
키워드
1. 모바일 장치에서도 효율적으로 동작할 수 있는 경량화된 CNN을 제안.
2. "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications" (2017)
3. MobileNet, Depthwise Separable Convolution, Width multiplier, Resolution multiplier
Accuracy vs Speed

이전의 CNN 발전 방향은 정확성을 향상에 초점이 맞춰져 있다. 이러한 방향성은 크기와 속도 측면에서 네트워크의 효율성을 고려하진 않았다. 하지만 로봇 공학, 자율 주행, 증강 현실 등 다양한 실제 응용 분야는 제한된 플랫폼에서 적시에 수행되어야한다. 이에 소규모 네트워크 아키텍처에 대한 필요성이 증가했다.
관련하여 모바일 및 임베디드 Vision 애플리케이션을 위한 MobileNet이라는 효율적인 모델 클래스를 고안하였다. 이는 가벼운 신경망을 구축하는 간소화된 아키텍처를 기반을 둔다. 추가로 사용자의 애플리케이션에 적합한 크기의 모델을 선택할 수 있는 두 가지 하이퍼파라미터도 사용되었다. 관련된 다른 소규모 네트워크는 보통 크기에만 초점을 맞추고 속도는 고려하지 않았지만, MobileNet은 크기 뿐만이 아닌 응답 속도(latency)에도 초점을 맞췄다.
Depthwise Separable Convolution
MobileNet은 Depthwise separable convolution으로 구성된다. 깊이 방향(Depth)과 이미지 방향(Width*Height)을 분리하여 feature를 추출하는 방법이다. Inception과 유사한 개념으로, 입력을 여러 개의 개별 conv 레이어를 통과시키는 방식으로 네트워크를 구현한다.
Traditional Convolution

Traditional Convolution은 한 단계로 3D 입력에서 3D 출력을 계산한다. 만약 Di x Di x M 크기의 입력을 받고, Di x Di x N 출력을 내보낸다고 가정하자. Kernel의 크기를 Dk라고 했을 때, 파라미터 수는 Dk x Dk x M x N와 같다. 이에 traditional conv는 Di * Di * Dk * Dk * M * N 의 계산 비용이 필요하다.
Depthwise Separable Convolution
Depthwise Separable Convolution은 사용하여 출력 채널 수와 커널 크기 간의 상호 작용을 차단한다. 이를 통해 계산 및 모델 크기를 대폭 줄이는 효과를 가져온다.

기존 conv 와 달리 두 단계로 나누어 계산된다. Depthwise convolution은 각 입력 채널에 단일 filter를 사용한 conv layer이며, Pointwise convolution은 1×1 conv을 적용하여 depthwise convolution의 출력을 입력으로 받아 계산한다. 두 레이어 모두 Batch norm과 ReU를 사용한다.
이에 따른 계산 비용은 Di * Di * Dk * Dk * M (depthwise) + Di * Di * M * N (pointwise) 과 같다. 3 x 3 conv 기준 정확도가 약간 감소하면서 traditional conv보다 8~9배 적은 계산을 사용한다.

Architecture
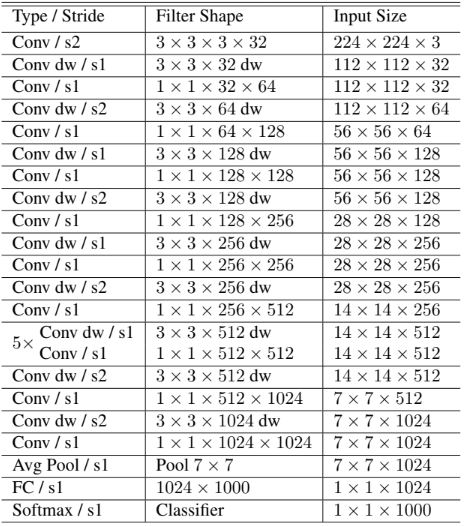
첫 번째 레이어를 제외하고 depthwise separable convolution을 기반으로 설계되었다. 모든 레이어 뒤에는 Batch norm과 ReU를 사용한다. Down sampling은 첫 번째 레이어 및 depthwise convolution에서 스트라이드를 통해 처리된다. 최종적으로 Depthwise convolution과 pointwise convolution을 별도의 레이어로 계산하면 28개의 레이어 존재한다.
작은 모델은 overfitting으로 인한 문제가 적기 때문에 regularization 및 augmentation을 덜 사용한다. 이에, Depthwise convolution filter에 파라미터가 너무 적기 때문에 L2 norm를 작거나 적용하지 않는 것이 중요하다
Resource

단순히 Multi-Add(연산)가 적다는 것으로 네트워크의 연산을 판단하는 것은 잘못되었다. 효율적으로 구현할 수 있는지 확인하는 것도 중요하다. GEMM(General Matrix Multiply)에 매핑하려면 im2col 방식으로 메모리에서 재정렬이 필요하나, 1×1 conv는 메모리에서 이러한 재정렬이 필요하지 않다. MobileNet은 연산 중 95%를 1×1 conv하며 파라미터의 75%도 1x1에 해당하여 매우 효율적이다.
Width multiplier α : 더 얇은 모델
더 작고 계산 비용이 덜 드는 모델을 구성하기 위한 하이퍼 파리미터다. 이를 통해 네트워크의 모든 레이어를 균일하게 얇게 만든다. α에 대해 입력 채널 수 M는 αM이 되고 출력 채널 수 N은 αN으로 계산된다. 계산 비용과 파라미터 수를 대략적으로 α에 제곱 수준으로 줄이는 효과가 있다.
Resolution multiplier ρ : 해상도 감소
입력 이미지에 적용하고 모든 레이어의 내부 feature은 이후 ρ만큼로 감소한다. 이를 통해 계산 비용을 ρ만큼 줄이는 효과가 있다. 최종적으로 아키텍처 축소 방법이 레이어에 순차적으로 적용됨에 따라 레이어에 대한 계산 및 파라미터 수는 아래와 같다.

결과
Traditional Convolution vs Depthwise Separable Convolution

Depthwise Separable Convolution를 사용하면 정확도가 1%만 감소하고 계산 횟수 및 파라미터 수가 엄청나게 절약된다.
Width Shrink vs Depth Shrink

α를 사용하는 더 얇은 모델과 레이어를 줄인 더 얕은 모델을 비교한 결과이다. Shallow 버전은 [14 × 14 × 512] X 5 Depthwise Separable Convolution 를 제거했다. 이를 통해 더 얇게 만드는 것이 더 얕게 만드는 것보다 성능이 좋다는 것을 알 수 있다.
Width & Resolution Multiplier

“MobileNet” 앞 숫자가 α, 뒷 숫자가 ρ이다. α의 ρ 여러 조합으로 이루어진 16개 모델에 대한 accuray와 계산 횟수이며, 성능이 좋고 나쁜 비교로 해석하는 것이 아닌, 각 어플리케이션에 맞춘 최적의 모델 선택 필요하다.

응용 분야

- Fine Grained Recognition - Stanford Dogs 데이터세트에 대한 결과이다.
- Large Scale Geolocalizaton - 지구상에서 어디서 찍혔는지 판단하는 작업을 분류 문제다. MobileNet 버전은 훨씬 더 컴팩트함에도 불구하고 PlaNet에 비해 약간 낮은 성능을 보이며, Im2GPS보다 뛰어난 성능을 보인다.
- Face Attributes - MobileNet과 “Knowledge distillation”간의 시너지 관계를 확인할 수 있다. 라벨링 되지 않은 대규모 데이터셋의 교육을 가능하게 한다. Knowledge distllation 관련 논문 링크
- Object Dectection - MobileNet은 base 네트워크로 훌륭한 성능을 보인다. 실험한 모든 프레임워크에서 MobileNet은 계산 복잡성과 모델 크기를 일부만 사용하여 다른 네트워크와 비슷한 성능을 보인다.
- Face Embeddings - 작은 MobileNet 모델에 대한 결과를 알 수 있다.

Reference
논문 링크 : https://arxiv.org/abs/1704.04861
'딥러닝 > Classification' 카테고리의 다른 글
| [Classification] ResNeXt (0) | 2024.08.15 |
|---|---|
| [Classification] Xception (0) | 2024.08.10 |
| [Classification] SqueezeNet (0) | 2024.08.06 |
| [Classification] DenseNet (0) | 2024.08.03 |
| [Classification] ResNet (0) | 2024.08.01 |