류 RoC라고 불리는 크기로 다수의 영역의 조정되며, 모델에 제공되는 고정 크기로 crop되어 학습을 위한 이미지를 얻는다. 테스트시에는 RoC는 대신 이미지의 중앙 영역의 사각형으로 설정되는 "CenterCrop" 방식으로 이미지가 추출된다.
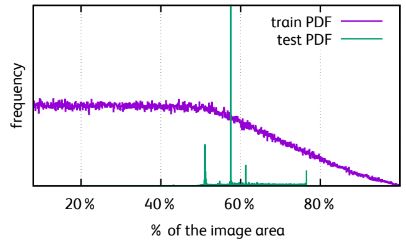
이러한 augmentation 방식은 훈련나 테스트 여부에 따라 classifier가 보는 객체의 크기간 정합성(discrepancy)을 낮춘다. 그 이유는 훈련과 테스트에 추출된 patch가 이미지 기준으로 동일한 크기를 가지지만, 서로 다른 RoC에서 발생하므로 CNN이 보는 데이터의 분포가 왜곡되기 때문이다. 이에 동일한 RoC 샘플링을 유지하면서 훈련 혹은 테스트 시 resolution 및 scale 선정을 공동으로 최적화하여 이 문제를 해결하고자 한다.
결과적으로, 훈련 시 낮은 resolution의 patch를 활용하면 테스트 시 정확도가 향상되었다. 이를 통해 작은 훈련 이미지를 사용하여 강력한 classifier를 훈련할 수 있으므로 훈련 시간이 크게 단축된다. 또한 메모리 소비도 크게 줄여주며 GPU 메모리를 절약할 수 있다.

Random-size Crop의 영향성
절대 (apparent) 객체 크기
객체 인식을 위해 scale-invariant하게 동작하려면 데이터에서 이를 학습해야한다. 다만 입력 이미지의 크기를 조정하면 개체의 분포가 변경된다. 절대(apparent) 객체 크기는 이미지에 투영된 객체의 실제(actual) 크기를 의미하여, 이미지의 크기가 조정되면 절대 크기가 변경된다는 것을 의미한다.
카메라는 3D 세계를 2D 이미지에 투영하므로 객체의 절대 크기는 카메라로부터의 거리에 반비례하다. 3D 객체를 카메라로부터 거리 Z만큼 떨어져있으며 카메라의 초점 거리를 f로 가정하자. 객체를 높이와 너비가 R × R인 정사각형으로 모델링하면 절대 크기 r은 r = f * R/Z 으로 수식화 할 수 있다. R과 Z은 카메라 설정에 따라 변화되는 요소가 아니므로 R/Z를 r1로 치환하면, r = f * r1로 단순화 시킬 수 있다.
이미지의 크기가 H x W 이며 카메라의 화각을 θ로 두면, f = k√HW 이며 가장 일반적인 40~60도 화각에서 k = 1/(2*tan(θ/2)) 로 상수 1로 취급할 수 있다. 이 수식을 토대로 절대 크기 r을 구할 수 있다.
이미지 전처리로 인한 분포 변화
전처리 과정에서 scaling의 영향을 계산해보자. 객체의 범위가 r × r 픽셀이고 s가 입력 이미지와 잘린 이미지 사이의 비율인 경우 새로운 이미지에서 객체의 크기는 rs * rs가 된다. 여기서 s는 훈련과 테스트에서 서로 다르게 표준화 될 수 있다. 먼저 훈련 경우를 살펴보자.

훈련 시 RoC를 기준으로 먼저 영역이 정해지고 해당 영역에서 훈련에 사용될 이미지를 자른다. 이에 HRoC, WRoC는 무작위로 선택된 RoC 의 크기이며, Ktrain은 훈련에 사용되는 크기이다. 이 두 비율을 scale 파라미터 σ를 사용하여 표준화 할 수 있다. Aspect ratio에 대한 파라미터도 추가되어야 하지만, 1로 가정하고 제외하였다. 이를 통해 훈련 시 절대 크기 r이 변화한다는 것을 확인할 수 있고, 네트워크에는 기본적으로 scale invariant하지 않기 때문에 변화한다는 것은 중요하다.
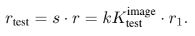
테스트는 임의의 RoC를 사용하지 않고 CenterCrop을 사용한다. 훈련과 동일하게 입력 이미지가 정사각형(H = W)이라는 가정하에 s 는 위 수식과 같다. 이를 통해 동일한 객체를 포함하는 한 입력 이미지에서 훈련과 테스트에 각각 처리되는 전처리 다르면 서로 다른 절대 크기가 발생하는 것을 확인할 수 있다. 실제로 AlexNet에서 σ의 범위는 [0.28, 1]으로 테스트 시 동일한 개체가 훈련에 나타나는 것의 1/3만큼 작게 나타날 수도 있었다.
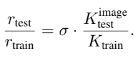
Acitivation
전처리는 CNN의 activation 통계에도 영향을 미친다. 일반적으로 classification을 위한 네트워크는 고정된 크기의 벡터를 pooling layer를 의해 생성하며 완료된다. Crop을 통해 크기를 변경하면 이 레이어의 activation 통계에 큰 영향을 끼친다.
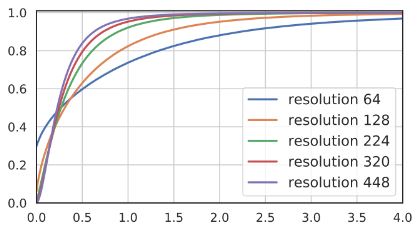
위 그림은 ResNet-50의 average pooling 후 activation의 CDF 플롯이다. Ktrain = Ktest = 224 일때 activation map은 7 x 7 이나, Ktrain = Ktest = 64 일땐 2 x 2 에 불과하다. 여기에 pooling을 취할 경우 0 값만 풀링할 가능성이 더 높으며, 분산은 훨씬 커지게 된다. 이는 해상도를 높이게 되면 반대의 효과가 나온다.
테스트 이미지 크기

Patch의 크기를 늘리는 것이 activation에 긍정적인 영향을 미친다는 점을 바탕으로 서로 다른 Ktest 결과를 확인해보면 정확성에도 긍정적인 영향을 준다. 이는 훈련-테스트 간 개체의 크기 불일치가 줄어들기 때문이라고 볼 수 있으며, 훈련보다 테스트에 더 높은 resolution의 patch를 사용하면 성능이 개선된다.
방법
Crop 크기를 조정
단순히 Ktest만 증가시키고 Ktrain은 고정시키는 방법은 이상적이지 않다. 그 이유는 객체의 더 작은 부분만 보는것과 동일하기 때문이다. 이에 Ktest는 증가시키되 Ktest/Ktrain 은 일정하게 유지하는 것이 필요하며, 이는 Ktest가 항상 Ktrain 보다 크다는 것과 동일하다.
Parametric adaption (Frechect distribution)
모델의 마지막 conv 레이어의 출력은 가우스 분포로 근사될 수 있다. 이후 ReLU를 통과하며 음수를 0으로 대체하고, average pooling을 통해 해당 분포를 합산한다. 이 과정에서 avg pool은 n = 2 × 2에서 n = 14 × 14를 합산하며, 입력의 독립성을 가정하면 n’은 discrete binomial 분포를 따르는 cropped Gaussian의 합이다. 실험적으로 출력 분포가 극단값 분포에 가깝다는 것을 알 수 있으며, 이는 Gaussian의 양의 부분만 출력 값에 영향을 미치기 때문이다.

이를 바탕으로 위 수식과 같이 Frechect 분포를 모델링 할 수 있다. Ktrain=Ktest 에서 파라미터 µref와 σref를 계산하며, 타겟 Ktest 에 맞춰 파라미터 µ와 σ를 측정한다. 이후 스칼라 변환을 통한 새 분포에서 이전 분포로의 equalization maping을 정의하고 이를 pooling 뒤에 activation 함수로 적용한다. 다만 정확도 향상은 다소 제한적이다
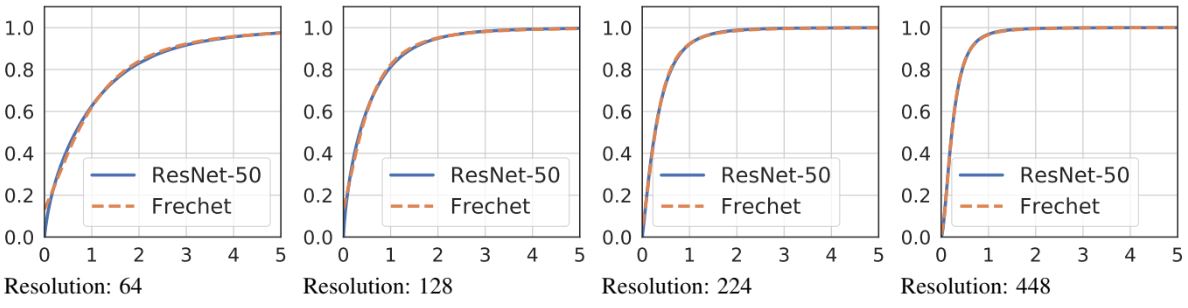
CDF에서 실제와 모델링된 분포 간 곡선의 차이가 매우 정확하다는 것을 알 수 있다. 또한 분포가 resolution에 따라 다르다는 점도 주목할만 하다. Resolution이 높을수록 평균은 0에 가까워지고 분산은 작아지는 경향을 보인다.
이외에도 ReLU 이전의 분포에 영향을 줌으로써 average pooling의 값에 영향을 미치는 것도 가능하다. Frechect 모델에 기반한 방법으로는 불가능하며, 학습 시의 분포에 테스트 분포를 맞추는 방향으로 변형하였다. 다만 아래 기술할 fine-tuning이 훨씬 효과적인 방법임을 확인하였다.
Fine-tuning
테스트 resolution을 키우는 것은 domain shift와 동일하다. 이러한 변화를 보상하는 자연스러운 방법은 모델을 fine-tuning하는 것이다. Ktrain = Ktest 학습 시 활용했던 동일한 훈련 세트를 타겟 resolution에서 재사용하여 fine-tuning하며, 이 과정에서 네트워크의 마지막 레이어만 학습되게 제한한다.
아래 이미지는 fine-tuning 후 activation으로 train(ref)에 매우 유사한 수치가 나온 것을 알 수 있다. 이는 adaptation이 성공했음을 암시하나, 정확도가 향상되는 효과를 가져오지는 않는다.

결과
새로운 아키텍처를 설계하는 목적이 아니기에 이전에 좋은 성능을 보인 여러 아키텍처에서 실험을 진행하였다. 또한 fine-tuning을 위한 data augmentation은 아래와 같은 방법으로 진행되었다.
- test DA (ResNet, PNASNet) : CenterCrop.
- test DA2 (ResNeXt) : 임의 수평 이동 된 CenterCrop 좌우 반전 및 color jittering..
- train DA : Random-size crop, 좌우 반전 및 color jittering.

ResNet

효과를 확인하기 위한 기본적인 실험은 adaption 없이 resolution을 높이는 것이다. 왼쪽 그래프에서 테스트 시 resolution를 높이면 모든 네트워크의 정확도가 높아지는 것을 알수 있다. Fine-tuning을 진행한 후 오른쪽 그래프를 참고하면, fine-tuning이 없었을때보다 전체적으로 성능도 더 좋으며, 테스트 resolution도 더 높다는 것을 알 수 있다.
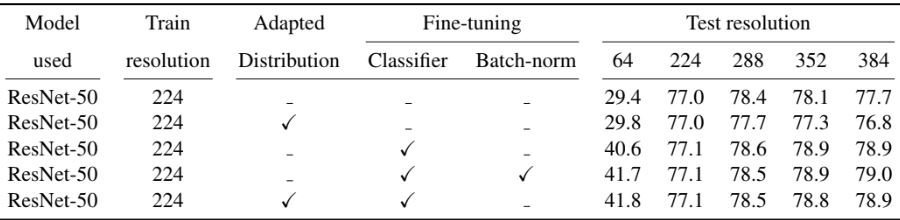
PNASNet, ResNeXt
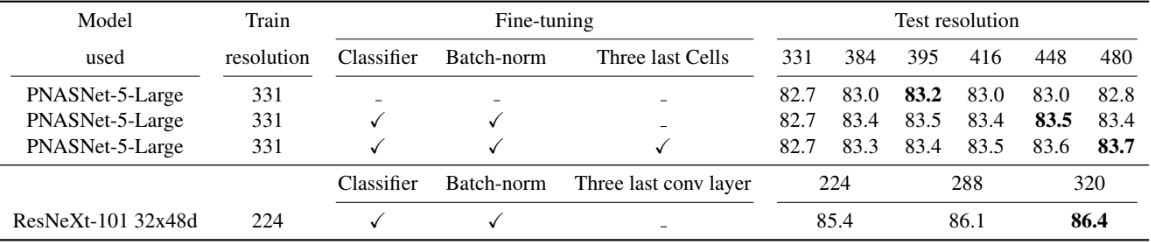
동일한 adaption 방법을 다른 conv 네트워크에 적용할 수 있다. 위 표는 그 결과이며, Batch norm 및 classifier를 fine-tuning하는 것이 유리하다는 것을 알 수 있다. 평가하지 않은 다른 모델과 성능 비교는 아래 표를 참고하면 된다.
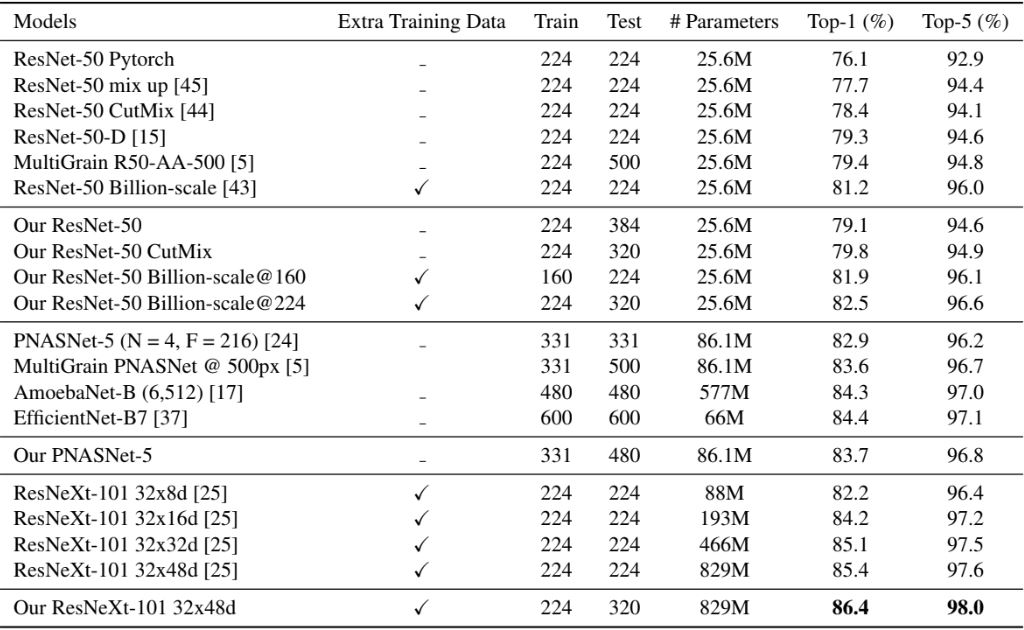
속도 vs 정확도

위 표는 1개의 GPU에서 실행 환경의 훈련 시간과 정확도이다. Fine-tuning은 속도와 정확도 사이의 균형을 맞출 수 있다. 그 이유는 초기 전체 레이어를 학습할때는 작은 resolution의 이미지를 활용하기 때문이다. 또한 이후 fine-tuning 단계에선 훈련보다 적은 메모리를 사용하므로 더 큰 배치 크기를 사용할 수 있다.
Transfer Learning

ImageNet이 아닌 다른 데이터셋에 대한 효율성을 검증하기 위해 transfer learning에서 동일한 방법을 평가했다. ImageNet에서 학습된 가중치로 네트워크를 초기화하고, 특정 resolution에서 모든 레이어를 훈련한 뒤, 마지막으로 BN과 FC 레이어를 더 높은 resolution 에서 fine-tuning하였다. 결과를 통해 모든 데이터셋에서 성능 개선을 확인하였으며, 일부는 SOTA를 달성하기도 했다.
Reference
논문 링크 : https://arxiv.org/abs/1906.06423
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] DeiT (0) | 2024.08.29 |
|---|---|
| [Classification] RegNet (0) | 2024.08.24 |
| [Classification] EfficientNet (0) | 2024.08.17 |
| [Classification] ResNeXt (0) | 2024.08.15 |
| [Classification] Xception (0) | 2024.08.10 |