키워드
1. 네트워크의 크기를 균형 있게 조절하여 성능을 최적화.
2. "EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks" (2019)
3. EfficientNet, Scaling Dimension, Compound coefficient
ConvNets Scale Up
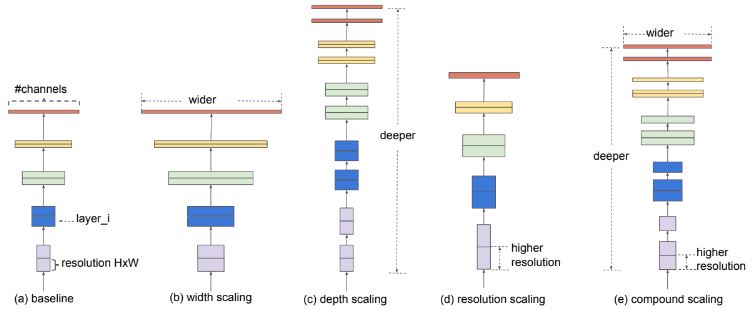
CNN은 모델을 확장하는 과정에 있어 정확도, 효율성의 측면을 모두 고려해야한다. 다만 초기의 모델은 대부분 더 나은 정확도를 달성하기 위해 다양한 방법으로 확장되어 왔다. 주로 깊이, 너비, 이미지 해상도의 세 가지 차원 중 하나만 크기를 조정하는 것이 일반적이며, 2차원 또는 3차원을 임의로 확장하는 것이 가능하지만 최적 조건을 찾기 위한 탐색 과정에 리소스가 굉장히 많이 투입되어야 한다.
이에 모델 확장하는 과정에서 깊이, 너비 및 해상도의 균형을 적절히 유지하면 더 나은 성능을 얻을 수는 방법이 필요하게 되었다. “ConvNet을 확장하는 원칙적인 방법”는 존재하지 않는다. 다만 경험적으로 각 차원을 일정한 비율로 간단히 확장함으로써 더 좋은 성능을 얻을 수 있었다.
EfficientNet은 복합 계수를 사용하여 깊이/너비/해상도의 모든 차원을 적절하게 제어하는 새로운 스케일링 방법을 토대로 설계되었다. 입력 이미지가 더 크면 receptive field를 늘리기 위해 네트워크에 더 많은 레이어가 필요하고, 더 큰 이미지에서 더 세밀한 패턴을 캡처하기 위해 더 많은 채널이 필요하기 때문에 상호 차원간 적정한 비율로 스케일링 되도록 하는 방법이다. 특히, base network에 따라 그 계수 및 효율성이 크게 달라진다.
Convolution의 공식화
ConvNet 레이어 i는 Yi = Fi(Xi) 로 정의될 수 있다. 여기서 Fi는 연산자, Yi는 출력 tensor, Xi는 입력 tensor, tensor 형태는 Hi, Wi, Ci 이다. 모델 안에서 ConvNet 레이어는 여러 단계로 분할되는 경우가 많으며, 대부분의 레이어는 동일한 아키텍처를 공유한다. 따라서 ConvNet을 다음과 같이 정의할 수 있다.
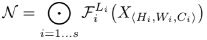
스케일링은 미리 정의된 Fi를 변경하지 않고 네트워크 길이(Li), 너비(Ci) 및/또는 해상도(Hi, Wi)를 확장하는 것이다. 이 과정에서 주어진 리소스 조건 내에 모델 정확도를 최대화 해야한다. 아래는 이를 수식으로 표현한 내용이며, w, d, r은 네트워크 폭, 깊이 및 해상도를 조정하기 위한 계수이다.

Scaling Dimension

폭, 깊이, 해상도가 더 큰 네트워크 일수록 더 높은 정확도를 달성하는 경향이 있지만, 80% 수준에 도달하면 포화되는 경향을 보인다. 이는 단일 차원 스케일링의 한계를 보여준다. 또한 폭, 깊이, 해상도는 독립적이지 않은 동시에 각기 다른 제약 조건에 따라 값이 조정된다.
- 깊이(d) : 더 깊은 ConvNet이 더 풍부하고 복잡한 feature를 포착하고 새로운 작업에 대해 잘 일반화한다. 다만 Gradient Vanishing 문제로 인해 훈련하기가 더 어려우며, skip connection, batch normalization 등의 기법으로 이를 완화하면 매우 깊은 네트워크에선 정확도가 감소하는 경향이 있다.
- 너비(w) : 더 넓은 네트워크는 더 세분화된 feature를 포착할 수 있고 훈련하기 더 쉬운 경향이 있다. 다만 넓지만 얕은 네트워크는 더 높은 수준의 feature를 포착하는 데 어려움을 겪는다.
- 해상도(r) : 해상도가 높을수록 정확도가 향상되지만 매우 높은 해상도에서는 포화되어 증가하지 않는다.
복합 Scaling
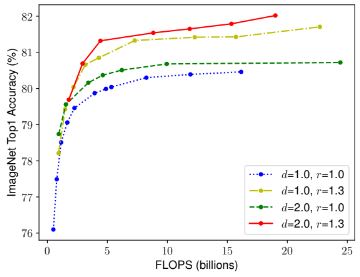
각 scaling dimension(d,w,r)이 독립적이지 않다는 것을 경험적으로 알 수 있다. 이에 따라 복합적으로 dimension을 변경하며 영향성을 확인하였다. 깊이(d=1.0)와 해상도(r=1.0)를 변경하지 않고 네트워크 너비 w만 조정하면 정확도가 빠르게 포화되나, 더 깊은(d=2.0) 그리고 더 높은 해상도(r=2.0)를 통한 너비 스케일링은 동일한 FLOPS 비용으로 훨씬 더 나은 정확도를 달성했다.
Compound coefficient Φ, α, β, γ
복합 계수 Φ 및 α, β, γ를 사용한 새로운 복합 스케일링 방법을 고안하였다. Φ는 모델 확장에 사용할 수 있는 추가 리소스 수이며, α, β, γ는 추가 리소스를 네트워크 너비, 깊이 및 해상도에 각각 할당하는 비율이며 작은 그리드 검색으로 결정할 수 있는 상수다. 확장으로 인한 총 FLOPS가 대략적으로 (α · β^2 · γ^2)^Φ 만큼 증가한다.

Architectrue
기존 ConvNet을 사용하여 확장하는 것도 가능하지만, 모바일 크기의 EfficientNet이라는 새로운 아키텍처도 고안하였다. 정확성과 FLOPS를 모두 최적화하기 위한 ACC(m)×[F LOP S(m)/T]^w를 최적화 목표로 사용하여 모델을 구현하였다. 여기서 ACC(m)과 FLOP S(m)은 모델 m의 정확도와 FLOPS를 나타내고, T는 목표 FLOPS이고 w=-0.07은 정확도와 FLOPS 사이의 균형을 제어하기 위한 하이퍼파라미터이다.
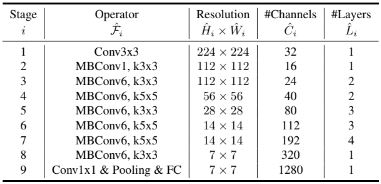
위 테이블이 baseline이 될 EfficientNet-B0이다. 주요 빌딩 블록은 MBConv이며 여기에 squeeze-and-excitation optimization을 추가하였다. 이후 Compound scaling method를 적용하여 아래 두 단계 거쳐 여러 모델로 확장한다. 또한 더 큰 모델에는 더 많은 regularization가 필요하다는 것이 일반적으로 알려져 있으며, 이에 모델이 확장 됨에 따라 선형적으로 증가시켰다. EfficientNet-B0의 경우 0.2이며 B7의 경우 0.5가 사용되었다.
- 먼저 사용 가능한 리소스가 두 배 더 많다고 가정하여 Φ = 1로 고정하고, α, β, γ의 작은 그리드 검색을 수행한다. 평가를 위한 모델의 경우, 최상의 값은 α · β2 · γ2 ≒ 2 라는 제약 조건 하에서 α = 1.2, β = 1.1, γ = 1.15로 계산되었다.
- α, β, γ를 상수로 고정하고 방정식을 사용하여 서로 다른 Φ로 baseline 네트워크를 여러 네트워크로 확장한다.
결과
MobileNet 및 ResNet의 확장
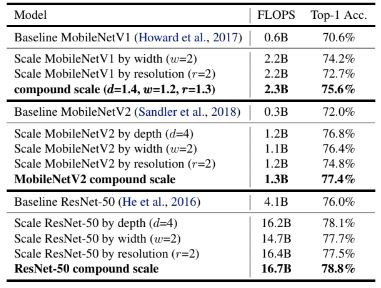
MobileNet에 확장 방법을 적용한 결과이다. 다른 단일 차원 scaling 방법과 비교하여 compound scaling 방법은 모델의 정확도를 향상시키며, 실험한 모든 ConvNet 모델에 대해 효율성을 확인하였다.
EfficientNet에 대한 결과
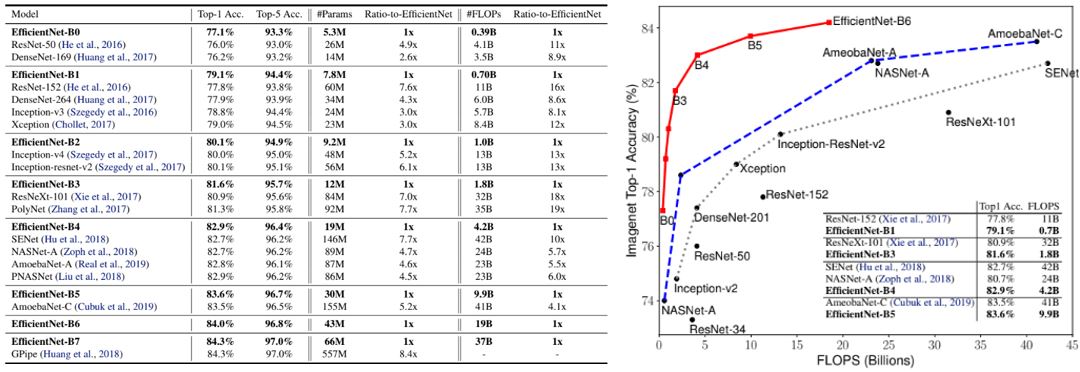
EfficientNet 모델들은 일반적으로 유사한 정확도를 가진 다른 ConvNet보다 훨씬 적은 수의 파라미터와 FLOPS를 사용한다. 이는 EfficientNet이 크게 최적화된 더 나은 아키텍처를 사용하며, 더 나은 확장성 및 더 나은 학습 설정에서 비롯된다고 볼 수 있다. 오른쪽 차트에서 확장된 EfficientNet 모델과 다른 ConvNet의 FLOPS에 따른 정확도를 볼 수 있다. EfficientNet 모델은 작을 뿐만 아니라 계산 비용도 저렴하다는 것을 알 수 있다.

Latency(지연 시간)을 검증하기 위해 표에 표시된 대로 실제 CPU에서 추론 시간도 측정했다. 20회 실행에 대한 평균 대기 시간 결과이며, EfficientNet이 실제로 빠르다는 것을 시사한다.
EfficieNet과 다른 transfer learning model 비교 결과
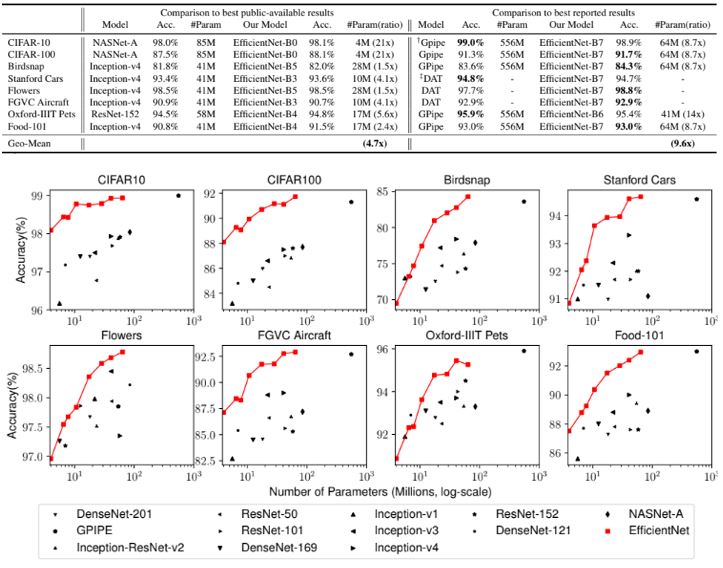
일반적으로 사용되는 전이 학습 데이터 세트 목록에서 EfficientNet을 평가
ImageNet의 사전 훈련된 체크포인트를 사용하고 새로운 데이터 세트를 미세 조정
EfficientNet 모델은 8개 데이터세트 중 5개에서 여전히 정확도를 능가하지만 9.6배 더 적은 매개변수를 사용
다양한 확장 방법에 대한 실험
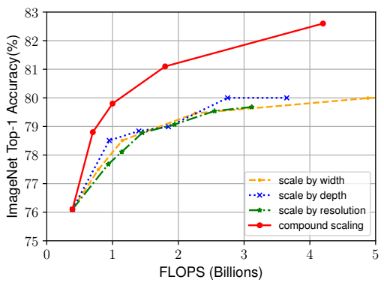
EfficientNet-B0를 서로 다른 방법으로 확장한 모델 간의 결과 비교이다. Compount scaling 방법은 다른 단일 차원 scaling 방법보다 최대 2.5%까지 정확도를 더 향상시킬 수 있어 매우 유용한 방법임을 다시 확인 할 수 있다.
Class Activation Map (CAM)

그림에서 볼 수 있듯이 Compound Scaling을 사용하는 모델은 더 많은 객체 세부 정보를 포함하여 관련 영역에 더 집중하는 경향이 있는 반면, 다른 모델은 객체 세부 정보가 부족하거나 이미지의 모든 객체를 캡처할 수 없습니다.
Reference
논문 링크 : https://arxiv.org/abs/1905.11946
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] RegNet (0) | 2024.08.24 |
|---|---|
| [Classification] Train-test resolution discrepancy (0) | 2024.08.22 |
| [Classification] ResNeXt (0) | 2024.08.15 |
| [Classification] Xception (0) | 2024.08.10 |
| [Classification] MobileNet (0) | 2024.08.08 |