
Optimizatin 이란
Image classification은 score function 과 loss function 으로 구성된다. Parameter인 W로 예시 xi의 정답 yi로 정확히 예측(가장 높은 score)하면 손실 L은 작아질 것이다. Optimization은 loss function을 최소화 시키는 W를 찾는 과정이다. 추후 CNN을 구현하는 과정에서 score function은 더욱 복잡한 연산으로 구현될 것이며, loss fucntion, optimization은 그렇지 않을 것이다.
Loss function의 시각화
손실 함수들은 일반적으로 매우 고차원 공간 상에서 정의된다. 예시로 CIFAR-10은 10 X (3072+1) = 30,730의 parameter를 가진 W 활용한다. 이는 30,730 차원의 공간을 만들며, 이 공간에서 각각의 parameter가 loss에 영향을 준다. 이를 전부 활용하기보단, 고차원 공간의 특정 1-dimension 혹은 2-dimension 을 가져옴으로써 어림짐작은 가능하다.
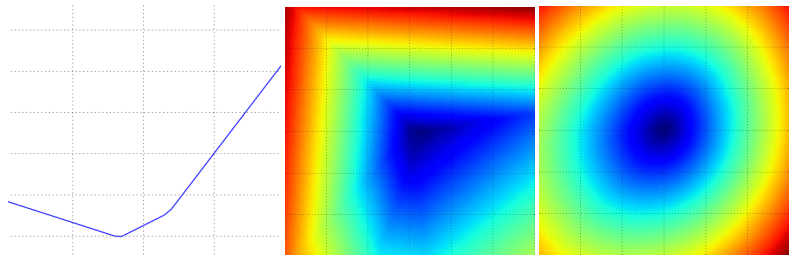
- 1-d 는 왼쪽 이미지 (x : 고차원 공간내 임의 선(1d), y : loss)
- 2-d 는 가운데, 오른쪽 이미지(x : 고차원 공간내 임의 면(2d), color : loss)
- 왼쪽과 가운데는 1개의 sample, 오른쪽은 100개의 sample.
복잡한 Neural Networks (신경망)의 loss에선 단순히 볼록한 것이 아닌, 울퉁불퉁하며 그 굴곡이 불규칙하게 형성된다.
SVM LOSS 시각화
Sample 별 loss는 0을 임계점(threshold)로 둔 W에 대한 선형 방정식들의 합으로 볼 수 있다.3개의 클래스를 가지는 dataset에서 3개의 sample이 주어졌다는 가정으로 전체 SVM loss는 아래처럼 표현 가능하다.
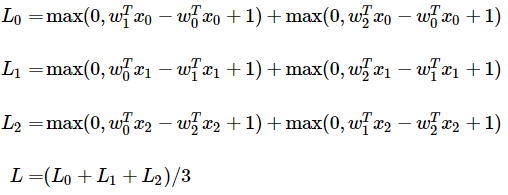

Max를 활용하기 때문 loss function에서 kink가 생기며, 때문에 기울기가 정확히 정의되지 않아 미분 불가능하다.다만 subgradient는 존재하며 이를 통해 미분 값을 구해 활용하다. 이후 gradient라는 표현은 subgradient를 의미한다.

Optimization (최적화)
위에서 언급했듯, Optimization은 loss function을 최소화하는 W를 찾는 것이다. 이를 구현하기 위해 여러 방법이 존재한다. 쉬운 이해를 위해 "눈을 가리고 등산 후 하산하는 등산가"에 비유를 할 수 있다.
방법1) Random Seacrh
좋은 결과가 나올때까지 임의의 W를 반복하는 방법이다. 다만 추천하는 방법은 아니다. 이는 등산가에 비유하기 위해 등산가의 처음 위치를 임의로 지정해야 하는데, 하산을 완료한 등산가가 나올때까지 반복하는것과 동일하다. 위 방법으로 최적의 W를 찾는 것은 불가능한 수준이며며, 새로운 W가 아니라 사용한 W를 조금씩 좋은 쪽으로 수정하는 것은 더 가능성이 있다. 즉, 반복을 통한 개선으로 W를 loss가 더 작은 쪽으로 변화시키며 최적의 W를 찾는다.
방법2) Random Local Search
무작위로 진행 방향을 탐색하고 그 방향의 loss가 더 작다면 W를 수정한다. 이를 수식으로 표현하면 W(기존) + δW (변동치) 와 같다. 눈을 가린 등산가의 목적이 하산이라고 볼 때, 무작위 발걸음이 산을 내려가는 방향이면 걸어가는 방법이다.
방법3) Following teh Gradient
만약 좋은 방향을 알고 있다면 "무작위"는 필요 없다. 가장 가파르게 loss function이 감소하는 방향이 최적의 방향이다. 이는 loss function의 기울기와 같으며, 눈을 가린 등산가가 느끼는 발걸음의 경사도로 비유할 수 있다.
기울기는 특정 지점에서 순간 변화율을 뜻함. 또한 특정 지점이 아닌 전체 공간 및 전체 차원에 대한 기울기(미분값)는 벡터를 의미한다. 1-D 함수에서 특정 지점(입력)에 대한 도함수(derivative)는 아래와 같다.

단일 숫자가 아닌 숫자 벡터를 취할 때, 이 도함수는 편도함수(partial derivatives)라 한다. 기울기는 각 차원 별 편도함수의 벡터다. 최종적으로, "방법3" 을 통해 optimization을 수행한다.
기울기 계산
유한 차분(finite differences)을 사용한 수치적인(numerical) 기울기 계산
느리고, 기울기의 근사치를 사용하나 간단한 방법이다.바로 위에서 본 편도함수를 활용하여 기울기의 값을 계산한다.
함수 f, 기울기를 평가할 벡터 x 를 활용. x에서 f의 기울기를 반환하며, 이때 작은 값의 h를 x에 더해 f의 편도 함수를 계산한다. h가 0에 수렴할 때 정확한 기울기가 정의되지만, 아주 작은 값(1e-5 수준)을 사용해도 충분하다. 추가로 중심 차분 공식 (centered difference formula)을 사용하여 기울기를 계산하는 것이 더 성능이 좋다
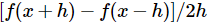
결론적으론 직접 기울기의 수치를 구하는 것은 parameter 수와 연관이 있으며 효율성의 측면에서 좋지 않다. CIFAR-10 dataset 기준으로 각각의 parameter를 업데이트하기 위해 30,731번의 loss function을 계산해야한다. 발전된 Neural Networks에서는 더욱 많은 연산이 필요하며 개선된 방법이 필요하다.
함수의 미분을 통한 기울기를 계산(analytically)
정확한 기울기 값을 활용하지만, 오차가 발생할 수도 있는 미적분을 활용하는 방법이다. 기울기를 계산할 공식을 직접 유도하여 매우 빠르게 계산한다. 다만 값으로 기울기를 직접 계산하는 이전 방식과 달리, 미분을 통한 방식은 오차가 발생할 확률이 있다. 일반적으론 둘 다 계산한 후 서로 비교하여 정확성을 확인한다. 이를 gradient check 이라고 한다. (이후 강의에서 추가 설명), SVM loss function을 예제로 고려해보자.

wyi에 대한 함수로 식을 편미분할 수 있다. (좌하단 식) 여기서 "1"은 참이면 1, 거짓이면 0인 지시 함수(indicator function)이다. 지시 함수를 통해 Δ를 만족하지 않는 클래스의 수를 새고 이 값으로 xi를 조정하여 기울기를 구한다.다만 정확히 맞는 클래스에 대해서만 기울기를 얻을 수 있다 (wyi로 미분했기 때문).
> wj에 대해 (클래스가 틀린 항) 편미분하면 다른 기울기를 구할 수 있다. (우하단 식) 이렇게 직접 식을 유도하여 기울기를 계산 후 그 값을 W 업데이트에 활용할 수 있다. 또한 loss function의 값을 작게 만드는 것이 목적이기 때문에, 기울기는 "-"를 붙혀 활용해야한다.
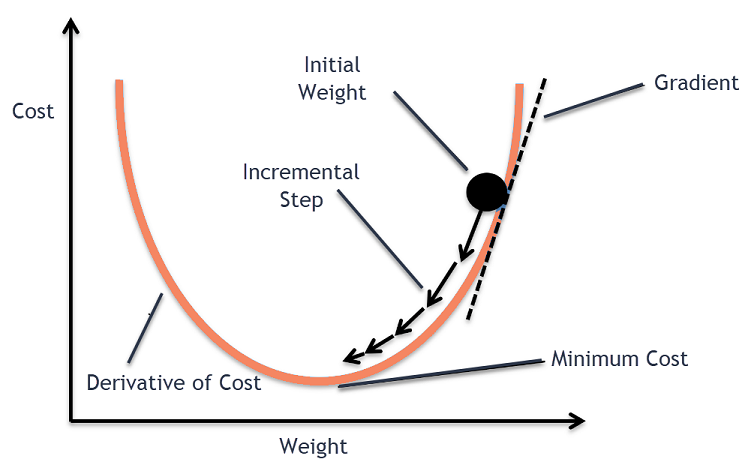
Learning rate
다만 기울기는 loss 가 감소하는 방향만 알려준다. 얼마나 줄여야하는지에 대한 지시는 없다. 줄여 나가야 할 크기를 learning rate라고 부르며 이는 매우 중요한 하이퍼파라미터이다. 작으면 조심스럽고 일관되지만 진전이 매우 작으며, 크면 빠르지만 최소점을 지나치며 오히려 loss가 커질 수 있다.

learning rate의 시각화한 이미지이다. 흰 점이 현재 위치, 화살표가 기울기가 (음으로) 최대인 방향이다. 점섬을 따라 작게 움직이면, 일관된 진행을 보이나 너무 느리며, 점섬을 따라 크게 움직이면, 빠를 수 있으나 오히려 반대로 넘어갈 수 있는 위험이 있다.
Gradient Descent (경사 하강법)
Gradient Descent는 반복하여 기울기를 계산 및 평가하고 매개변수를 업데이트하는 과정을 지칭한다. 현재까지 Neural Networks의 loss function를 최적화하는 가장 흔하고 정형화된 방법이다.
Mini-batch gradient descent
Mini-batch gradient descent은 training data를 batch 단위로 계산하는 방식이다. 크기가 큰 dataset일수록 더욱 효과적이다. 전체의 training set에 대한 loss function을 계산하여 한번만 업데이트하는 것은 낭비가 될 수 있기 때문이다. 예시로 120만 개의 전체 training set이 있을 때 256개의 예제로 배치를 이루어 parameter 업데이트에 사용한다.
이 방식이 동작하는 이유는 training data와 batch내 sample이 상관관계가 있기 때문이다. 상관관계가 있다면 training data 전체를 통해 얻은 loss와 batch로 얻은 loss가 동일할 것이며, 완전히 동일하진 않더라도 활용가능 한 수준의 근사치를 얻을 수 있다.
실제 학습 중 자주 활용되며 훨씬 빠르게 loss가 수렴하게 된다. Mini-batch는 Batch라고 일반적으로 표현된다. Batch의 크기는 하이퍼파라미터이며, 2의 제곱수 (32,64,128...) 이 벡터 연산에서 더 유리하기에 주로 사용된다.
Stochastic Gradient Descent (확률적 경사 하강법)
Stochastic Gradient Descent 은 이 배치에 한 개의 예제만 포함된 경우다. 한 예제의 기울기를 100번 계산하는 것(SGD)보다 100개의 예제에 대한 기울기를 평가(Mini-batch)하는 것이 계산상 훨씬 효율적일 수 있기 때문에 흔하게 사용되는 방식은 아니다. 이에 mini-batch gradient descent를 그냥 SGD라고 표현하는 경우도 있다.
Reference
CS231n 강의 노트 : https://cs231n.github.io/optimization-1/
'딥러닝 > Basic (CS231n)' 카테고리의 다른 글
| [CNN] Neural Network(신경망), Neuron (뉴런), Activation function(활성화 함수) (0) | 2024.05.11 |
|---|---|
| [CNN] Backpropagation(역전파), chain rule (0) | 2024.05.04 |
| [CNN] Linear classification (SVM, Softmax) (2) | 2024.04.20 |
| [CNN] Image Classification (이미지 분류), k-NN, Hyperparameter (1) | 2024.04.17 |
| [CNN] CS231n 카테고리를 시작하며 (0) | 2024.04.14 |