키워드
1. 네트워크 design space를 체계적으로 탐색하여 다양한 크기와 성능 요구 사항에 맞는 효율적인 모델을 찾는 방법을 제안.
2. "RegNet: Designing Network Design Spaces" (2020)
3. RegNet, AnyNet, Design space, Designe space Design
Network Architecture Search
초기 CNN 구조의 발전은 깊이의 증가, 넓이의 증가 등 새로운 구조를 통해 성능을 개선해왔다. 하지만 구조가 점점 고도화됨에 따라 선정해야하는 하이퍼파라미터 수가 증가하며, 잘 최적화된 네트워크를 수동으로 찾는 것은 점점 어려워 지고 있다. 이에 주목을 받고 있는 분야는 Network Architecture Search(NAS)이다.
NAS는 일종의 검색 알고리즘으로, 고정되고 수동으로 설계된 design space 내에서 자동으로 최상의 네트워크 인스턴스를 효율적으로 찾는 데 중점을 둔다. 다만 이렇게 찾아낸 검색 결과는 특정 설정(예: 하드웨어 플랫폼)에 맞춰 조정된 단일 네트워크 인스턴스라는 한계가 있다. 이에 design space에 대한 수동적인 설계와 NAS의 장점을 결합한 새로운 네트워크 설계 패러다임이 개발되었다.
기본적인 전략은 품질을 유지하거나 향상시키면서, 초기의 비교적 제약이 없는 design space의 간단한 네트워크를 search하고, 이 네트워크를 파라미터화하는 네트워크 design space를 설계하여 최적화된 네트워크를 디자인하는 것이다. 이를 통해 네트워크 설계에 대한 이해를 높이고 설정 전반에 걸쳐 일반화되는 설계 원칙을 발견할 수 있다.
AnyNet이라고 부르는 상대적으로 제약이 없는 설계 공간으로 시작하여, RegNet이라고 하는 간단하고 일반적인 네트워크로 구성된 저차원 design space에 도달한다. RegNet design space는 너비와 깊이가 양자화된(quantized) 선형 함수로 설명되며, 여러 FLOPS에서 잘 작동하는 간단하고 빠른 네트워크를 제공한다.
이를 통해 NAS 검색 알고리즘의 효율성을 향상시킬 수 있으며 design space를 풍부하게 하여 더 나은 모델의 존재로 이어질 수도 있다. 또한 저차원의 간단한 모델로 동일한 성능에서 빠른 속도를 보이기도 한다.
Design space 디자인
Design space
기본적인 방향성은 가장 좋은 단일 모델을 찾는 것보다, 전체 모델 모집단에 적용하고 개선할 수 있는 일반적인 설계 원리를 발견하는 것이다. 이를 위해 Network Design space라는 개념을 사용한다. 이러한 방식은 거의 무한한 모델의 집단을 형성하여 적절한 설계를 할 수 있게 도움을 줄 것이다.
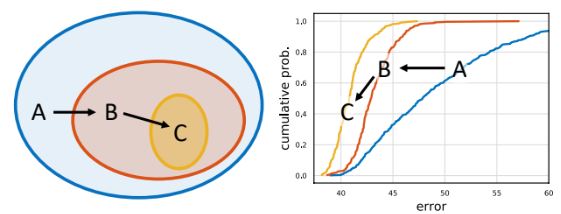
Search 과정에서 초기 design space에서 구한 출력은 이후 design space에서 더 간단하거나 더 나은 모델의 design space를 구할 수 있다. 모델을 샘플링하고 오류 분포를 검사하여 최적의 새로운 design space을 구할 수 있다. 위 그림에서는 초기 design space A에서 시작하여 두 가지 구체화 단계를 적용하여 design space B, C를 산출하는 예시다.
Design space 디자인 도구
Design space의 분석 방법은 n개의 모델을 샘플링하고 학습한 뒤 모든 모델의 오류 분포(error distribution)를 특성화하여 정량화하는 것이다. 샘플링된 모델의 분포를 비교하는 것이 search를 통해 확인 된 모델을 비교하는 것보다 더 강력한 효과를 보인다. 이러한 방식은 수많은 연산량을 요구할 것처럼 보일 수 있으나, 초기 design space에선 FLOP이 적은 모델을 사용하여 100개 모델을 훈련하는 것은 FLOP 기준 단일 ResNet-50을 훈련하는 것과 대략 동일하다.

Design space을 분석하기 위한 기본 도구는 error Empirical Distribution Function (EDF)이다. 왼쪽이 500개의 샘플 모델에 대한 오류 EDF이다. 중앙과 오른쪽는 복잡한 고차원 공간의 임의 1D를 투영한 차트이며, Design space에 대한 통찰력을 얻는 데 도움을 준다. 이러한 방식으로 이후 훈련된 모델 집단이 주어지면 다양한 네트워크 속성과 네트워크 오류를 plot 하고 분석할 예정이다.
AnyNet Design space
AnyNet이라는 이름의 초기 design space를 살펴보자. AnyNet의 목적은 네트워크의 구조를 탐색하는 것이며, 네트워크 구조에는 블록 수(즉, 네트워크 깊이), 블록 폭(즉, 채널 수) 및 Bottleneck 비율이나 그룹 폭과 같은 네트워크와 관련된 여러 하이퍼파라미터가 포함된다.

위 이미지는 AnyNet design space의 네트워크 기본 디자인이다. 입력 이미지가 주어지면 네트워크는 간단한 stem, 대량의 계산을 수행하는 네트워크 body, 출력 클래스를 예측하는 최종 네트워크 head로 구성된다. 네트워크 계산 및 정확성을 결정하는 데 핵심이 되는 네트워크 body의 구조에 중점을 둔다.
네트워크 body는 4단계의 stage로 구성 되며 각 stage의 입력은 점진적으로 해상도가 감소된다. 각 stage는 일련의 동일한 block으로 구성되며, 각 stage i에 대한 자유도에는 black 수 di, block 너비 wi 및 기타 block의 파라미터가 포함된다. 이러한 AnyNet design space에서 가능한 네트워크의 수는 매우 방대하다.

AnyNet은 group convolution이 있는 residual bottleneck block을 사용한다. X block이라고 하며, 최종적으로 AnyNetX design space는 각 네트워크가 4개의 stage로 구성되고 각 stage i가 4개의 파라미터(block 수 di, block 너비 wi, bottleneck ratio bi, group 너비 gi)를 갖기 때문에 16개의 자유도로 이루어진다. 이를 바탕으로 design space를 이해하고 개선하는 데 도움이 될 수 있는 일반적인 설계 원칙이 있는지 탐구한다. 탐구 과정의 각 단계에서 목표는 다음과 같습니다.
- Design space의 구조를 단순화
- Design space의 해석성을 향상
- Design space 품질을 개선하거나 유지
- Design space에서 모델 다양성을 유지
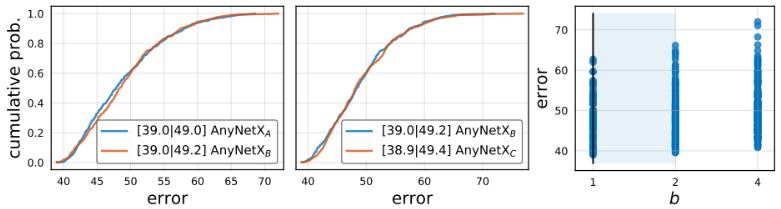
AnyNetXA. 제약이 없는 초기 AnyNetX design space간을 AnyNetXA라고 한다.
AnyNetXB. AnyNetXA의 모든 stage i에 대해 동일한 bottleneck 비율 bi = b로 적용한 design space이다. 동일하게 500개의 모델을 샘플링하고 학습한 뒤, 테스트 결과 확인 시 AnyNetXA 및 AnyNetXB의 EDF는 거의 동일하다. bi에 따라 정확도가 손실되지 않는 해석이 가능하다.
AnyNetXC. AnyNetXB에서 동일한 group 너비 gi = g를 적용한 design space이다. 마찬가지로 EDF는 거의 변경되지 않는다. 이 과정을 통해 AnyNetXC는 AnyNetXA보다 자유도가 6배 적고 design space 크기를 거의 4배 정도 줄였다.

AnyNetXD. 위 그림의 윗줄은 AnyNetXC에서 결과가 좋은 네트워크, 아랫줄은 결과가 안좋은 네트워크이다. 이를 통해 좋은 네트워크일수록 너비가 증가한다는 것을 알 수 있다. wi+1 ≥ wi라는 제약 조건을 설정한 design space가 AnyNetXD이며, 동일하게 테스트한 결과를 보면 EDF가 크게 향상된 것을 알 수 있다.
AnyNetXE. i에 따라 stage 폭이 증가하는 것 외에도 stage 깊이 di도 최상의 모델에 대해 증가하는 경향이 있다. di+1 ≥ di을 설정하여 design space AnyNetXE를 정의하고, 테스트 결과를 보면 AnyNetXD 수준의 결과를 확인할 수 있다.

RegNet Design space

모델 구조에 대한 이해를 위해 AnyNetXE의 최고 20개 모델을 단일 플롯으로 표시했다. 각 모델에 대해 모든 block j의 깊이에 따른 block당 너비 wj를 plot하였다. 개별 모델(회색 곡선)에는 상당한 차이가 있지만 전체적으로는 패턴이 일치한 것을 확인할 수 있다. 또한 wj = 48·(j+1)의 검은색 곡선을 참고하면 상위 모델의 네트워크 너비 증가에 대한 깊이에 선형성이 있음을 알 수 있다. 유사한 패턴이 개별 모델에 적용되는지 확인하려면 각 선을 piecewise-constant function로 양자화가 필요하다. 아래는 block 너비 uj에 대한 linear parameterization의 수식(좌)이다.

깊이 d, 초기 너비 w0 > 0, 기울기 wa > 0의 세 가지 파라미터가 있으며, 각 block j < d에 대해 서로 다른 블록 너비 uj를 생성한다. 이후 양자화위한 추가 파라미터 wm > 0를 활용(우)한다. uj를 양자화하기 위해 sj를 반올림하고 양자화된 block 별 너비 wj를 계산한다. 이를 AnyNetX의 모델을 피팅하여 이 parameterization를 테스트한다. 특히 모델이 주어지면 d를 네트워크 깊이로 설정하고 예측된 block당 너비의 mean log-ratio(efit)를 최소화하는 w0, wa 및 wm에 대한 grid search를 수행한다.

AnyNetXE의 두 상위 네트워크에 대한 결과이다. 양자화된 선형 fitting(점선)은 최상의 모델(실선)에 잘 맞는다. 또한 efit은 AnyNetXC에서 AnyNetXE로 갈수록 향상되며, linear parameterization가 자연스럽게 wi 및 di 증가에 관련 제약 조건을 적용한다는 것으로 알수 있다.
각 design space에서 가장 좋은 모델은 모두 선형 적합도가 좋다. 이에 선형 구조를 가진 모델만 포함하는 design space를 설계할 수 있으며, d, w0, wa, wm(및 b, g)의 6개 파라미터를 가지는 네트워크 구조를 얻는다. 이렇게 얻은 design space는 simple하고 regular한 모델만 포함하므로 RegNet이라고 부른다.

RegNetX의 EDF를 보면, RegNetX의 모델은 최상의 모델을 유지하면서 AnyNetX보다 더 나은 평균 오류를 보인다는 것을 알 수 있다. 이렇게 RegNetX를 설계하면서 원래 AnyNetX 설계 공간의 크기를 16차원에서 6차원으로 줄였으며 크기도 거의 10배로 줄였다. 그러나 여전히 RegNet에는 다양한 설정에 맞게 조정할 수 있는 매우 다양한 모델이 포함되어 있다.

위 그래프를 보면 모든 경우에 디자인 공간의 순서는 RegNetX > AnyNetXE > AnyNetXA로 일관된다. 이러한 결과는 RegNet이 새로운 설정에도 일반화될 수 있음을 보여준다. 이는 단일 환경에 대한 design space를 디자인하는 것이 아니라, 새로운 환경에 일반화할 수 있는 네트워크 디자인의 일반 원리라고 볼 수 있다.

RegNetX (Architecture)
RegNetX design space을 추가로 분석하는 과정에서 좋은 모델이 집중되어 있으므로 더 적은 수의 모델(100개)을 샘플링하고 더 오랫동안(25개 에포크) 훈련하도록 전환할 수 있다. 이러한 추가 분석에서 간단한 모델로 뛰어난 성능을 얻을 수 있다.

먼저 파라미터 별 trend를 확인해보자. 최고 성능 모델의 깊이는 최적의 깊이가 20 block(60개 레이어) 수준이며, 더 높은 FLOP을 위해 더 깊은 모델을 사용하는 일반적인 확장과는 대조적인 결과를 보인다. 또한 최고 모델은 bottleneck 비율 b를 1로 사용했다. 폭 증가폭 wm이 ~2.5 수준이라는 것을 관찰할 수 있다. 이는 단계에 걸쳐 폭을 두 배로 늘리는 흔한 방법과 유사하다.

이후 네트워크 activation 검토한 결과이다. Activation을 검토하는 이유는 메모리 기반 가속기(GPU, TPU)를 사용하기 때문에, activation의 영향이 가장 크다고 볼 수 있기 때문이다. 최고의 모델의 경우 activation은 FLOP의 제곱근에 따라 증가하고, 파라미터 수는 선형적으로 증가한다. 실행 시간은 이에 선형 항과 제곱근 항의 합으로 모델링된다.

앞선 내용으로 RegNetX 추가로 개선한다. b = 1, d ≤ 40, wm ≥ 2로 설정하였다. 또한 activation과 parameter를 제한한다. 이를 통해 정확 정확도에 영향을 주지 않으며 빠르고, 파라미터가 적고, 메모리가 적은 이상적인 모델이 생성된다. 이러한 제약 조건을 사용하여 RegNetX를 테스트한 결과를 보면, 제한된 버전이 모든 FLOP에서 우수하다는 것을 관찰할 수 있다.
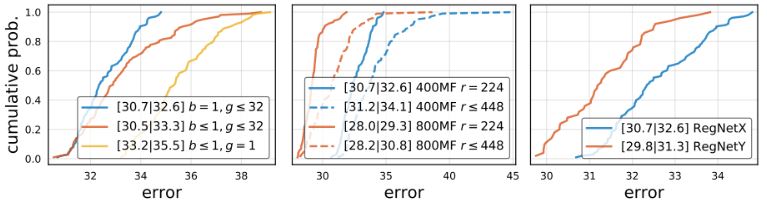
모바일용 네트워크는 종종 bottleneck ratio : b < 를 사용. 다만 EDF에선 성능을 저하시키며 b = 1 및 g ≥ 1의 성능이 더 좋다는 것을 알 수 있다. 또한 입력 이미지 해상도를 조정하는 것이 도움이 될 수 있다는 결과(관련 내용)가 있으며 이에 다양한 해상도를 테스트합니다.다만 결과는 고정 해상도가 더 좋다. 마지막으로 Squeeze-and-Excitation 연산을 추가한 RegNetY도 함께 활용할 예정이다.

결과
모바일

모바일 용 네트워크는 FLOP 0.6B 의 가벼운 네트워크를 의미한다. 위 표에서 RegNet 다른 네트워크와 동등 수준의 성능을 확인할 수 있다. 이는 대부분의 모바일 네트워크와 달리 RegNet 모델은 다양한 regularization 없이 100 epoch 수준의 학습으로 동등 성능을 보였다는 점에서 주목할 만 하다.
ResNet, ResNeXt

위 표는 RegNet 모델이 네트워크 구조만 최적화함으로써 모든 complexity 관련 지표에서 상당한 개선을 제공한다는 것을 알 수 있습니다. 열악한 컴퓨팅 환경을 포함하여 광범위한 컴퓨팅 환경에서 좋은 RegNet 모델을 사용할 수 있다고 볼 수 있다. 즉, 고정된 추론 또는 훈련 시간, 예산을 고려할 때 매우 효과적이다.
EfficientNet

EfficientNet과 비교 시, 적은 FLOP에서는 EfficientNet 이 RegNetY보다 성능이 뛰어나다. 다만 중간 수준의 FLOP에서는 RegNetY 가 성능이 뛰어나고, 큰 FLOP에서는 RegNetX 와 RegNetY 모두 더 나은 성능을 보인다. 또한 EfficientNet 의 경우 activation이 FLOP에 선형적 증가된다. 이에 GPU 훈련 및 추론 시간이 느려지는 부효과도 존재한다.
Reference
논문 링크 : https://arxiv.org/abs/2003.13678
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] DeiT (0) | 2024.08.29 |
|---|---|
| [Classification] Train-test resolution discrepancy (0) | 2024.08.22 |
| [Classification] EfficientNet (0) | 2024.08.17 |
| [Classification] ResNeXt (0) | 2024.08.15 |
| [Classification] Xception (0) | 2024.08.10 |