키워드
1. Transformer 모델을 이미지 분류에 적용하여 기존 CNN 모델과 경쟁할 수 있는 성능을 보임. 이 모델은 특히 데이터 효율성이 높은 점이 특징.
2. "DeiT: Data-efficient Image Transformers" (2021)
3. Transformer, Knowledge distillation, DeiT, ViT
Convolution to Attention
CNN은 거의 10년 동안 아키텍처와 최적화 측면에서 모두 최적화되었다. 자연어에서 attention 기반 모델에서 뛰어난 성능을 보였고, 이를 기반으로 하는 신경망이 이미지 classification과 같은 이미지도 처리하는 것으로 나타났다. 다만 이러한 고성능 vision transformer (ViT)은 수억 개의 데이터로 학습이 필요했으며, 이로 인해 대규모 데이터셋의 필요로 채택이 제한되었다.
이러한 문제를 해결하고자 transformer에 CNN을 이식하는 Data-efficient image Transformer (DeiT) 하이브리드 아키텍처 고안하였다. 주요 핵심은 Transformers 학습을 위한 teacher-student 전략으로, student가 attention을 통해 teacher로부터 학습할 수 있도록 하는 distillation 토큰에 사용한다. Self-attention 메커니즘을 포함하여 convNet과 transformer를 결합한 하이브리드 아키텍처는 Classification 뿐만 아니라, object detection, video 처리, unsupervised detection까지 다양한 분야에서 뛰어난 성능을 보인다.

Attention을 통한 distillation
Knowledge distillation
Knowledge distillation(KD)은 student 모델이 teacher 네트워크에서 나오는 "soft" 라벨을 활용하는 교육 방식이다. 정답만 제공되는 "hard" 라벨이 아닌 teacher의 softmax 출력 벡터를 활용하는 것이다. 이러한 훈련 방식은 학생 모델의 성능을 향상시키며, 다른 의미로 teacher 모델을 더 작은 모델인 student로 압축하는 형태로 간주될 수도 있다. 또한 KD는 teacher 모델을 사용하여 student 모델에서 inductive bias를 전달한다고 볼 수 있다. 이는 ConvNet 모델을 teacher로 사용하여 transformer 모델에게 Convolution으로 인한 bias를 유도하여 유익한 효과를 유도한다.
Multi-head Self Attention layers
Attention은 (key, value) 벡터 쌍이 있는 메모리를 기반으로 학습한다. Query 벡터와 key 벡터를 내적을 사용하여 매칭 시키고, 이후 softmax 함수 및 normalize를 취한 뒤, value에 대해 가중 합을 구한다. 여기서 query는 출력 벡터 로부터 구해진다. 이를 표현한 수식은 아래와 같다.

Self-attention 레이어는 query, key, value 모두가 입력 벡터 시퀀스(X ∈ RN×D로 압축됨)에서 계산되는 메커니즘이다. MSA는 h 개의 attention “head” 가 존재하며, 각 헤드는 N × d 크기의 시퀀스를 제공하고, h 개로 나누어진 입력은 각 헤드를 통과한 후 N × dh 시퀀스로 재배열된다.
이미지 용 transformer
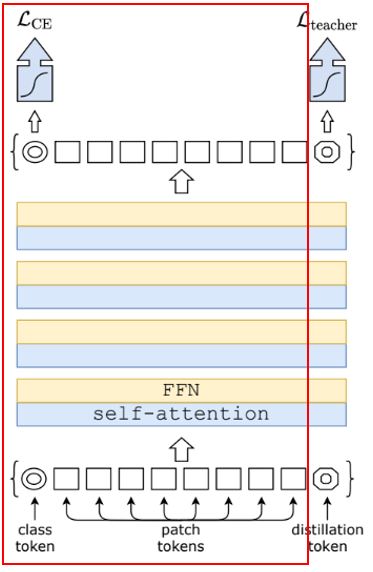
MSA 레이어 위에 FFN(Feed-Forward Network)을 추가한다. 이는 두 개의 linear 레이어로 구성되어있다. 첫 번째 linear 레이어는 차원을 D에서 4D로 확장하고 두 linear 레이어는 차원을 4D에서 다시 D로 줄인다. MSA와 FFN은 모두 skip connection과 layer norm을 통해 residual 동작을 한다.
입력 이미지를 일련의 입력 토큰인 것처럼 처리하는 ViT 모델을 기반으로 동일하게 처리된다. RGB 이미지는 고정 크기 16 × 16 픽셀(N = 14 × 14)의 N 패치 배치로 분해하며, 각 패치는 전체 치수 3 × 16 × 16 = 768을 유지하는 선형 레이어로 투영된다. 또한 다른 transformer 구조와 동일하게, 고정 또는 훈련 가능한 positional embedding(PE)이 패치 단위로 첫 번째 transformer block 앞에 추가된다.
클래스 토큰은 훈련 가능한 벡터로, 패치 토큰에 맨 앞에 추가되어 transformer를 통과여 최종적으로 클래스를 예측하는데 사용된다. 클래스 토큰은 NLP에서 차용되었으며, CNN에서 클래스를 예측하는 데 사용되는 일반적인 pooling 레이어와 다르다. 최종적으로 transformer는 차원 D의 (N + 1)개 토큰 배치를 처리하며, 그 중 클래스 벡터만 클래스를 예측하는 데 사용된다. 이를 통해 self-attention이 패치 토큰과 클래스 토큰 사이에 정보가 확산되도록 강제한다.
추가적으로 해상도에 따라 PE를 수정해야한다. 학습과 테스트 시의 해상도를 다르게 설정하는 것이 유익한 효과를 보인다. 이를 위한 테스트 조정 시 패치 정보가 달라지게 된다. transformer block과 클래스 토큰을 사용하는 아키텍처 특성상, 더 많은 토큰을 처리하기 위해 모델과 classifier를 수정할 필요가 없다. 다만, 각 패치의 PE는 해상도에 맞게 조정이 필요하다.
KD를 위한 teacher 모델
Teacher 모델로 강력한 이미지 classifier를 사용한다. Teacher를 활용하여 transformer를 학습하며, Soft distillation 혹은 Hard distillation을 통해 student를 학습시킬 수 있다.
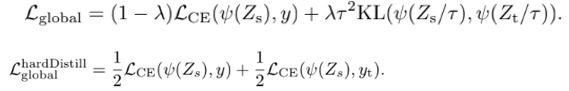
Soft distillation는 Teacher의 softmax와 학생 모델의 softmax 사이의 Kullback-Leibler 발산을 최소화하는 방식이다. 이에 대한 loss는 위와 같다. Hard-label distillation은 yt = argmaxcZt(c)가 teacher의 결정이라고 가정하면, student가 정해진 레이블을 예측하는 Cross-entropy을 최소화하는 방식으로 바뀐다. 이에 따른 loss 또한 계산할 수 있다. 이 과정에서 teacher의 예측 yt는 실제 레이블 y와 동일한 역할을 한다. 또한 하드 레이블은 label smoothing을 사용하여 소프트 레이블로 변환될 수도 있으며, ε 을 사용하여 1-ε 만큼만 예측 레이블을 지정하고 나머지는 ε을 균등하게 배분하는 방식이다.
Distillation 토큰

초기 임베딩에 새로운 토큰인 distillation 토큰을 추가한다. distillation 토큰은 클래스 토큰과 유사하게 사용된다. 즉, 클래스 토큰과 동일하게 self-attention을 통해 다른 임베딩과 상호 작용하고 마지막 레이어 이후 네트워크에 의해 출력된다. Distillation 임베딩을 사용하면 우리 모델은 클래스 임베딩을 보완하면서 고전적인 distillation처럼 Teacher의 출력을 학습한다.
이 과정에서 학습된 클래스와 distillation 토큰이 서로 다른 벡터로 수렴되는 것을 관찰할 수 있다. 각 레이어를 통과하면서 유사성이 높아지지만 초기 임베딩 시 유사성은 굉장히 낮다. 이는 유사하지만 동일하지 않은 타겟을 학습하는 것을 목표로 하기 때문이라고 볼 수 있다. 추가로 두 개의 클래스 토큰을 사용하여 transformer를 실험 했을 때 초기부터 유사한 벡터로 수렴되었고, 추가 클래스 토큰은 성능에 아무런 영향을 주지 않았다. 이를 통해 distillation 토큰이 성능에 영향을 준다는 것을 확인할 수 있다.
Joint classifier
Transformer에 의해 생성된 클래스, distillation 임베딩은 모두 Classifier와 연결되어 있어 레이블을 추론하는데 사용 될 수 있다. 예측을 위해 두 classifier의 softmax 출력을 추가하는 두 개의 개별 head를 구현한 후, 최종적으로 두 출력을 합치고 예측하는데 활용한다.
Architecture
아키텍처 디자인은 ViT와 동일하다. 유일한 차이는 MLP를 linear classifier로 변경한 것, distillation의 활용이다. 이에 ViT-B와 동일한 아키텍처를 갖는 모델을 DeiT-B 로 명명하였고, joint classifier을 사용할 때 DeiT⚗로 명명하였다. 그리고 DeiT를 더 큰 해상도로 fine-tuning할 때 DeiT-B↑384와 같이 최종 해상도를 끝에 추가한다. 마지막으로 DeiT-S와 DeiT-Ti라는 두 개의 작은 모델도 추가로 설계하였으며, d를 고정한 채로 head 수를 변경했다. 아래 표에 통해 자세한 내용이 있다.

Teacher

ConvNet teacher를 사용하는 것이 transformer를 사용하는 것보다 더 나은 성능을 제공한다는 것을 확인했다. 이에 위 표 중 RegNetY-16GF 모델을 teacher 모델로 선정하였다. 또한 distillation된 모델은 정확도와 처리량 간의 균형 측면에서 teacher보다 성능이 뛰어난데, 이는 distillation를 통해 transformer로 상속된 inductive bias 때문일 것이다.
Distillation에 다른 성능 차이
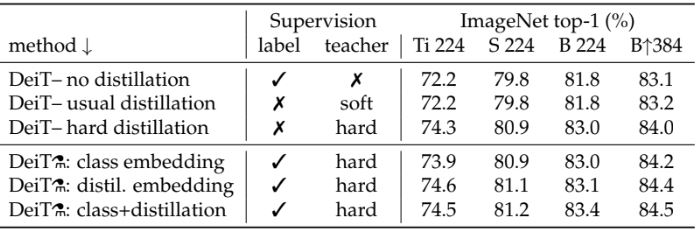
클래스 토큰만 사용하는 경우에도 hard distillation는 soft distillation보다 훨씬 더 성능이 뛰어나다는 것을 확인하였다. 그리고 joint classifier는 성능을 더욱 향상시켜 두 토큰이 classifier로써 상호 보완된다는 것을 보여준다. 그렇다면 이러한 성능 차이는 ConvNet의 inductive bias에 의해 더 많은 이점을 얻기 때문일까?
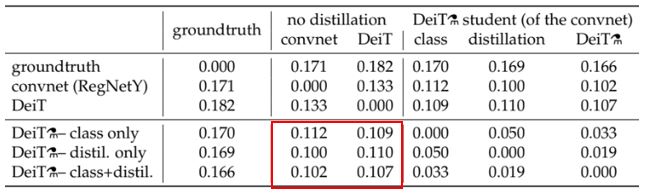
위 표는 각 모델 별로 서로 다르게 분류된 샘플의 비율이다. ConvNet teacher, 클래스만 학습한 이미지 transformer DeiT, distillation이 더해진 transformer DeiT⚗ 간의 추론을 분석하였다. Distillation 임베딩이 학습된 classifier는 클래스 임베딩만 학습된 것보다 ConvNet에 더 가깝고, 반대로 클래스 임베딩만 학습한 classifier는 ConvNet보다 distillation 없이 학습된 DeiT와 더 유사하다. 이를 통해 ConvNet의 inductive bias가 유효한 효과를 보인다고 판단할 수 있다.
Epoch
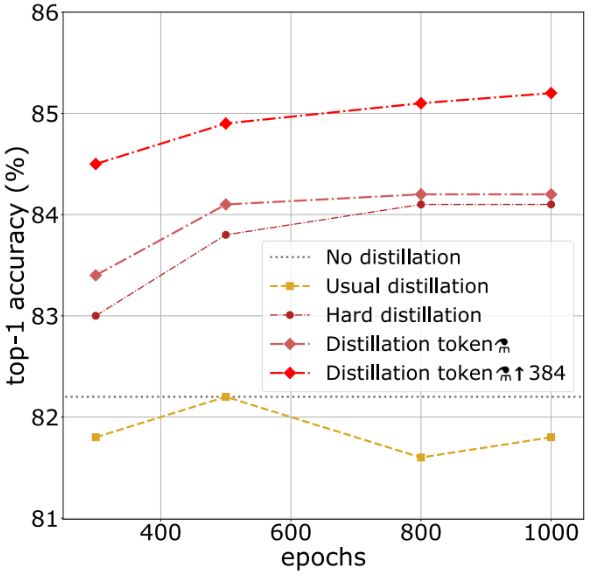
DeiT-B⚗가 DeiT-B보다 성능적인 측면에서 이미 우수하다. 추가적인 이점은 후자의 경우 epoch이 길어지면 성능이 포화되는 반면, distillation된 네트워크는 epoch이 길어져도 학습이 계속 진행된다는 부분도 존재한다.
결과
Efficiency vs Accuarcy
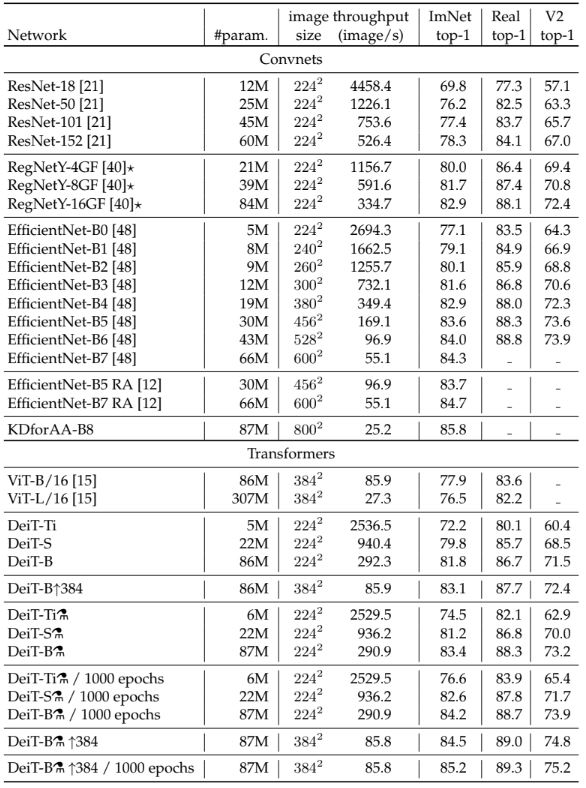
CNN 구조는 Accuracy와 FLOP, 파라미터 수, 네트워크 크기 등과 같은 서로 다른 기준 간의 타협을 이룬다. 이 중 SOTA 모델로 볼 수 있는 EfficientNet Convnet과 비교를 진행했다. DeiT는 EfficientNet보다 성능이 낮으나, 데이터셋이 작은 Imagenet-1K 만으로 교육할 때 기존 ViT와 ConvNet 사이의 격차가 거의 해소했다고 볼 수 있다. 또한 DeiT-B⚗↑384은 EfficientNet보다 성능이 뛰어나다 볼 수 있는데, 정확도와 추론 시간 간의 균형에 있어 어느 정도 SOTA를 달성했다고 볼 수 있다.
Transfer Learning

표 6의 데이터셋에 transfer learning을 수행한 후 이를 평가했다. DeiT는 ImageNet에 대한 결론과 일치하는 ConvNet과 동등 수준의 성능을 달성했다.

Reference
논문 링크 : https://arxiv.org/abs/2012.12877
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] RegNet (0) | 2024.08.24 |
|---|---|
| [Classification] Train-test resolution discrepancy (0) | 2024.08.22 |
| [Classification] EfficientNet (0) | 2024.08.17 |
| [Classification] ResNeXt (0) | 2024.08.15 |
| [Classification] Xception (0) | 2024.08.10 |