
Linear classification
Linear Classification (선형 분류)는 1강의 k-NN 보다 강력하며, 이후 Neural Network로 확장하게 된다. 원본의 클래스 별 점수(확률)을 구하는 score function / 예측된 점수(확률)와 실제 label 간의 차이를 측정하는 loss function으로 구성된다. 이 두 함수 활용하여 loss function을 최소화하는 방식으로 주어진 문제(Classification)를 최적화한다.
Score function
Pixel의 수치 (즉, 이미지)들을 각 클래스 별 점수(확률)로 변환하는 score function이 처음에 고려해야 할 부분이다.
Linear classifier
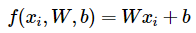
가장 간단함 함수 중 하나인 linear classifier를 score function으로 활용 가능하다. W 는 "weights(가중치)"이며, parameter(파라미터)라고도 한다. 그리고 b 는 "bias(편향)" 라 하며, 데이터 x와 상호 작용하지 않으면서 출력 점수에 영향을 준다. W,b를 통해 계산한 점수(확률)와 실제 레이블과 일치하도록 하는 것이 목적이다.
CIFAR-10 를 예시로 32x32x3의 이미지 데이터를 하나의 열벡터로 변환하여 [3072 x 1] 크기의 x 가 주어진다. W 는 [10 x 3072], b 는 [10 x 1]의 크기를 가지며, 최종 f(x , W, b)는 [10 x 1]로 각 클래스 별 점수를 출력한다. W의 각 행은 각 클래스에 대한 classifer 이며, W * x는 10개 서로 다른 classifier를 하나의 행렬 곱으로 표현했다고 볼 수 있음.
W,b를 통해 새로운 이미지의 레이블을 예측하는 방식이며, training set을 사용하는 k-NN과 다른 방식이다. 그렇기에 속도적인 측면에서 k-NN보다 개선. CNN은 복잡하고 많은 W,b로 이루어진다.
Linear classifier 의 해석
Linear classifier는 모든 픽셀, 채널 값의 가중 합으로 클래스의 점수를 계산한다. W의 값에 따라 특정 위치의 특정 색상에 대해 가중치를 조절할 수 있다. 예를 들어 "배"는 바다에 있기에 파랑에 가중치를 크게, 빨강,초록에 가중치를 작게 줄 것이라 예상할 수 있다. 임의 이미지에서 파랑색 채널의 값이 크고, 다른 채널의 값이 작으면 배의 점수(확률)이 올라가게 된다.

이미지는 고차원 공간의 한 점으로 해석 가능하다. 예시로 CIFAR-10의 각 이미지는 32*32*3 = 3072차원 공간에서 한 점이라고 볼 수 있다. 이와 동일한 방식으로 전체 dataset은 고차원 공간(이미지의 크기)에서 레이블이 존재하는 점(이미지)들의 집합이 된다. 또한 클래스 별 점수는 이미지를 이루고 있는 픽셀 값의 가중 합. 즉, 클래스 별 점수는 dataset이라는 공간 상에서 선형 함수가 된다.
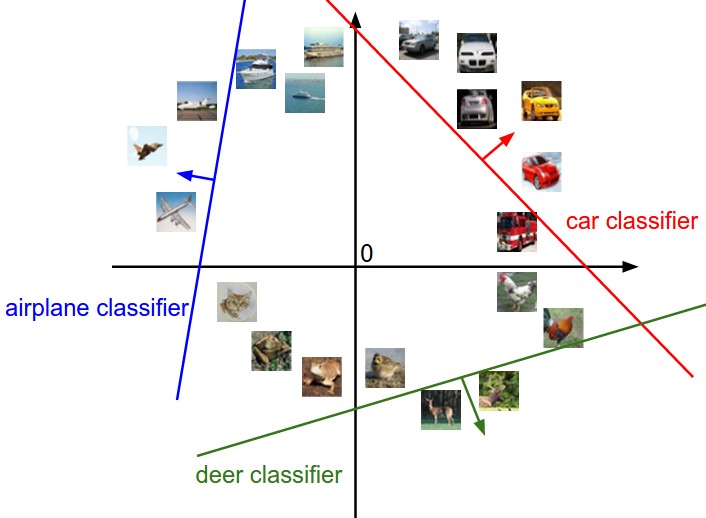
3072차원을 시각화 할 수 없지만, 이를 2차원으로 압축한다고 상상하면 아래 이미지와 같다고 볼 수 있다. 실선은 클래스 점수가 0이 되는 지점. 화살표는 값이 증가하는 방향이다. 이미지는 각 classifier 기반, 전체 클래스 중 가장 점수가 큰 클래스로 예측된다. W를 통해 기울기가 바뀌고, b에 따라 분류기가 이동한다. 만약 b가 없으면 모든 classifier는 0을 통과하여 b는 반드시 필요하다.
Template matching
Template matching도 linear classifer를 해석할 수도 있다. 이는 W의 각 행을 하나의 클래스에 대한 template (혹은 프로토타입) 으로 해석하는 방식이다. 다른 의미론, 이미지를 클래스 별 template에 내적(inner product) 혹은 스칼라 곱(dot product) 하여 점수를 구하는 방식이다. k-NN과 비교하면 이 방식은 거리를 계산함에 있어서 수많은 학습 이미지가 아닌 클래스 별 한 장의 이미지(template)만 필요로 하며, L1, L2 대신 내적을 distance로 사용하게 된다.

위 예시를 더 살펴보면 "말"은 좌우의 머리 방향을 합쳐둔 template으로 볼 수 있으며, "차"는 다양한 방향과 색상을 하나의 template으로 표현했다고 볼 수 있다. 다만 dataset에서 좀 더 많은 예시로 학습이 치우치며, 새로운 이미지를 분류할 정도로 성능이 좋지 않다. 다만 이런 template을 여러 층(layer)으로 결합한 경우 더욱 정확한 점수(확률)을 구할 수 있다. (Neural Networks) Template은 각각 뉴런이 되어 Network를 이루고, 각 뉴런은 template처럼 모든 걸 아우르는 것이 아닌 일부 특징을 학습하고, 이 후 모든 뉴런의 가중 합을 통해 클래스 별 점수를 구한다.
Bias trick
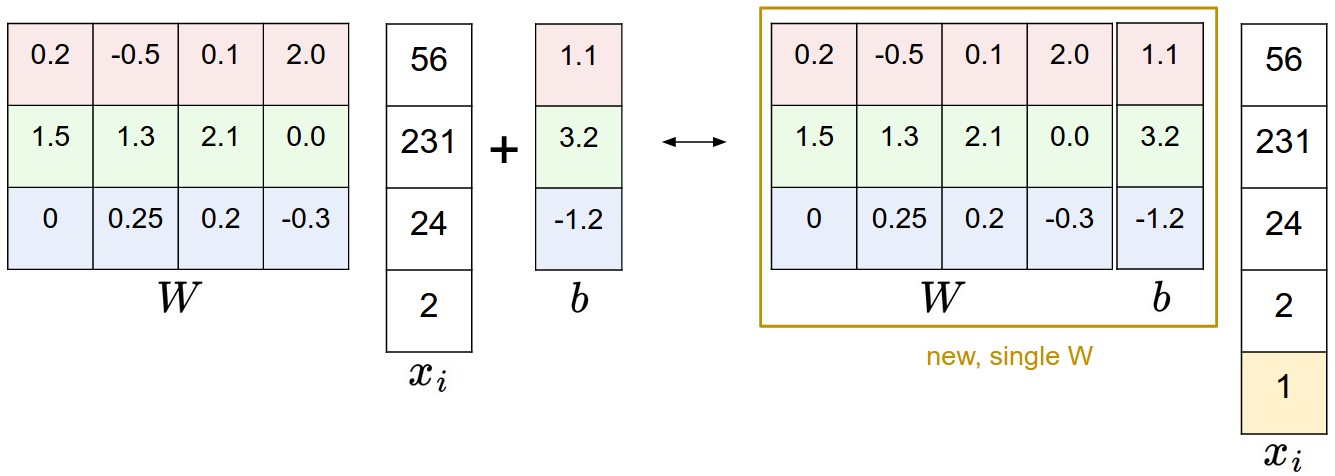
Bias trick이란, W,b를 따로 고려하는 것이 아닌 하나의 행렬로 결합하는 방식이다. Input 벡터 x에 1을 추가로 더하여 bias 차원을 구현. 이는 더욱 간단한 식으로 표현 가능하다. 즉, b가 포함된 단일 W 행렬만 학습하면 된다.

Loss function (손실 함수)
위에서 보았던 예시를 다시 살펴보면, 고양이를 개로 잘못 예측하는 것을 볼 수 있다. 이러한 결과를 수치로 측정한 것이 loss funtion 라고한다. (cost function (비용 함수), objective fuction (목적 함수)라고도 함) Loss function이 높으면 틀린 정도가 큰 것이고, 낮으면 예측을 잘하는 상태로 볼 수 있다.

Support Vector Machine (SVM)
Multiclass Support Vector Machine(SVM) loss는 자주 사용되는 loss function 중 하나다. SVM loss는 이미지 별로 정답 클래스 점수가 다른 오답 클래스의 점수들보다 Δ (마진) 이상이라는 컨셉이다. 아래 공식에서 s는 각 클래스별 점수, yi는 이미지의 정답 클래스를 의미한다. 오답 클래스들의 점수와 정답 클래스의 점수 차이에 Δ를 전체 합한 값이 loss 값이 됨. Δ 이상 차이가 나는 경우는 loss function 에서 제외한다.

예시로 3개의 클래스를 가지는 이미지 분류 모델의 점수가 s = [13,-7,11] , 정답은 첫번째 13, Δ = 10일 때, 아래와 같이 loss 를 계산 할 수 있다.
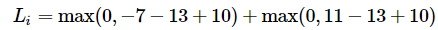
이 중 마진이상의 차이를 보이는 첫 번째 항은 0이 되고, 두 번째 항으로만 loss가 계산됨. 여기서 임계값이 0인 max(0,-) 함수를hinge loss라고 부른다. 더욱 가혹한 페널티를 부과하기 위해 제곱을 취한 squared hinge loss SVM (or L2-SVM)를 사용하는 경우도 있다.
결론적으로 SVM의 목표는 모든 예제에 대해 제약 조건 (항상 Δ 보다 큼)을 동시에 충족하고 전체 손실이 가능한 한 낮은 가중치를 찾는 것이다.

하이퍼 파라미터인 Δ 의 값 설정이 필요하다. 추가로 Δ와 λ는 서로 다른 것처럼 보이지만, 둘 다 tradeoff 인 loss 와 regularzation 사이를 조율한다. λ에 따라 W의 모든 요소가 증가 or 감소하게되고, 이에 따라 점수가 증감하게 된다. 이 과정에서 절대적인 값을 가지는 Δ는 λ에 따라 유의미 할 수도 무의미 할 수도 있다. 이에 Δ 설정만큼 λ의 regularization도 필요하다. (W가 최대로 커지는 정도를 조절)
Binary SVM

Binary SVM에서 C는 Hyperparameter이며, yi는 {-1,1} 중 하나. 클래스가 2개라는 것을 고려하여 공식을 간단하게 표현 가능하다. C는 λ와 동일하게 트레이드 오프이며 서로 반비례 관계에 있다. (C ∝1/λ)
참고) One-Vs-All (OVA) SVM은 클래스 별 독립적인 Binary SVM을 학습시키는 알고리즘이며, 이 외에도 All-vs-All (AVA) 방식도 존재한다. (구글링해보니 이 둘을 합친 OVNNI 라는 알고리즘도 있는듯 하다.. 존재만 확인하고 그 이상은 pass..) 또한 Kernels, Duals, SMO 알고리즘 등등 여러 SVM이 존재. 이들 중 대부분은 미분이 가능하지 않으나, 실제로는 크게 문제되진 않는다.
Softmax classifier

Softmax classifier는 또 다른 loss function 중 하나로, 다중 클래스에 대한 binary Logistic Regression을 활용한다. 직관적인 의미가 담겨있지 않는 점수를 출력하는 SVM과 달리, normalized된 점수(0~1)를 출력하는 방식이다. 이를 확률로써 해석할 수 있으며 SVM보다 훨씬 직관적이다. 기본적인 f(x, W) = W*x 는 동일하나 hinge loss를 cross-entropy loss 로 대체하고, 점수를 log probability로 구한다. log를 취하기전 값을 softmax function이라 하며, 클래스 점수를 0과 1 사이의 값으로 압축하고 합계가 1이 되도록 한다.
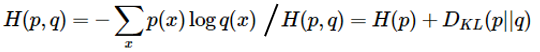
정답 값의 분포 p와 예측 값의 분포 q 사이의 cross-entropy 공식은 위와 같다. 정답의 분포는 p=[0,…1,…,0]로, 정답 클래스인 yi번째 위치에 1이 있는 분포이다. Softmax 는 이 값을 최소화 하고자 한다. 또한 Entropy와 Kullback-Leibler(KL) divergence의 관점에서도 표현 가능하다. H(p)의 Entropy는 0이기 때문에 KL divergence를 최소화 하는 것과 같다.

이미지 x에 대해 정답인 클래스 yi일 확률로 해석될 수 있다. 공식 내 지수 함수는 unnormalized 한 확률을 얻을 수도록 해주며, 나눗셈은 확률의 총합이 1이 되도록 수행한다.

Softmax를 실제로 사용하는 경우 지수 함수로 인해 값이 매우 커질 수 있다. 값이 큰 수는 불안정 할 수 있으며 normalization 이 필요하다. 위와 같이 상수 C를 활용하는 것이 좋다. (최종 값의 변화는 없음) 부가적으로 "softmax loss"는 잘못된 표현. softmax function 과 cross-entropy loss의 조합이기 때문이다.
SVM vs Softmax

동일하게 점수 vector f 를 계산한다. 차이는 SVM은 점수로 그대로 활용, Softmax는 Exp + normalization을 통해 확률로 활용하는 것이다. 위 예시에서 SVM은 1.58, cross-entropy loss는 1.04로 계산되나, 두 값은 다른 해석이 필요하여 비교는 불가능하다. (cross-entropy loss가 더 작기때문에 좋은 모델로 판단은 오류)
두 방법의 차이를 보이는 예시로 f1= [10, -100, -100] , f2= [10, 9, 9]이며 첫번째 클래스가 정답이라고 가정한다. SVM에서 Δ=1 이면 충분히 마진이 있기에 둘 다 loss가 0이 되지만 Softmax에서는 f2에서 더 큰 loss를 가진다. 즉 SVM은 특정 제약 조건까지만 학습, Softmax는 항상 정답을 최대로 오답을 최소로 학습하고자한다. 다만 경험적으론 SVM과 Softmax 간의 성능 차이는 보통 매우 작다.
Regularization
SVM을 포함한 모든 loss function을 구할 때, Regularization을 고려해야 한다. Regularzaition의 필요성을 설명하기 위해, 우선 loss function이 0 이 나오는 완벽한 W가 존재한다고 가정하자. 완벽한 W는 유일하지 않을 수 있다. 예를 들어, 가중치에 동일한 λ(λ>1)를 곱한 λW도 손실이 0이 되나, SVM에서 차이가 커지는 방향이기 때문에 Δ 보다 항상 클 수 밖에 없다.
Regularization loss는 W에 대한 제한을 부여하여 이 모호성을 해결하고자 한다. L2-norm은 큰 가중치를 피하기 위한 regularization이다. (W 행렬을 구성하는 모든 요소의 제곱합) 이를 통해 큰 가중치를 피하게 되면 특정 영역이 점수에 매우 큰 영향을 끼칠 수 있는 것을 방지한다.
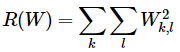
이를 SVM loss 에 추가하면 최종 SVM loss를 구할 수 있다. (N은 훈련 sample 수, λ(가중치)는 하이퍼파라미터) L2를 포함하면 최대 마진 특성(max margin property) 확보 가능하다. 예시로, 입력 x=[1,1,1,1]에 가중치 w1=[1,0,0,0], w2=[0.25,0.25,0.25,0.25]가 있다고 가정하자. 두 가중치 모두 내적 시 1. 하지만 L2는 w1은 1, w2는 0.5 이다. L2를 기반으로 w2로 학습을 진행하게 되고,입력을 골고루 활용할 수 있도록 된다. (일반화 성능 향상)

다만 bias는 input에 영향을 받지 않기 때문에 동일한 효과가 없음. 이에 따로 regularazation을 하지 않다.또한 regularization으로 인해 loss가 0이 되는 것은 불가능하다.
Reference
CS231n 강의 노트 : https://cs231n.github.io/linear-classify/
'딥러닝 > Basic (CS231n)' 카테고리의 다른 글
| [CNN] Neural Network(신경망), Neuron (뉴런), Activation function(활성화 함수) (0) | 2024.05.11 |
|---|---|
| [CNN] Backpropagation(역전파), chain rule (0) | 2024.05.04 |
| [CNN] Optimization (최적화), Gradient(기울기 계산), Learning rate (0) | 2024.04.27 |
| [CNN] Image Classification (이미지 분류), k-NN, Hyperparameter (1) | 2024.04.17 |
| [CNN] CS231n 카테고리를 시작하며 (0) | 2024.04.14 |